Jiacheng Liu
@liujch1998.bsky.social
87 followers
52 following
16 posts
🎓 PhD student @uwcse @uwnlp. 🛩 Private pilot. Previously: 🧑💻 @oculus, 🎓 @IllinoisCS. 📖 🥾 🚴♂️ 🎵 ♠️
Posts
Media
Videos
Starter Packs
Pinned

Reposted by Jiacheng Liu

Ai2
@ai2.bsky.social
· Jun 30
Reposted by Jiacheng Liu

Reposted by Jiacheng Liu

Allen School
@uwcse.bsky.social
· Jun 4

‘Bold,’ ‘positive’ and ‘unparalleled’: Allen School Ph.D. graduates Ashish Sharma and Sewon Min recognized with ACM Doctoral Dissertation Awards - Allen School News
Each year, the Association for Computing Machinery recognizes the best Ph.D. dissertations in computer science with its Doctoral Dissertation Award. Ashish Sharma (Ph.D., ‘24), now a senior applied sc...
news.cs.washington.edu
Reposted by Jiacheng Liu


Reposted by Jiacheng Liu

Reposted by Jiacheng Liu
Ai2
@ai2.bsky.social
· May 6
Reposted by Jiacheng Liu

Reposted by Jiacheng Liu

Reposted by Jiacheng Liu


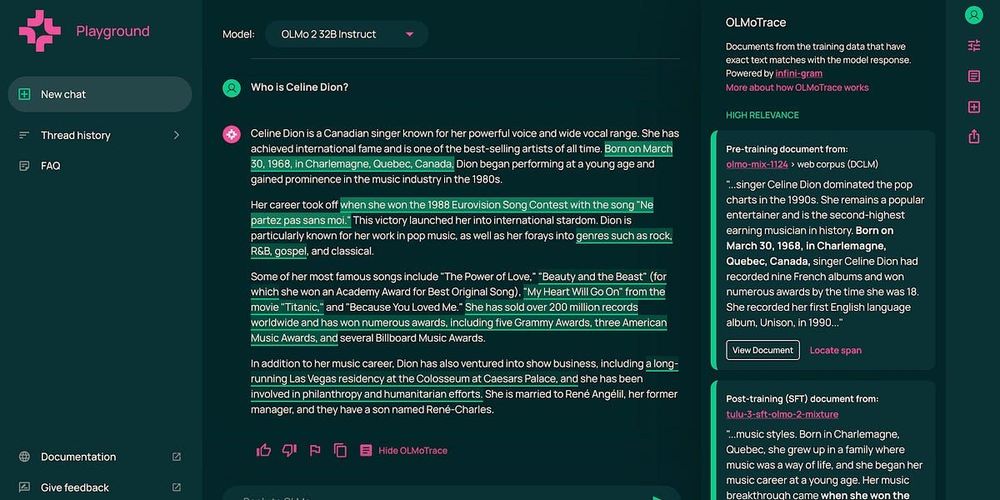
Reposted by Jiacheng Liu




Reposted by Jiacheng Liu

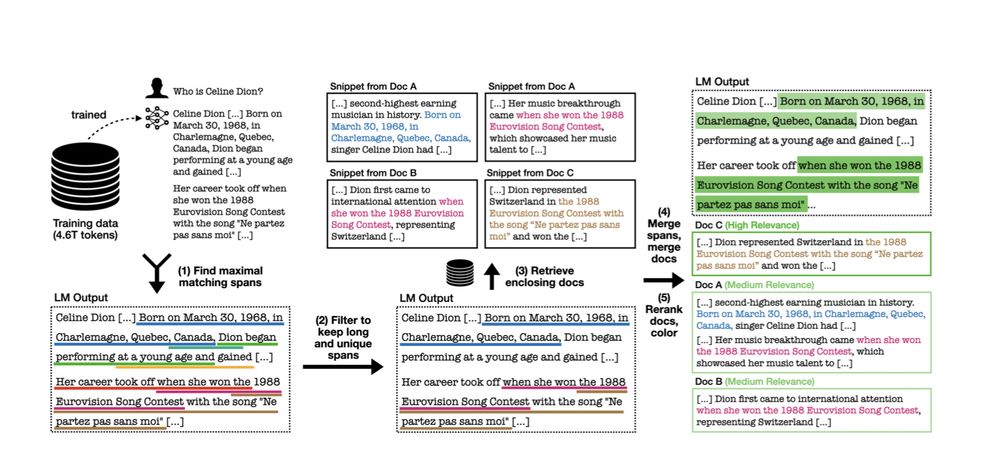
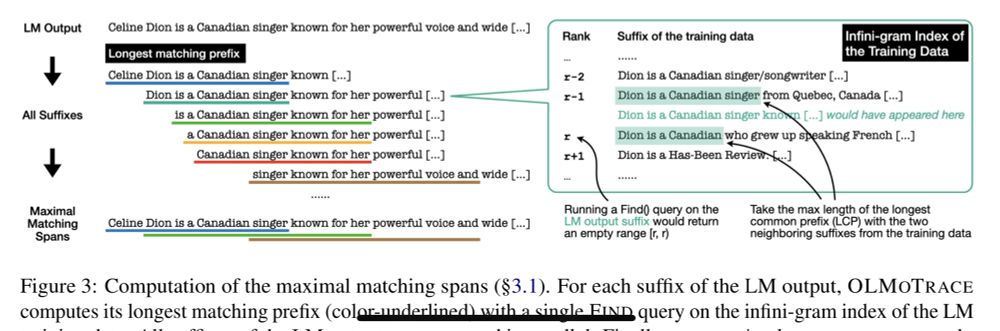
Reposted by Jiacheng Liu
Reposted by Jiacheng Liu
Ai2
@ai2.bsky.social
· Apr 8
Jiacheng Liu
@liujch1998.bsky.social
· Apr 8
Jiacheng Liu
@liujch1998.bsky.social
· Apr 8
Jiacheng Liu
@liujch1998.bsky.social
· Apr 8
Reposted by Jiacheng Liu
Reposted by Jiacheng Liu

Reposted by Jiacheng Liu


Jiacheng Liu
@liujch1998.bsky.social
· Dec 9