Julia Kreutzer
@juliakreutzer.bsky.social
160 followers
170 following
20 posts
NLP & ML research @cohereforai.bsky.social
Posts
Media
Videos
Starter Packs

Reposted by Julia Kreutzer


Reposted by Julia Kreutzer


Reposted by Julia Kreutzer





Julia Kreutzer
@juliakreutzer.bsky.social
· Jun 26


Julia Kreutzer
@juliakreutzer.bsky.social
· May 28
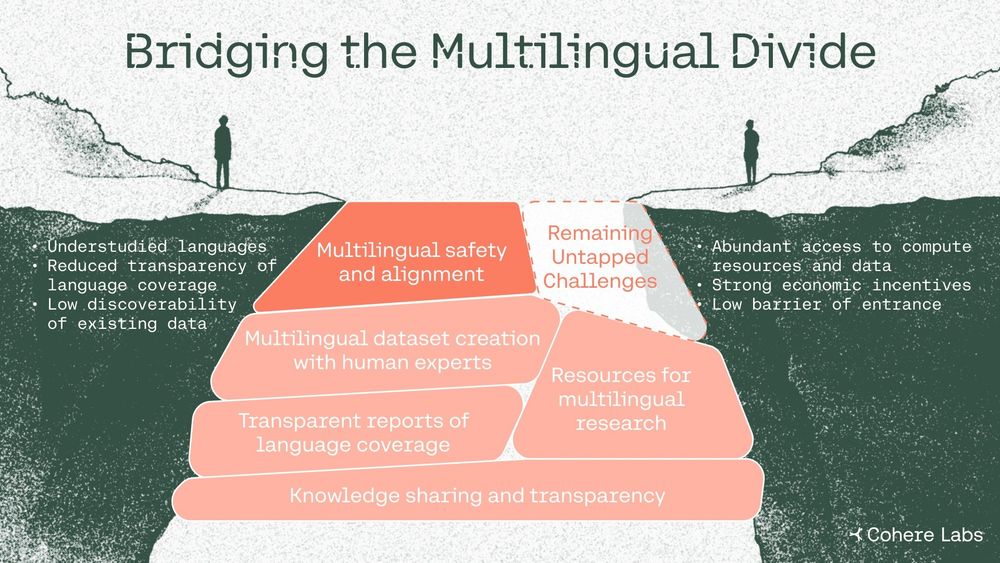


Reposted by Julia Kreutzer

Julia Kreutzer
@juliakreutzer.bsky.social
· Apr 24

Reposted by Julia Kreutzer


Julia Kreutzer
@juliakreutzer.bsky.social
· Apr 17






Julia Kreutzer
@juliakreutzer.bsky.social
· Apr 17
Reposted by Julia Kreutzer

Reposted by Julia Kreutzer
Tom Kocmi
@kocmitom.bsky.social
· Mar 28