Vishakh Padmakumar
@vishakhpk.bsky.social
54 followers
150 following
9 posts
PhD Student @nyudatascience.bsky.social, working with He He on NLP and Human-AI Collaboration.
Also hanging out @ai2.bsky.social
Website - https://vishakhpk.github.io/
Posts
Media
Videos
Starter Packs
Pinned


Reposted by Vishakh Padmakumar

Gautam Kamath
@gautamkamath.com
· May 1

Tips on How to Connect at Academic Conferences
I was a kinda awkward teenager. If you are a CS researcher reading this post, then chances are, you were too. How to navigate social situations and make friends is not always intuitive, and has to …
kamathematics.wordpress.com
Vishakh Padmakumar
@vishakhpk.bsky.social
· Apr 29

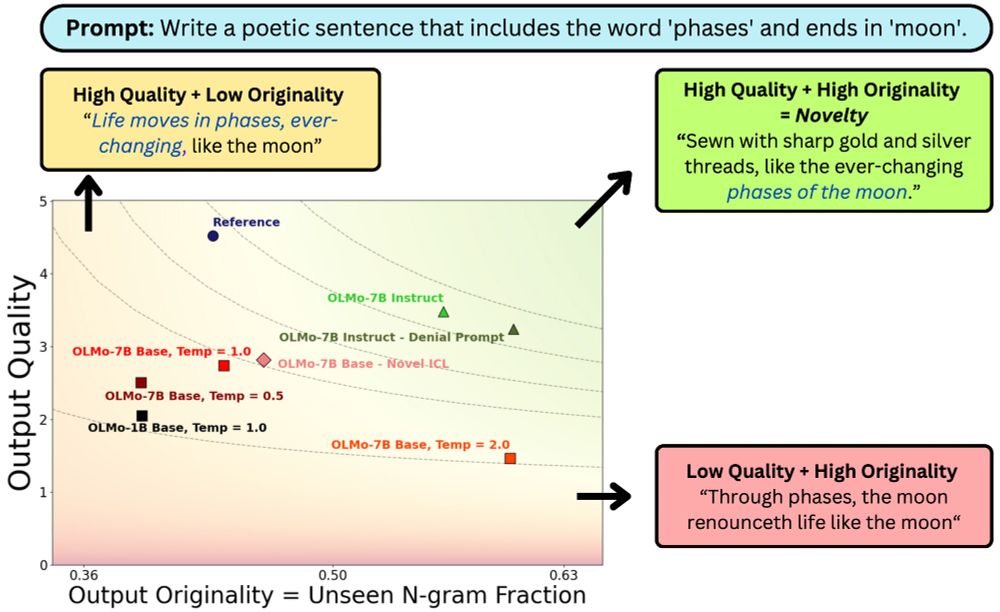
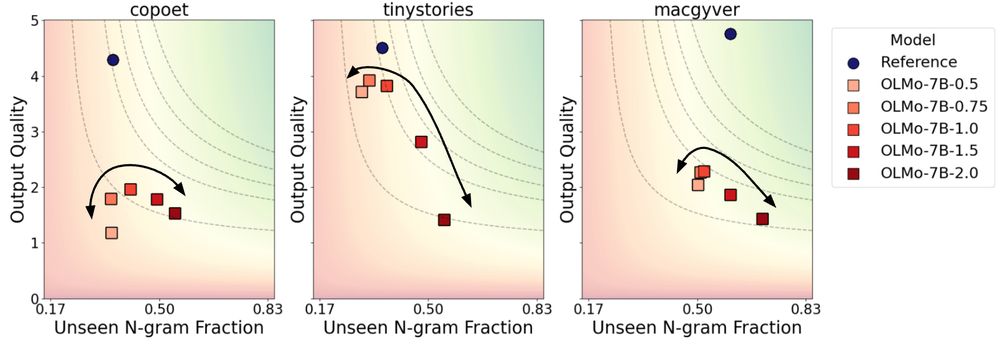
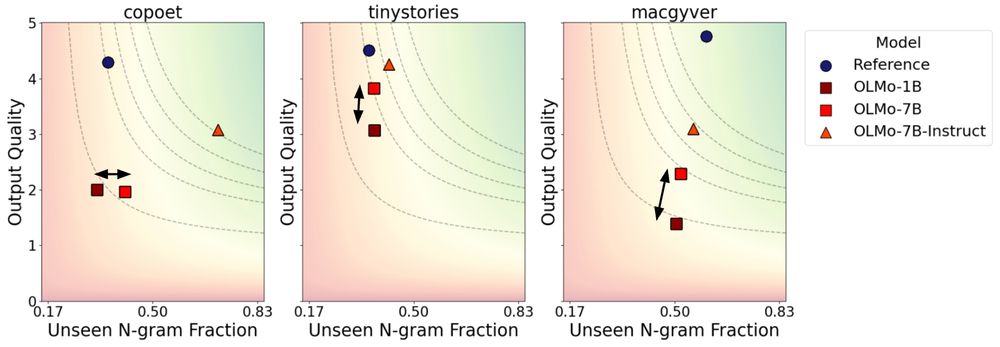
Beyond Memorization: Mapping the Originality-Quality Frontier of Language Models
As large language models (LLMs) are increasingly used for ideation and scientific discovery, it is important to evaluate their ability to generate novel output. Prior work evaluates novelty as the ori...
arxiv.org


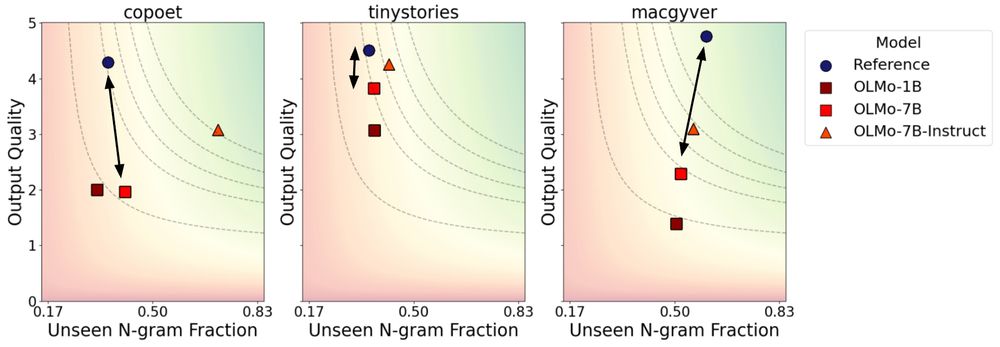
Vishakh Padmakumar
@vishakhpk.bsky.social
· Apr 29
Vishakh Padmakumar
@vishakhpk.bsky.social
· Apr 29
Reposted by Vishakh Padmakumar


Reposted by Vishakh Padmakumar

Reposted by Vishakh Padmakumar


Reposted by Vishakh Padmakumar


Reposted by Vishakh Padmakumar


Reposted by Vishakh Padmakumar


Reposted by Vishakh Padmakumar


Reposted by Vishakh Padmakumar

Vishakh Padmakumar
@vishakhpk.bsky.social
· Jan 31
Reposted by Vishakh Padmakumar


Reposted by Vishakh Padmakumar

