




Marzena Karpinska
@markar.bsky.social
#nlp researcher interested in evaluation including: multilingual models, long-form input/output, processing/generation of creative texts
previous: postdoc @ umass_nlp
phd from utokyo
https://marzenakrp.github.io/
previous: postdoc @ umass_nlp
phd from utokyo
https://marzenakrp.github.io/
Now is probably a good time to share that I left my job at
@microsoft.com (will forever miss this team) and moved to Vancouver, Canada, where I'm starting my lab as an assistant professor at the gorgeous @sfu.ca 🏔️
I'm looking to hire 1-2 students starting in Fall 2026. Details in 🧵
@microsoft.com (will forever miss this team) and moved to Vancouver, Canada, where I'm starting my lab as an assistant professor at the gorgeous @sfu.ca 🏔️
I'm looking to hire 1-2 students starting in Fall 2026. Details in 🧵

January 16, 2026 at 9:18 PM
Now is probably a good time to share that I left my job at
@microsoft.com (will forever miss this team) and moved to Vancouver, Canada, where I'm starting my lab as an assistant professor at the gorgeous @sfu.ca 🏔️
I'm looking to hire 1-2 students starting in Fall 2026. Details in 🧵
@microsoft.com (will forever miss this team) and moved to Vancouver, Canada, where I'm starting my lab as an assistant professor at the gorgeous @sfu.ca 🏔️
I'm looking to hire 1-2 students starting in Fall 2026. Details in 🧵
I'm not sure why people lost the ability to do related work properly but if you absolutely need to use AI at least proofread it? (And they most likely edited with ai)
www.pangram.com/history/01bf...
www.pangram.com/history/01bf...

October 18, 2025 at 4:18 PM
I'm not sure why people lost the ability to do related work properly but if you absolutely need to use AI at least proofread it? (And they most likely edited with ai)
www.pangram.com/history/01bf...
www.pangram.com/history/01bf...
Come to talk with us today about the evaluation of long form multilingual generation at the second poster session #COLM2025
📍4:30–6:30 PM / Room 710 – Poster #8
📍4:30–6:30 PM / Room 710 – Poster #8

October 7, 2025 at 5:54 PM
Come to talk with us today about the evaluation of long form multilingual generation at the second poster session #COLM2025
📍4:30–6:30 PM / Room 710 – Poster #8
📍4:30–6:30 PM / Room 710 – Poster #8



I feel like it was worth waking up early

October 6, 2025 at 2:35 PM
I feel like it was worth waking up early
Happy to see this work accepted to #EMNLP2025! 🎉🎉🎉

August 20, 2025 at 8:49 PM
Happy to see this work accepted to #EMNLP2025! 🎉🎉🎉
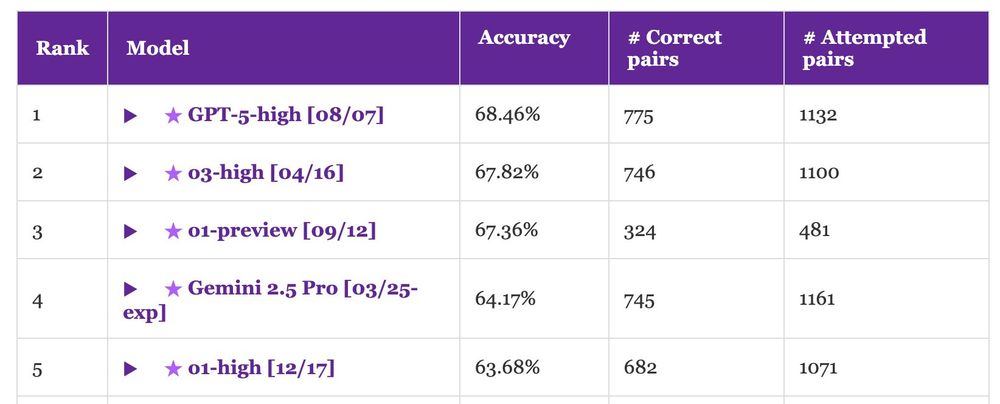
GPT-5 lands first place on NoCha, our long-context book understanding benchmark.
That said, this is a tiny improvement (~1%) over o1-preview, which was released almost one year ago. Have long-context models hit a wall?
Accuracy of human readers is >97%... Long way to go!
That said, this is a tiny improvement (~1%) over o1-preview, which was released almost one year ago. Have long-context models hit a wall?
Accuracy of human readers is >97%... Long way to go!
August 8, 2025 at 2:13 AM
GPT-5 lands first place on NoCha, our long-context book understanding benchmark.
That said, this is a tiny improvement (~1%) over o1-preview, which was released almost one year ago. Have long-context models hit a wall?
Accuracy of human readers is >97%... Long way to go!
That said, this is a tiny improvement (~1%) over o1-preview, which was released almost one year ago. Have long-context models hit a wall?
Accuracy of human readers is >97%... Long way to go!
We have updated #nocha (long-context benchmark measuring how well models process book-length narratives) with #Llama4 Scout. Sadly, the performance was below the random level, much lower than the reported model's performance on a retrieval task (needle in the haystack). novelchallenge.github.io

