Tom Kocmi
@kocmitom.bsky.social
260 followers
110 following
25 posts
Researcher at Cohere | Multilingual LLM evaluation
Posts
Media
Videos
Starter Packs
Reposted by Tom Kocmi







Tom Kocmi
@kocmitom.bsky.social
· Aug 26
Tom Kocmi
@kocmitom.bsky.social
· Aug 23
Tom Kocmi
@kocmitom.bsky.social
· Aug 23
Tom Kocmi
@kocmitom.bsky.social
· Aug 23

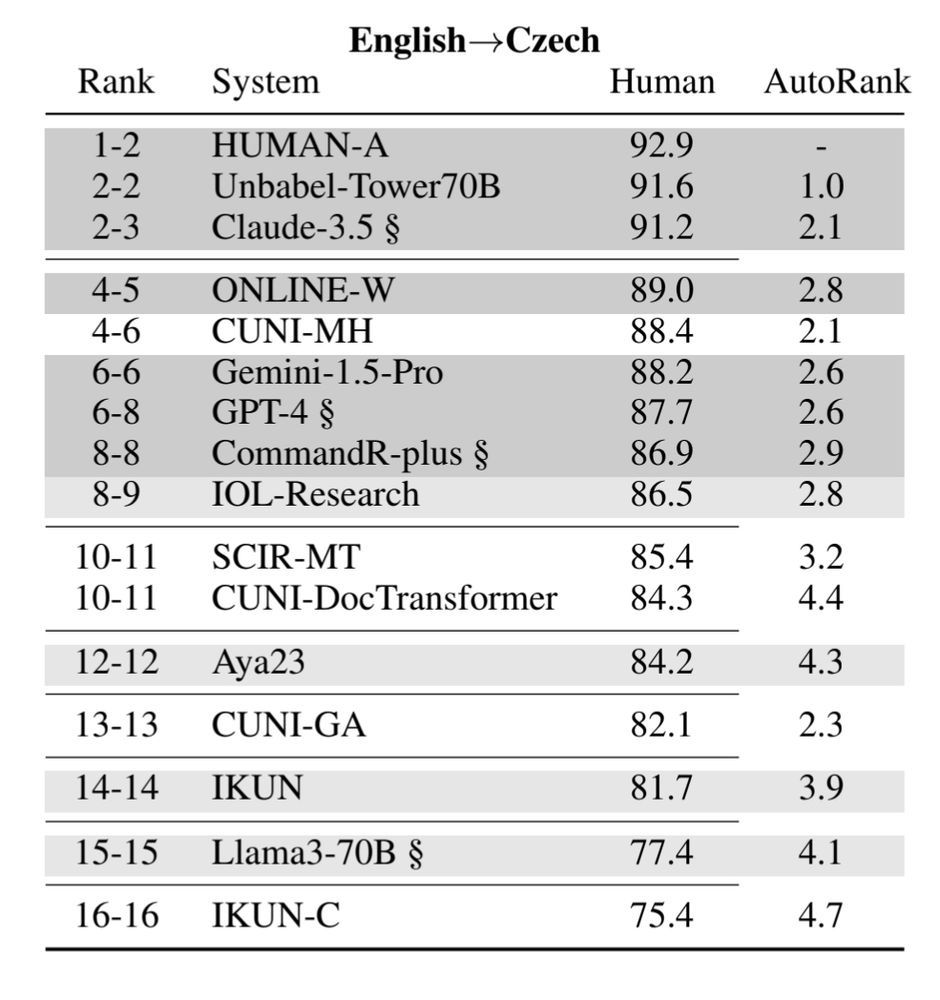
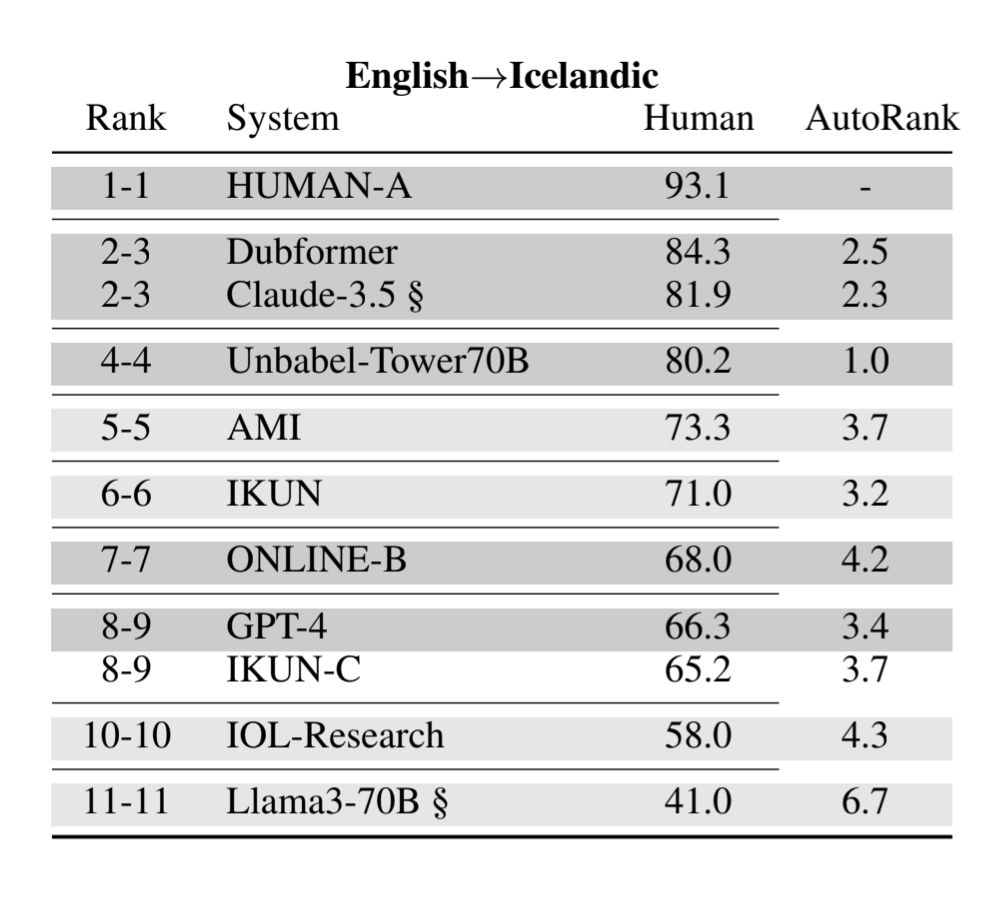
Preliminary Ranking of WMT25 General Machine Translation Systems
We present the preliminary ranking of the WMT25 General Machine Translation Shared Task, in which MT systems have been evaluated using automatic metrics. As this ranking is based on automatic evaluati...
arxiv.org

Tom Kocmi
@kocmitom.bsky.social
· Mar 28
Tom Kocmi
@kocmitom.bsky.social
· Mar 27

Tom Kocmi
@kocmitom.bsky.social
· Mar 4

Cohere Labs
@cohereforai.bsky.social
· Mar 4

Aya Vision: Expanding the Worlds AI Can See
Our state-of-the-art open-weights vision model offers a foundation for AI-enabled multilingual and multimodal communication globally.
Today, Cohere For AI, Cohere’s open research arm, is proud to an...
cohere.com
Tom Kocmi
@kocmitom.bsky.social
· Mar 1
WMT24++: Expanding the Language Coverage of WMT24 to 55 Languages & Dialects
As large language models (LLM) become more and more capable in languages other than English, it is important to collect benchmark datasets in order to evaluate their multilingual performance, includin...
arxiv.org
Tom Kocmi
@kocmitom.bsky.social
· Feb 20
Tom Kocmi
@kocmitom.bsky.social
· Feb 20
Tom Kocmi
@kocmitom.bsky.social
· Feb 9
Tom Kocmi
@kocmitom.bsky.social
· Feb 8
Tom Kocmi
@kocmitom.bsky.social
· Nov 20