




Martin Klissarov
@martinklissarov.bsky.social
research @ Google DeepMind
We are looking to continue to improve this manuscript, please share your feedback!
www.arxiv.org/abs/2506.14045
www.arxiv.org/abs/2506.14045

Discovering Temporal Structure: An Overview of Hierarchical Reinforcement Learning
Developing agents capable of exploring, planning and learning in complex open-ended environments is a grand challenge in artificial intelligence (AI). Hierarchical reinforcement learning (HRL) offers ...
www.arxiv.org
June 27, 2025 at 8:16 PM
We are looking to continue to improve this manuscript, please share your feedback!
www.arxiv.org/abs/2506.14045
www.arxiv.org/abs/2506.14045
This work was done over the course of many friendly virtual calls Akhil Bagaria and @ray-luo.bsky.social , and under the thoughtful guidance of researchers that have spent decades working on these problems, namely George Konidaris, Doina Precup and
@marloscmachado.bsky.social
@marloscmachado.bsky.social
June 27, 2025 at 8:16 PM
This work was done over the course of many friendly virtual calls Akhil Bagaria and @ray-luo.bsky.social , and under the thoughtful guidance of researchers that have spent decades working on these problems, namely George Konidaris, Doina Precup and
@marloscmachado.bsky.social
@marloscmachado.bsky.social
We hope this work provides a good introduction to the field.
Finding temporal structure is challenging. As such, we carefully laid down some of the most pressing questions in the field.
We also identified domains that are particularly promising, e.g. open-ended systems.
Finding temporal structure is challenging. As such, we carefully laid down some of the most pressing questions in the field.
We also identified domains that are particularly promising, e.g. open-ended systems.
June 27, 2025 at 8:16 PM
We hope this work provides a good introduction to the field.
Finding temporal structure is challenging. As such, we carefully laid down some of the most pressing questions in the field.
We also identified domains that are particularly promising, e.g. open-ended systems.
Finding temporal structure is challenging. As such, we carefully laid down some of the most pressing questions in the field.
We also identified domains that are particularly promising, e.g. open-ended systems.
We often get bogged down by differences in formalisms (goal-direction RL, options, feudal RL, skills …) -- we unite these core ideas through a single perspective.
We believe hierarchical RL is fundamentally about the algorithm through which we discover temporal structure.
We believe hierarchical RL is fundamentally about the algorithm through which we discover temporal structure.
June 27, 2025 at 8:16 PM
We often get bogged down by differences in formalisms (goal-direction RL, options, feudal RL, skills …) -- we unite these core ideas through a single perspective.
We believe hierarchical RL is fundamentally about the algorithm through which we discover temporal structure.
We believe hierarchical RL is fundamentally about the algorithm through which we discover temporal structure.
We cover methods that learn:
(1) directly from experience, (2) through offline datasets and (3) with foundation models (LLMs).
We present each methods through the fundamental challenges of decision making, namely:
(a) exploration (b) credit assignment and (c) transferability
(1) directly from experience, (2) through offline datasets and (3) with foundation models (LLMs).
We present each methods through the fundamental challenges of decision making, namely:
(a) exploration (b) credit assignment and (c) transferability

June 27, 2025 at 8:16 PM
We cover methods that learn:
(1) directly from experience, (2) through offline datasets and (3) with foundation models (LLMs).
We present each methods through the fundamental challenges of decision making, namely:
(a) exploration (b) credit assignment and (c) transferability
(1) directly from experience, (2) through offline datasets and (3) with foundation models (LLMs).
We present each methods through the fundamental challenges of decision making, namely:
(a) exploration (b) credit assignment and (c) transferability
In this 80+ pages manuscript, we cover the rich, diverse and many-decades old literature studying temporal structure discovery in AI.
When and in what way should we expect these methods to benefit agents? What are the trade-offs involved?
When and in what way should we expect these methods to benefit agents? What are the trade-offs involved?

June 27, 2025 at 8:16 PM
In this 80+ pages manuscript, we cover the rich, diverse and many-decades old literature studying temporal structure discovery in AI.
When and in what way should we expect these methods to benefit agents? What are the trade-offs involved?
When and in what way should we expect these methods to benefit agents? What are the trade-offs involved?
Humans constantly leverage temporal structure: we actuate muscles each millisecond, yet our plans can span days, months and even years.
Computers are built on this same principle.
How will AI agents discover and use such structure? What is "good" structure in the first place?
Computers are built on this same principle.
How will AI agents discover and use such structure? What is "good" structure in the first place?

