
Siddarth Venkatraman @ NeurIPS 2024
@hyperpotatoneo.bsky.social
330 followers
450 following
31 posts
PhD student at Mila | Diffusion models and reinforcement learning 🧐 | hyperpotatoneo.github.io
Posts
Media
Videos
Starter Packs
Reposted by Siddarth Venkatraman @ NeurIPS 2024

Benno Krojer
@bennokrojer.bsky.social
· Dec 22

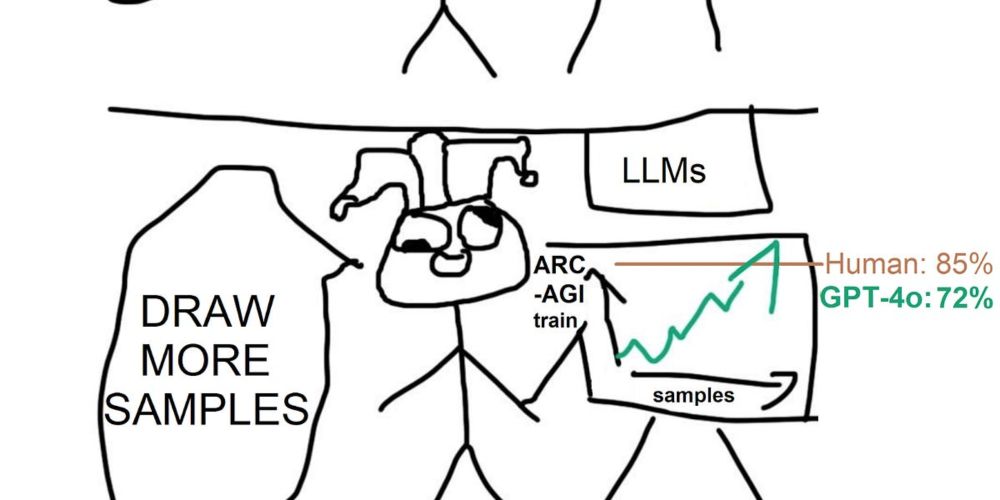
Reposted by Siddarth Venkatraman @ NeurIPS 2024

Reposted by Siddarth Venkatraman @ NeurIPS 2024


