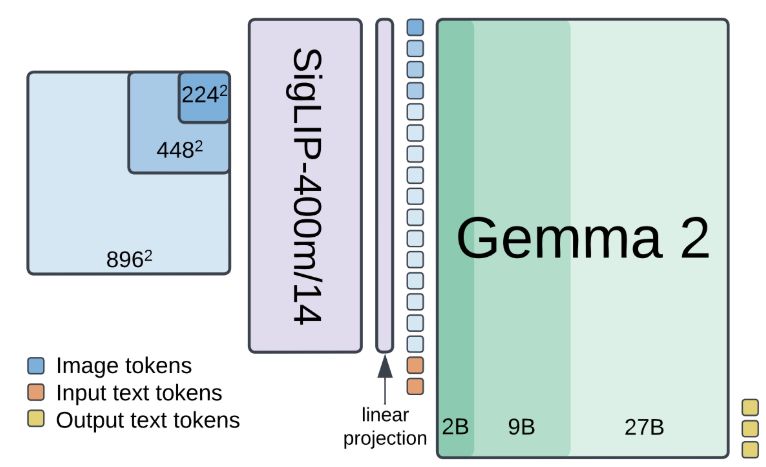
Ibrahim Alabdulmohsin
@ibomohsin.bsky.social
110 followers
98 following
14 posts
AI research scientist at Google Deepmind, Zürich
Posts
Media
Videos
Starter Packs
Reposted by Ibrahim Alabdulmohsin



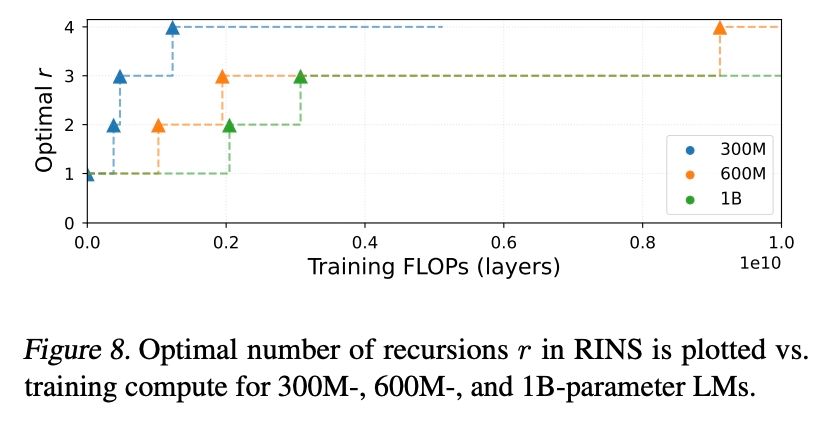
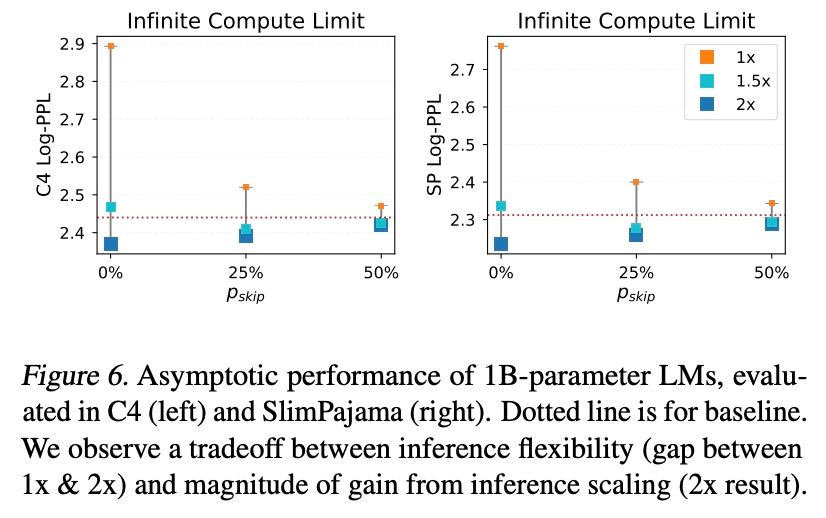
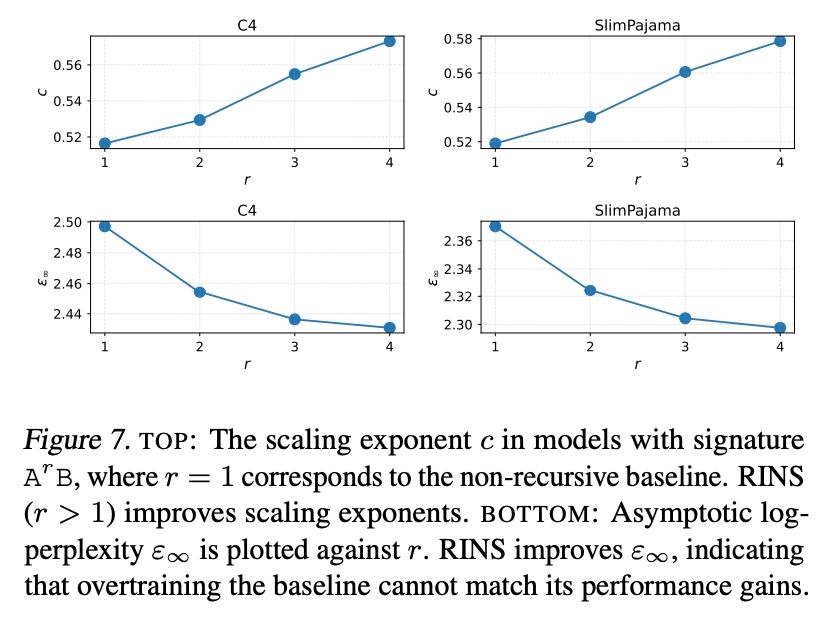
Reposted by Ibrahim Alabdulmohsin





Reposted by Ibrahim Alabdulmohsin