Manya Wadhwa
@manyawadhwa.bsky.social
180 followers
170 following
17 posts
PhD at UTCS | #NLP
https://manyawadhwa.github.io/
Posts
Media
Videos
Starter Packs
Pinned



Reposted by Manya Wadhwa


Reposted by Manya Wadhwa



Reposted by Manya Wadhwa


Reposted by Manya Wadhwa


Reposted by Manya Wadhwa


Reposted by Manya Wadhwa

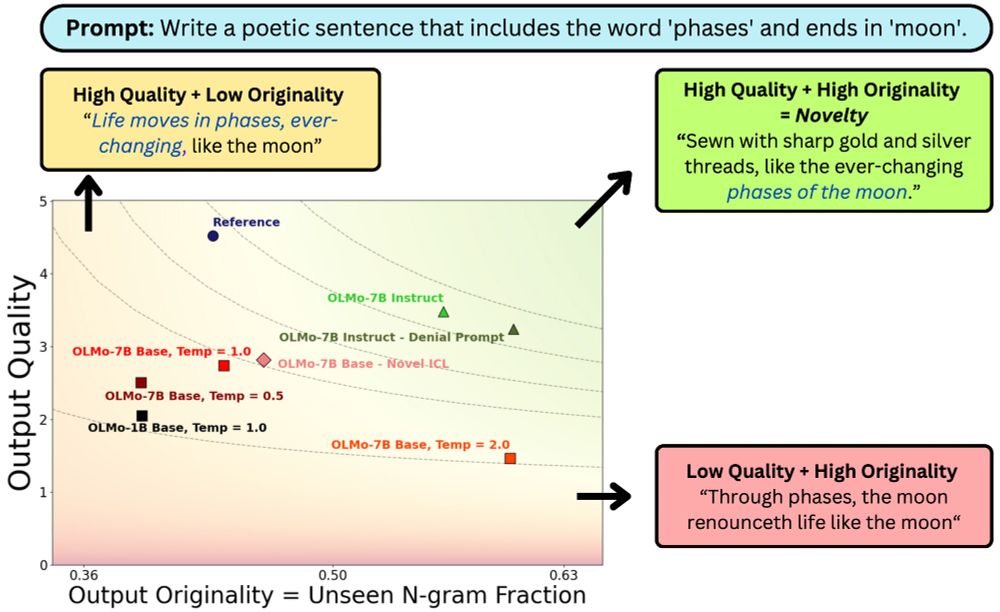
Reposted by Manya Wadhwa
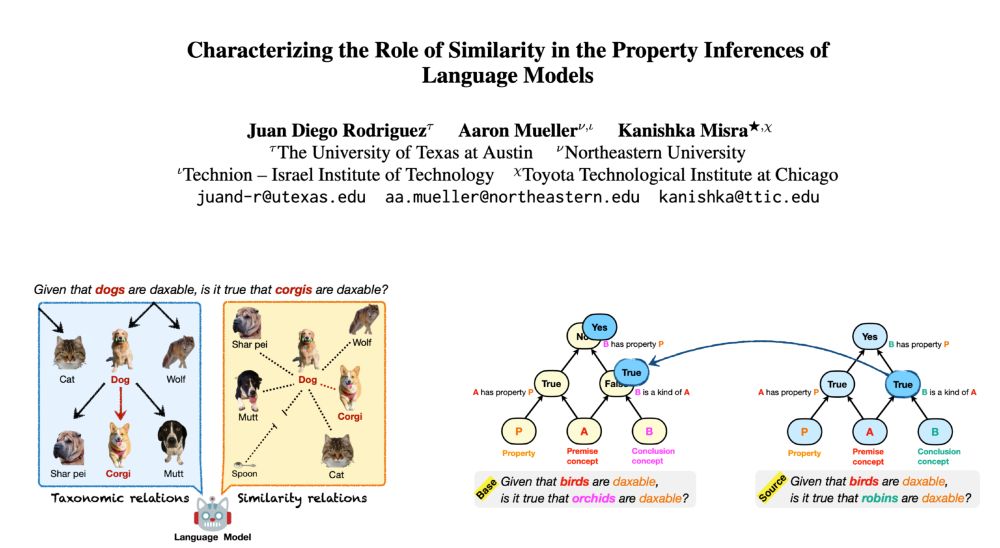
Reposted by Manya Wadhwa

Reposted by Manya Wadhwa


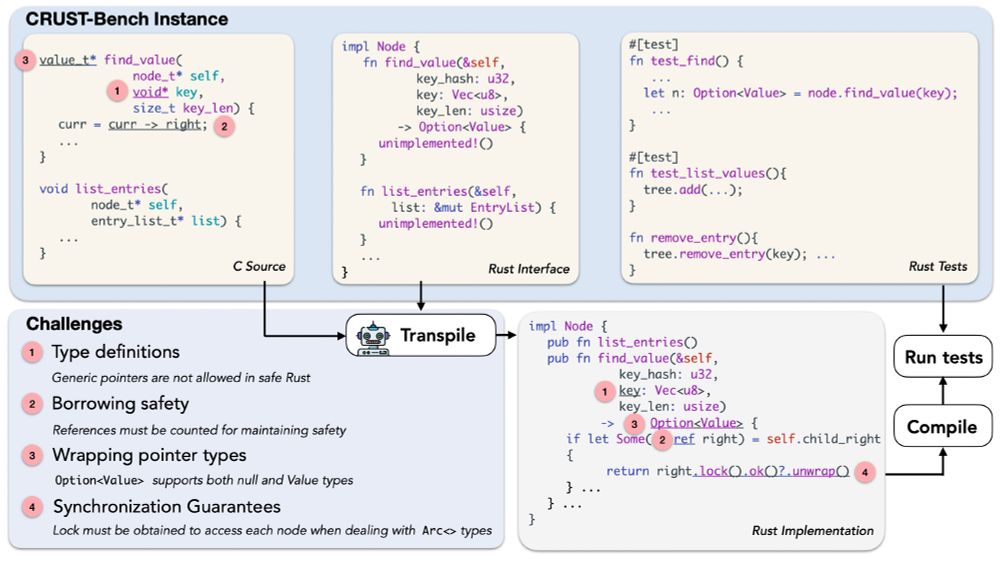
Manya Wadhwa
@manyawadhwa.bsky.social
· Apr 22
Manya Wadhwa
@manyawadhwa.bsky.social
· Apr 22
Manya Wadhwa
@manyawadhwa.bsky.social
· Apr 22


Manya Wadhwa
@manyawadhwa.bsky.social
· Apr 22
Manya Wadhwa
@manyawadhwa.bsky.social
· Apr 22


Reposted by Manya Wadhwa
Reposted by Manya Wadhwa
Reposted by Manya Wadhwa


Reposted by Manya Wadhwa

