Greg Durrett
@gregdnlp.bsky.social
2.6K followers
410 following
19 posts
CS professor at NYU. Large language models and NLP. he/him
Posts
Media
Videos
Starter Packs
Reposted by Greg Durrett



Reposted by Greg Durrett




Reposted by Greg Durrett





Reposted by Greg Durrett

Reposted by Greg Durrett

David Hall
@dlwh.bsky.social
· May 19

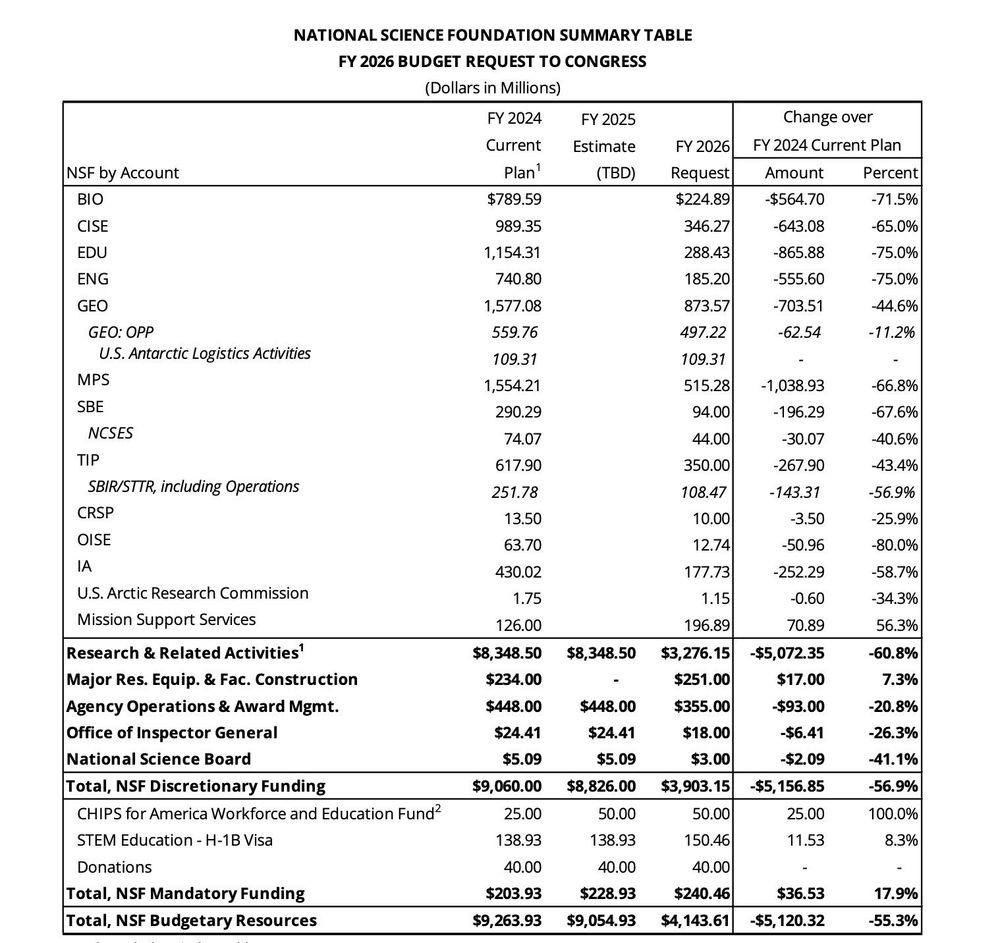
Percy Liang on X: "What would truly open-source AI look like? Not just open weights, open code/data, but *open development*, where the entire research and development process is public *and* anyone can contribute. We built Marin, an open lab, to fulfill this vision: https://t.co/racsvmhyA3" / X
What would truly open-source AI look like? Not just open weights, open code/data, but *open development*, where the entire research and development process is public *and* anyone can contribute. We built Marin, an open lab, to fulfill this vision: https://t.co/racsvmhyA3
x.com

Reposted by Greg Durrett





Reposted by Greg Durrett

Greg Durrett
@gregdnlp.bsky.social
· Apr 16
Reposted by Greg Durrett

Reposted by Greg Durrett
Reposted by Greg Durrett

Reposted by Greg Durrett

Will Stancil
@whstancil.bsky.social
· Feb 5
Reposted by Greg Durrett


Reposted by Greg Durrett






