Kunal Jha
@kjha02.bsky.social
97 followers
350 following
31 posts
CS PhD Student @University of Washington, CSxPhilosophy @Dartmouth College
Interested in MARL, Social Reasoning, and Collective Decision making in people, machines, and other organisms
kjha02.github.io
Posts
Media
Videos
Starter Packs








Reposted by Kunal Jha

Reposted by Kunal Jha

Kunal Jha
@kjha02.bsky.social
· Jul 8
Kunal Jha
@kjha02.bsky.social
· Apr 19
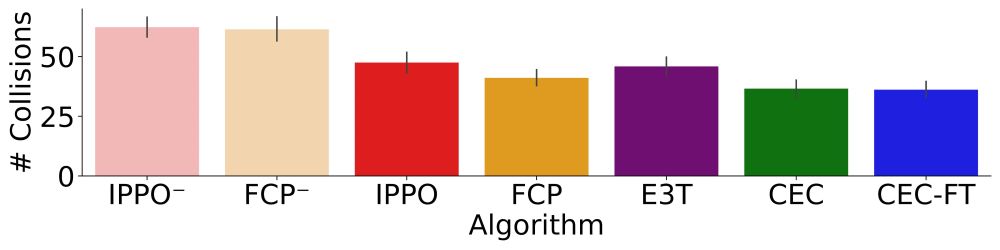
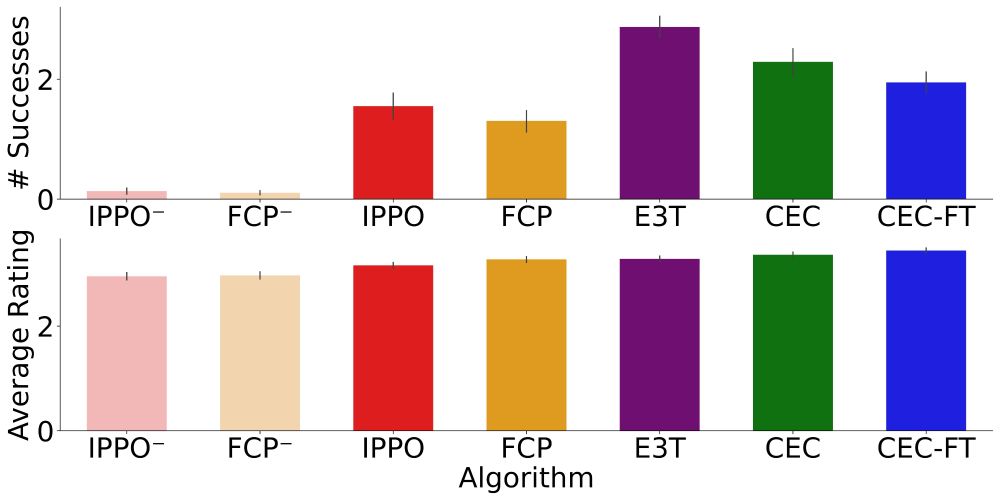
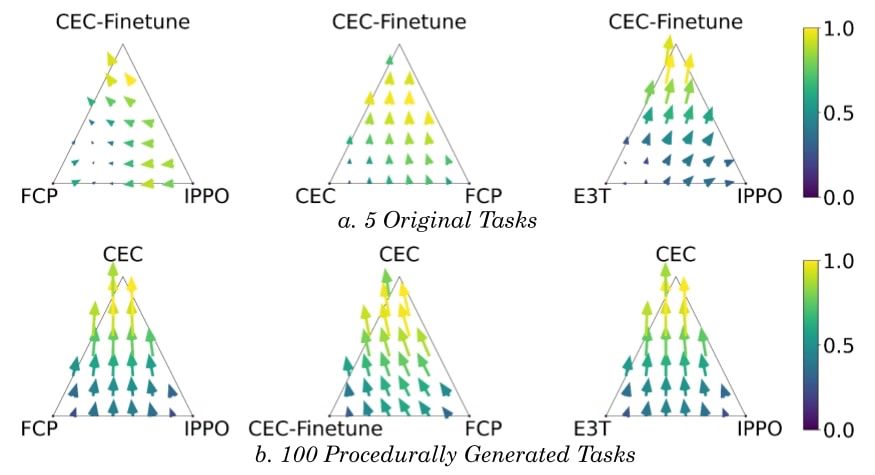
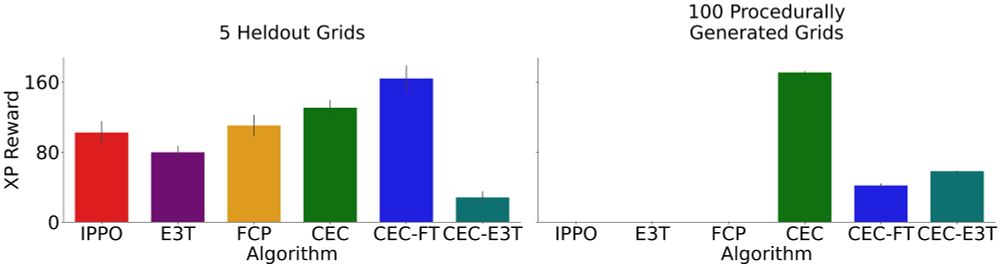
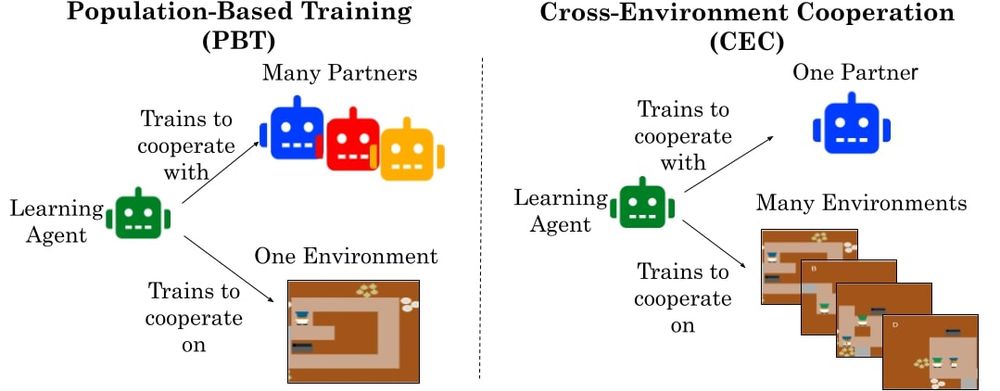
Cross-environment Cooperation Enables Zero-shot Multi-agent Coordination
How can AI develop the ability to cooperate with novel people on novel problems? We show AI learning to cooperate in “self-play” with one partner on many environments helps agents meta-learn to cooper...
kjha02.github.io
Kunal Jha
@kjha02.bsky.social
· Apr 19