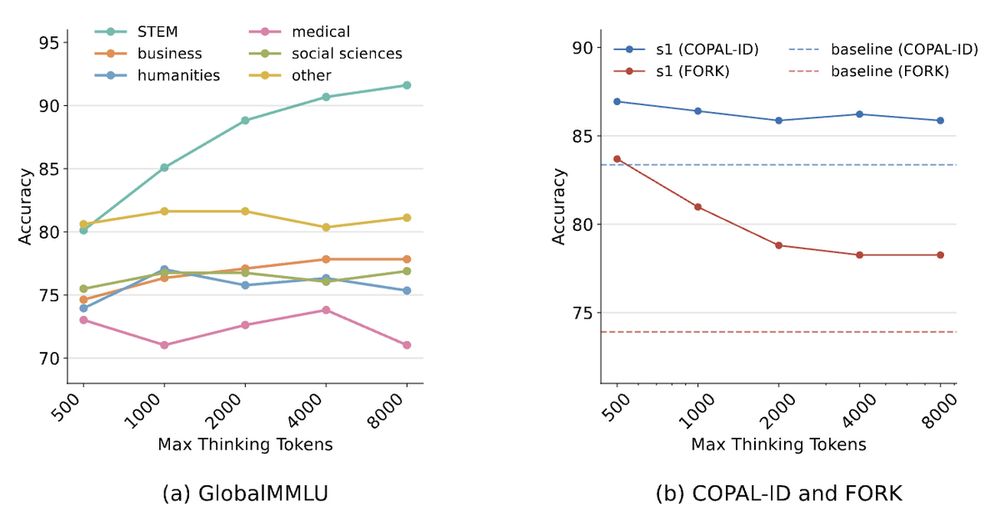
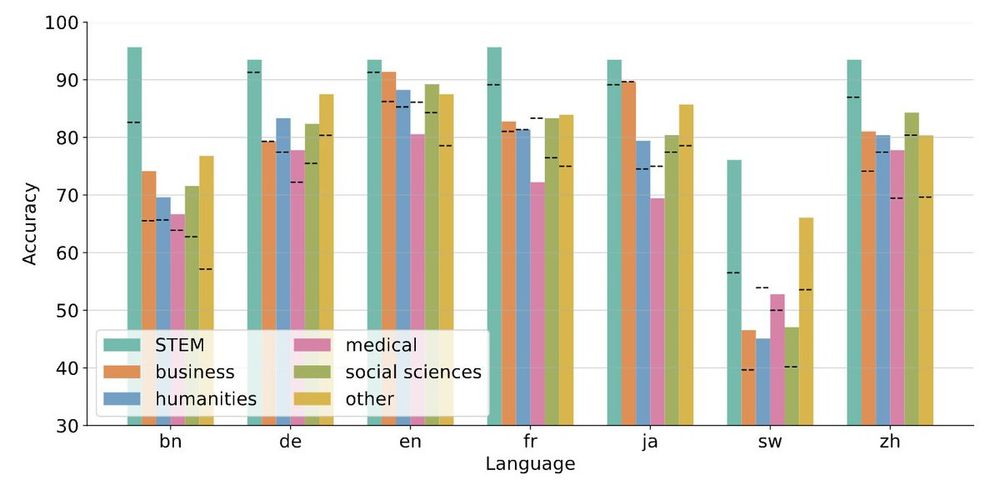
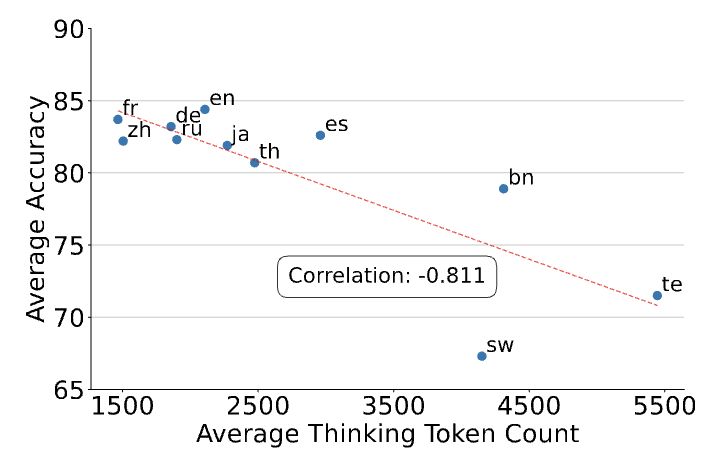
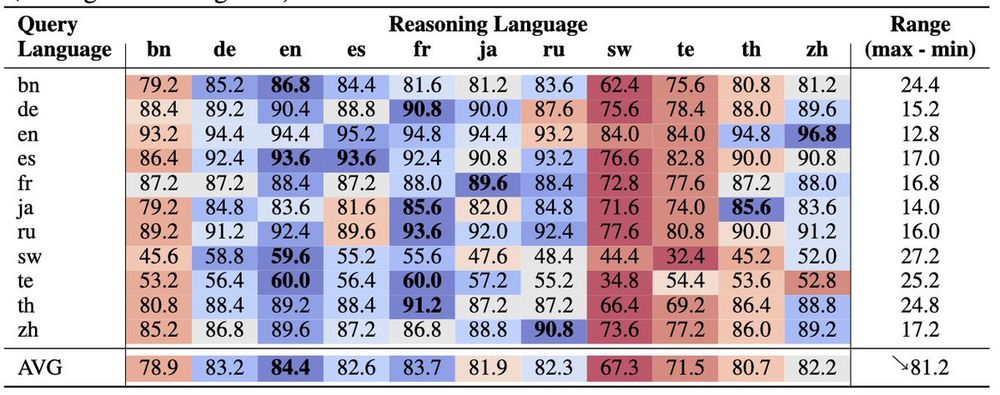
Yong Zheng-Xin (Yong)
@yongzx.bsky.social
67 followers
80 following
14 posts
ml research at Brown University // collab at Meta AI and Cohere For AI
🔗 yongzx.github.io
Posts
Media
Videos
Starter Packs
Reposted by Yong Zheng-Xin (Yong)


Reposted by Yong Zheng-Xin (Yong)


Yong Zheng-Xin (Yong)
@yongzx.bsky.social
· May 11
Reposted by Yong Zheng-Xin (Yong)

Reposted by Yong Zheng-Xin (Yong)