Marco Ciapparelli
@marcociapparelli.bsky.social
92 followers
160 following
26 posts
Postdoc in psychology and cognitive neuroscience mainly interested in conceptual combination, semantic memory and computational modeling.
https://marcociapparelli.github.io/
Posts
Media
Videos
Starter Packs


Reposted by Marco Ciapparelli

Reposted by Marco Ciapparelli

Marc Coutanche
@marccoutanche.bsky.social
· Aug 26

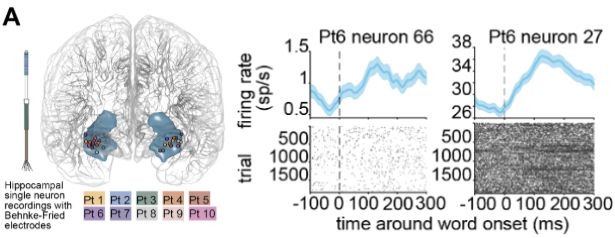
The Neural Consequences of Semantic Composition
Humans can create completely new concepts through semantic composition. These ‘conceptual combinations’ can be created by attributing the features of one concept to another (e.g., a lemon flamingo mig...
www.biorxiv.org





Reposted by Marco Ciapparelli




Reposted by Marco Ciapparelli

![from minicons import scorer
from nltk.tokenize import TweetTokenizer
lm = scorer.IncrementalLMScorer("gpt2")
# your own tokenizer function that returns a list of words
# given some sentence input
word_tokenizer = TweetTokenizer().tokenize
# word scoring
lm.word_score_tokenized(
["I was a matron in France", "I was a mat in France"],
bos_token=True, # needed for GPT-2/Pythia and NOT needed for others
tokenize_function=word_tokenizer,
bow_correction=True, # Oh and Schuler correction
surprisal=True,
base_two=True
)
'''
First word = -log_2 P(word | <beginning of text>)
[[('I', 6.1522440910339355),
('was', 4.033324718475342),
('a', 4.879510402679443),
('matron', 17.611848831176758),
('in', 2.5804288387298584),
('France', 9.036953926086426)],
[('I', 6.1522440910339355),
('was', 4.033324718475342),
('a', 4.879510402679443),
('mat', 19.385351181030273),
('in', 6.76780366897583),
('France', 10.574726104736328)]]
'''](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:njnapclhkbrhe3hsq44q2e4w/bafkreibw7fjs4zeocjmfvpr4fo7wikiqenbdz7b3clwq2rolckpoqwkssu@jpeg)
Reposted by Marco Ciapparelli

