
Elizabeth Stuart
@lizstuart.bsky.social
5.5K followers
290 following
44 posts
Statistician; Professor and Chair @JHUBiostat @JohnsHopkinsSPH, w/links to @SREESociety, @AmericanHealth. Oh, & spouse, mom, runner, traveler.
Posts
Media
Videos
Starter Packs
Reposted by Elizabeth Stuart




Elizabeth Stuart
@lizstuart.bsky.social
· Aug 18




Elizabeth Stuart
@lizstuart.bsky.social
· Aug 14
Elizabeth Stuart
@lizstuart.bsky.social
· Jul 31

Elizabeth Stuart
@lizstuart.bsky.social
· Jun 11

Noah Greifer
@noahgreifer.bsky.social
· Jun 4


Elizabeth Stuart
@lizstuart.bsky.social
· Apr 25
Elizabeth Stuart
@lizstuart.bsky.social
· Apr 25



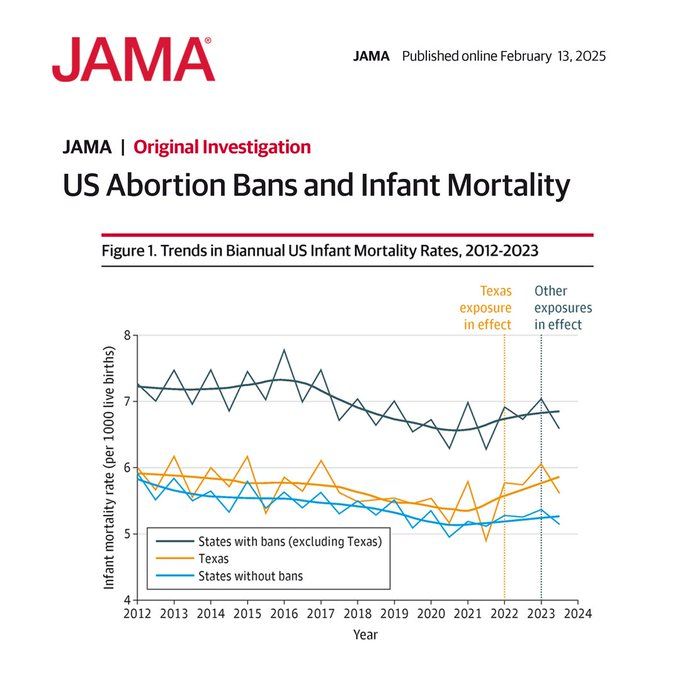
Elizabeth Stuart
@lizstuart.bsky.social
· Jan 28
Reposted by Elizabeth Stuart






Elizabeth Stuart
@lizstuart.bsky.social
· Dec 11

