
Martin Klissarov
@martinklissarov.bsky.social
250 followers
110 following
18 posts
research @ Google DeepMind
Posts
Media
Videos
Starter Packs
Pinned





Reposted by Martin Klissarov

Edward Grefenstette
@egrefen.bsky.social
· Mar 18
Reposted by Martin Klissarov






Reposted by Martin Klissarov

Devon Hjelm
@devhje.bsky.social
· Jan 22

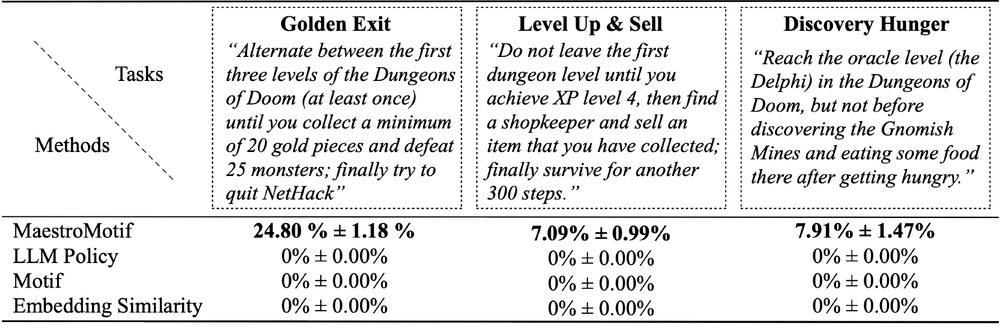
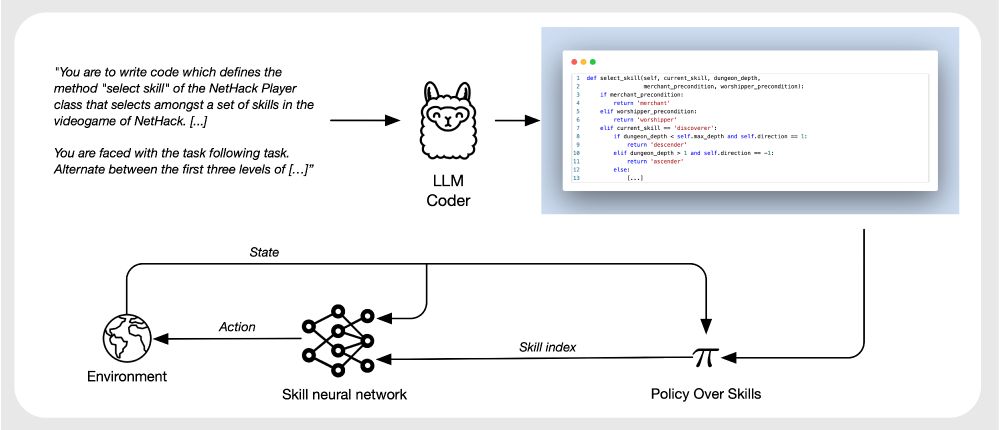
