
Lindia Tjuatja
@lindiatjuatja.bsky.social
2.1K followers
430 following
49 posts
a natural language processor and “sensible linguist”. PhD-ing LTI@CMU, previously BS-ing Ling+ECE@UTAustin
🤠🤖📖 she/her
lindiatjuatja.github.io
Posts
Media
Videos
Starter Packs
Pinned

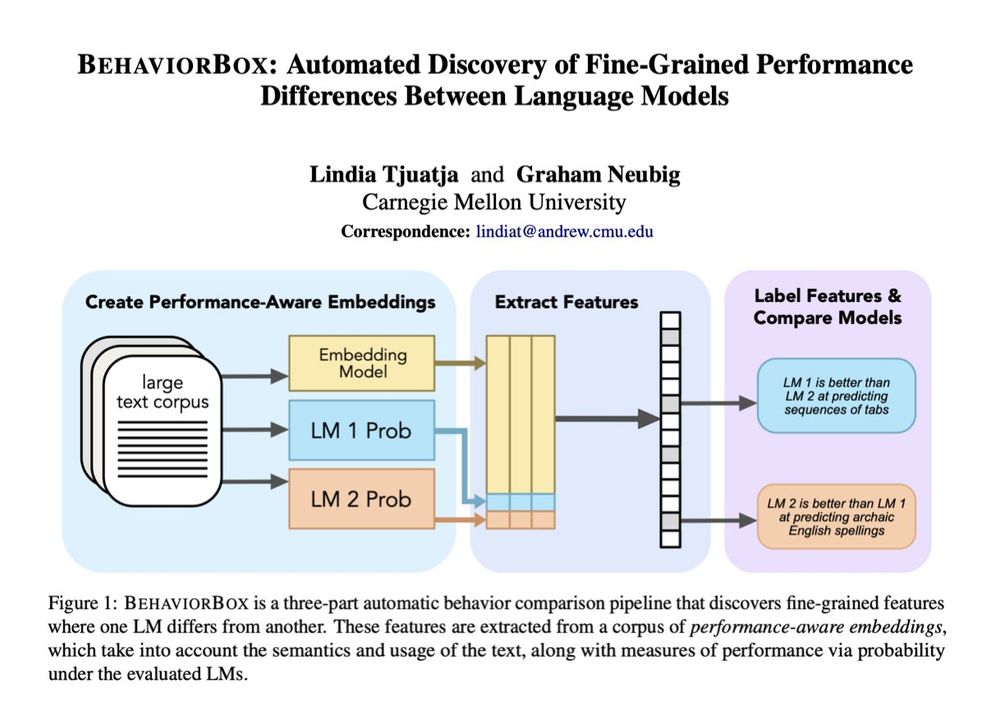
Reposted by Lindia Tjuatja


Reposted by Lindia Tjuatja





Lindia Tjuatja
@lindiatjuatja.bsky.social
· Jul 25
Lindia Tjuatja
@lindiatjuatja.bsky.social
· Jul 25
Reposted by Lindia Tjuatja

Emma Strubell
@strubell.bsky.social
· Jul 14


Reposted by Lindia Tjuatja


Reposted by Lindia Tjuatja



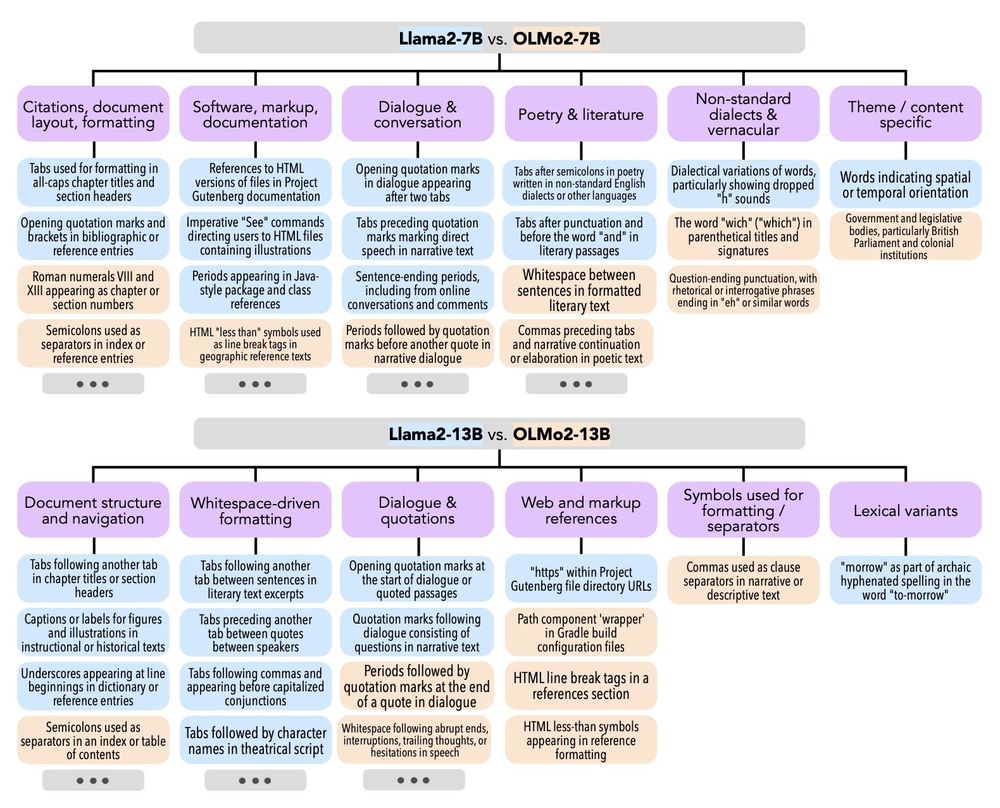



Lindia Tjuatja
@lindiatjuatja.bsky.social
· Apr 30

Lindia Tjuatja
@lindiatjuatja.bsky.social
· Jan 25
Reposted by Lindia Tjuatja

Ted Underwood
@tedunderwood.com
· Jan 23
Lindia Tjuatja
@lindiatjuatja.bsky.social
· Jan 22



Lindia Tjuatja
@lindiatjuatja.bsky.social
· Dec 29
Lindia Tjuatja
@lindiatjuatja.bsky.social
· Dec 24
Reposted by Lindia Tjuatja

