
Lester Mackey
@lestermackey.bsky.social
150 followers
16 following
12 posts
Machine learning researcher at Microsoft Research. Adjunct professor at Stanford.
Posts
Media
Videos
Starter Packs
Pinned




Reposted by Lester Mackey


Reposted by Lester Mackey



Reposted by Lester Mackey

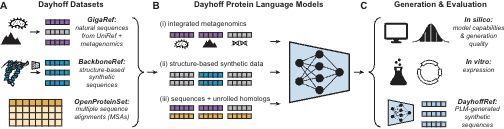
Reposted by Lester Mackey

Reposted by Lester Mackey




Reposted by Lester Mackey

Reposted by Lester Mackey



Reposted by Lester Mackey

Reposted by Lester Mackey

Theresa Kim, PhD, MS
@tyk314.net
· Mar 14

Reposted by Lester Mackey


Reposted by Lester Mackey


Reposted by Lester Mackey


