
Benjamin Laufer
@laufer.bsky.social
240 followers
190 following
45 posts
PhD student at Cornell Tech.
bendlaufer.github.io
Posts
Media
Videos
Starter Packs
Reposted by Benjamin Laufer

Reposted by Benjamin Laufer



Benjamin Laufer
@laufer.bsky.social
· Aug 15
Reposted by Benjamin Laufer

Marcelo Rinesi
@marcelorinesi.bsky.social
· Aug 14
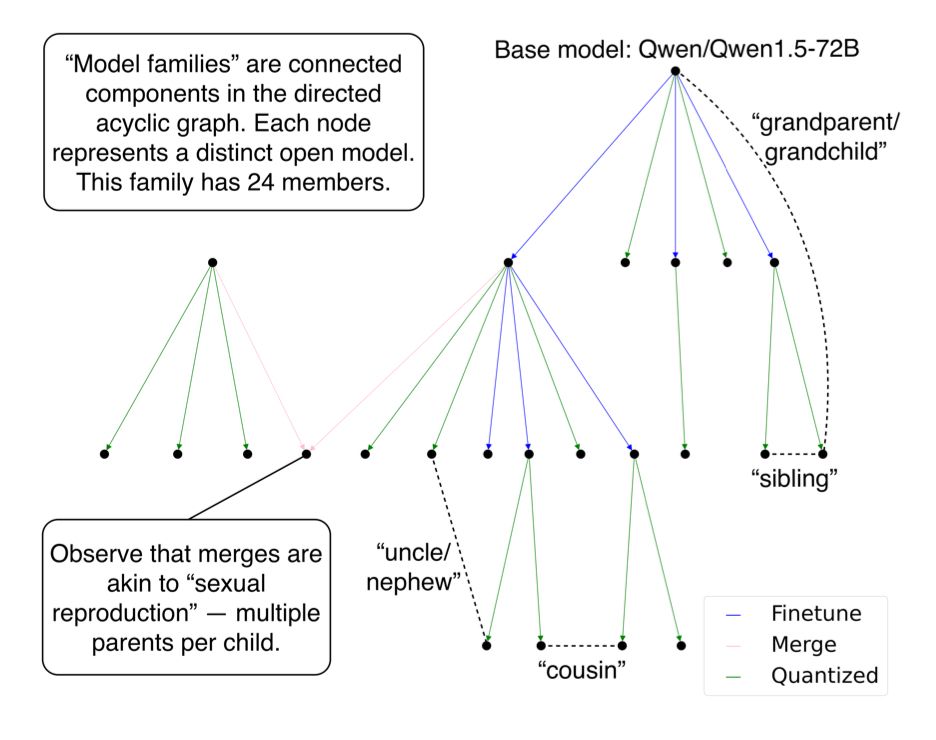
Benjamin Laufer
@laufer.bsky.social
· Aug 14
Benjamin Laufer
@laufer.bsky.social
· Aug 14
Benjamin Laufer
@laufer.bsky.social
· Aug 14



Benjamin Laufer
@laufer.bsky.social
· Aug 14
Benjamin Laufer
@laufer.bsky.social
· Aug 14
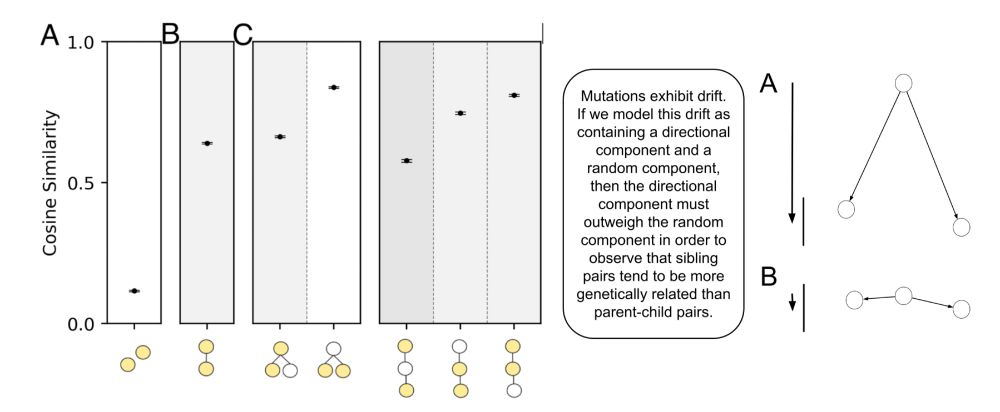

Benjamin Laufer
@laufer.bsky.social
· Aug 14