April 7, 2025 at 4:50 AM
We have updated #nocha (long-context benchmark measuring how well models process book-length narratives) with #Llama4 Scout. Sadly, the performance was below the random level, much lower than the reported model's performance on a retrieval task (needle in the haystack). novelchallenge.github.io
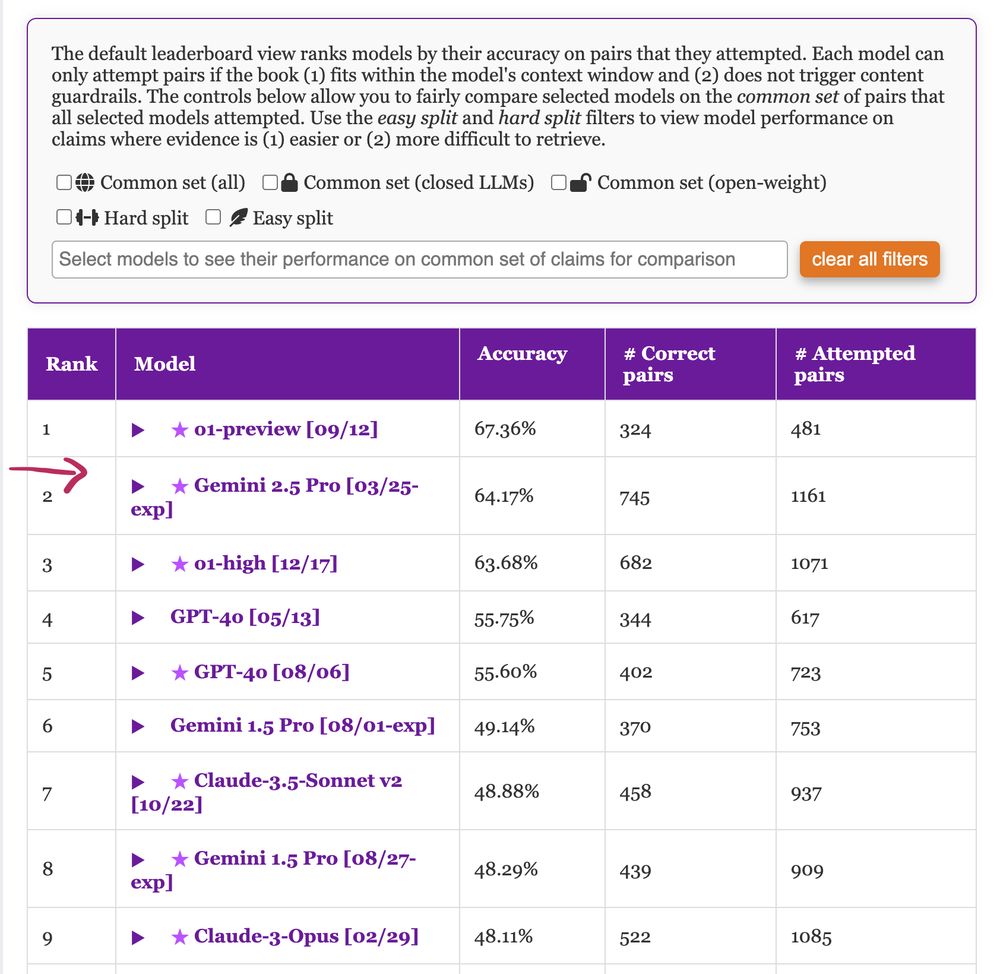
We have updated #nocha, a leaderboard for reasoning over long-context narratives 📖, with some new models including #Gemini 2.5 Pro which shows massive improvements over the previous version! Congrats to #Gemini team 🪄 🧙 Check 🔗 novelchallenge.github.io for details :)
April 2, 2025 at 4:30 AM
We have updated #nocha, a leaderboard for reasoning over long-context narratives 📖, with some new models including #Gemini 2.5 Pro which shows massive improvements over the previous version! Congrats to #Gemini team 🪄 🧙 Check 🔗 novelchallenge.github.io for details :)
An absolutely awesome lineup of language pairs for the 20th iteration of WMT 🍾🎉

February 21, 2025 at 12:48 AM
An absolutely awesome lineup of language pairs for the 20th iteration of WMT 🍾🎉
No matter how we tried to modify #LLM generated text (paraphrasing, humanization), people who frequently use LLMs for writing are consistently good at detecting model-generated text, though they change cues they rely on! Congrats @jennarussell.bsky.social on first paper!

January 28, 2025 at 3:36 PM
No matter how we tried to modify #LLM generated text (paraphrasing, humanization), people who frequently use LLMs for writing are consistently good at detecting model-generated text, though they change cues they rely on! Congrats @jennarussell.bsky.social on first paper!
We've added #o1 and #Llama 3.3 70B to the #Nocha leaderboard for long-context narrative reasoning! Surprisingly, o1 performs worse than o1-preview, and Llama 3.3 70B matches proprietary models like gpt4o-mini & gemini-Flash. Check out our website for more results! More in 🧵

December 29, 2024 at 8:02 PM
I will be present our paper on LMs performance on long-context reasoning task at #EMNLP2024 (Tue 16:00-17:30; riverfront hall) Come and chat with us! 🧚🦋

November 11, 2024 at 5:21 PM
I will be present our paper on LMs performance on long-context reasoning task at #EMNLP2024 (Tue 16:00-17:30; riverfront hall) Come and chat with us! 🧚🦋
I really wanted to run NEW #nocha benchmark claims on #o1 but it won't behave 😠
- 6k reasoning tokens is often not enough to get an ans and more means being able to process only short books
- OpenAI adds sth to the prompt: ~8k extra tokens-> less room for book+reason+generation!
- 6k reasoning tokens is often not enough to get an ans and more means being able to process only short books
- OpenAI adds sth to the prompt: ~8k extra tokens-> less room for book+reason+generation!

November 11, 2024 at 5:11 PM