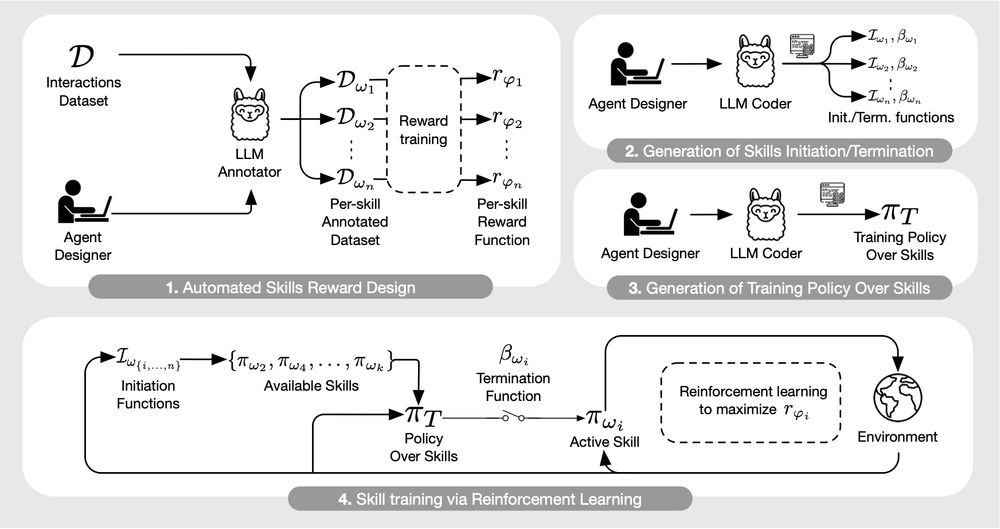
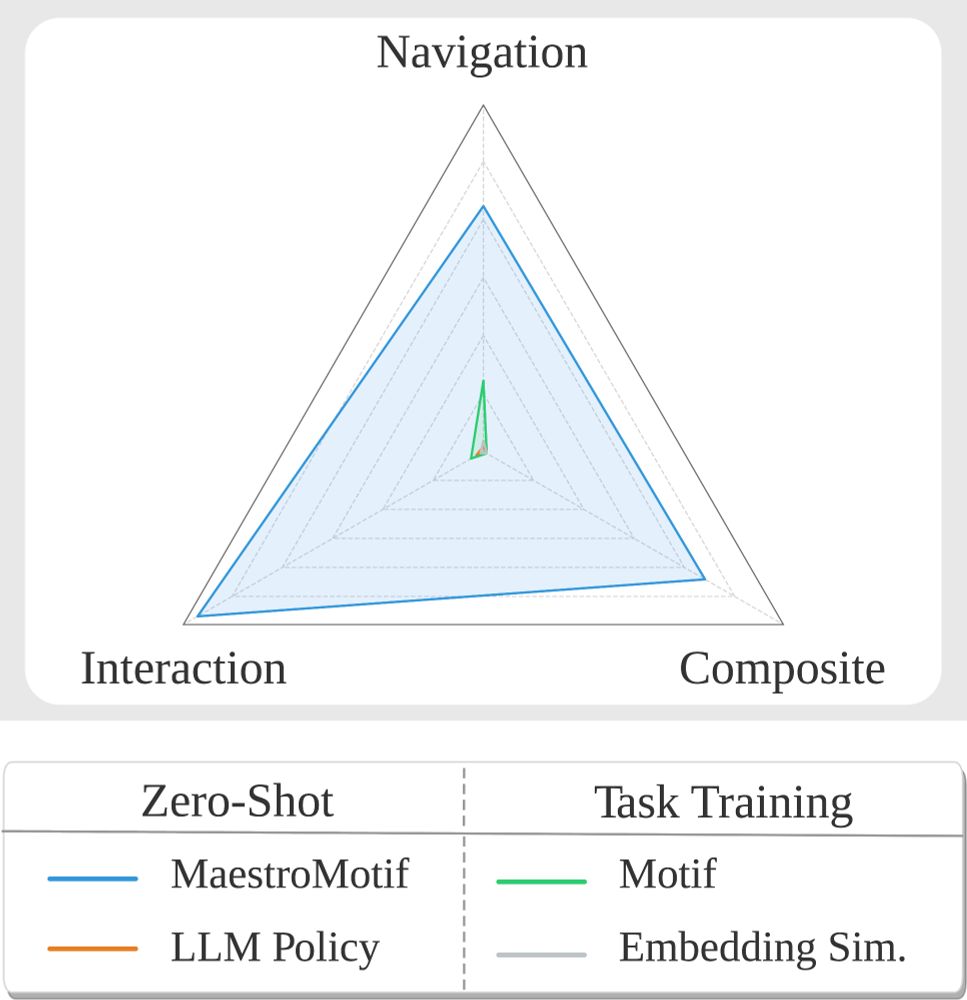
On the Modeling Capabilities of Large Language Models for Sequential Decision Making
Large pretrained models are showing increasingly better performance in reasoning and planning tasks across different modalities, opening the possibility to leverage them for complex sequential decisio...
arxiv.org
Reposted by Martin Klissarov
