
Erin Grant
@eringrant.me
5.3K followers
1.3K following
30 posts
Senior Research Fellow @ ucl.ac.uk/gatsby & sainsburywellcome.org
{learning, representations, structure} in 🧠💭🤖
my work 🤓: eringrant.github.io
not active: sigmoid.social/@eringrant @[email protected], twitter.com/ermgrant @ermgrant
Posts
Media
Videos
Starter Packs

Erin Grant
@eringrant.me
· 5d
Erin Grant
@eringrant.me
· 15d

Reposted by Erin Grant

Jacob Zavatone-Veth
@jzv.bsky.social
· Sep 4
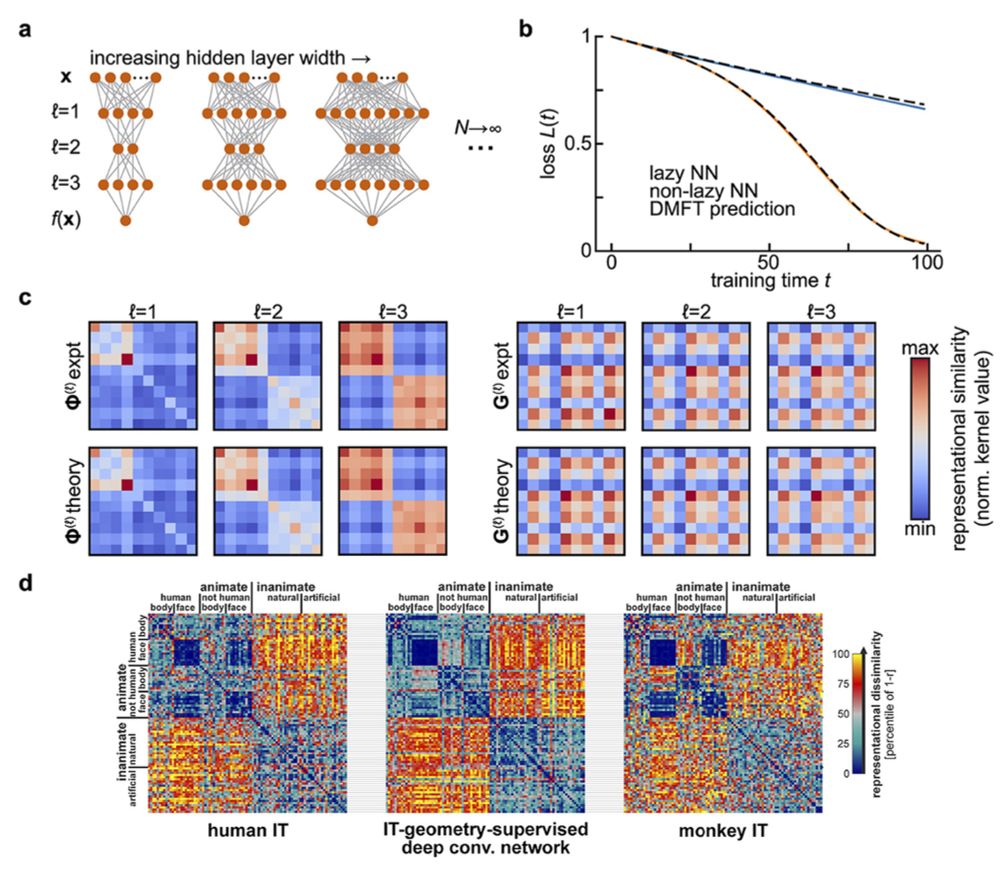
Frontiers | Summary statistics of learning link changing neural representations to behavior
How can we make sense of large-scale recordings of neural activity across learning? Theories of neural network learning with their origins in statistical phy...
www.frontiersin.org
Reposted by Erin Grant
Erin Grant
@eringrant.me
· Aug 19

Reposted by Erin Grant


Reposted by Erin Grant


Erin Grant
@eringrant.me
· Aug 13
Erin Grant
@eringrant.me
· Aug 13
Erin Grant
@eringrant.me
· Aug 13
Erin Grant
@eringrant.me
· Aug 13





Erin Grant
@eringrant.me
· Aug 13
Erin Grant
@eringrant.me
· Aug 13
Erin Grant
@eringrant.me
· Aug 13

Erin Grant
@eringrant.me
· Aug 13