June 27, 2025 at 8:16 PM
Humans constantly leverage temporal structure: we actuate muscles each millisecond, yet our plans can span days, months and even years.
Computers are built on this same principle.
How will AI agents discover and use such structure? What is "good" structure in the first place?
Computers are built on this same principle.
How will AI agents discover and use such structure? What is "good" structure in the first place?
This work was done with the amazing Mikael Henaff, Roberta Raileanu, Shagun Sodhani, Pascal Vincent, Amy Zhang, @pierrelucbacon.bsky.social , Doina Precup, with equal supervision by @marloscmachado.bsky.social and @proceduralia.bsky.social .
February 4, 2025 at 7:22 PM
This work was done with the amazing Mikael Henaff, Roberta Raileanu, Shagun Sodhani, Pascal Vincent, Amy Zhang, @pierrelucbacon.bsky.social , Doina Precup, with equal supervision by @marloscmachado.bsky.social and @proceduralia.bsky.social .
Finally, we analyze the choice of the LLM used to write code policies. We notice a scaling behaviour wherein only the largest LLM , Llama 3.1 405b, was able to define successful policies on all tasks.
With the advent of thinking models, it would be interesting to further investigate this.
With the advent of thinking models, it would be interesting to further investigate this.

February 4, 2025 at 7:22 PM
Finally, we analyze the choice of the LLM used to write code policies. We notice a scaling behaviour wherein only the largest LLM , Llama 3.1 405b, was able to define successful policies on all tasks.
With the advent of thinking models, it would be interesting to further investigate this.
With the advent of thinking models, it would be interesting to further investigate this.
An interesting discovery we came across was how the skills that were learned naturally emerged in a form of curriculum. Easier skills are the first to maximize their skill reward, paving the way for more complex skills to be learned.
TL;DR: Hierarchy affords learnability.
TL;DR: Hierarchy affords learnability.

February 4, 2025 at 7:22 PM
An interesting discovery we came across was how the skills that were learned naturally emerged in a form of curriculum. Easier skills are the first to maximize their skill reward, paving the way for more complex skills to be learned.
TL;DR: Hierarchy affords learnability.
TL;DR: Hierarchy affords learnability.
A few years back, AI researchers (Heinrich Kuttler, @egrefen.bsky.social and @rockt.ai to name a few) foresaw the importance of such an environment and created the NetHack Learning Environment, which allows for experimenting with RL agents.
February 4, 2025 at 7:22 PM
A few years back, AI researchers (Heinrich Kuttler, @egrefen.bsky.social and @rockt.ai to name a few) foresaw the importance of such an environment and created the NetHack Learning Environment, which allows for experimenting with RL agents.
Evaluations in such complex tasks is only possibly thanks to the work of dedicated fans of NetHack, who have been building and upgrading the game since 1987 (it is still an ongoing and maintained repository). We show in this figure some of the complexities of NetHack.

February 4, 2025 at 7:22 PM
Evaluations in such complex tasks is only possibly thanks to the work of dedicated fans of NetHack, who have been building and upgrading the game since 1987 (it is still an ongoing and maintained repository). We show in this figure some of the complexities of NetHack.
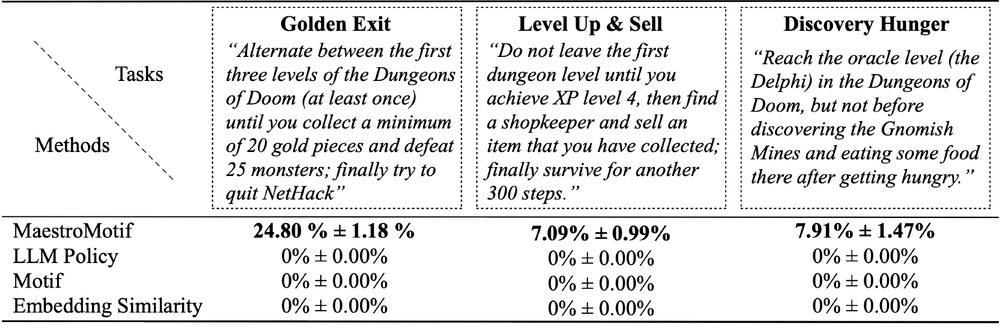
We highlight the complexity of some of these tasks, which on average take more than a thousand steps for completion. Even methods that are trained specifically for each task are not able to make any kind of progress.
February 4, 2025 at 7:22 PM
We highlight the complexity of some of these tasks, which on average take more than a thousand steps for completion. Even methods that are trained specifically for each task are not able to make any kind of progress.
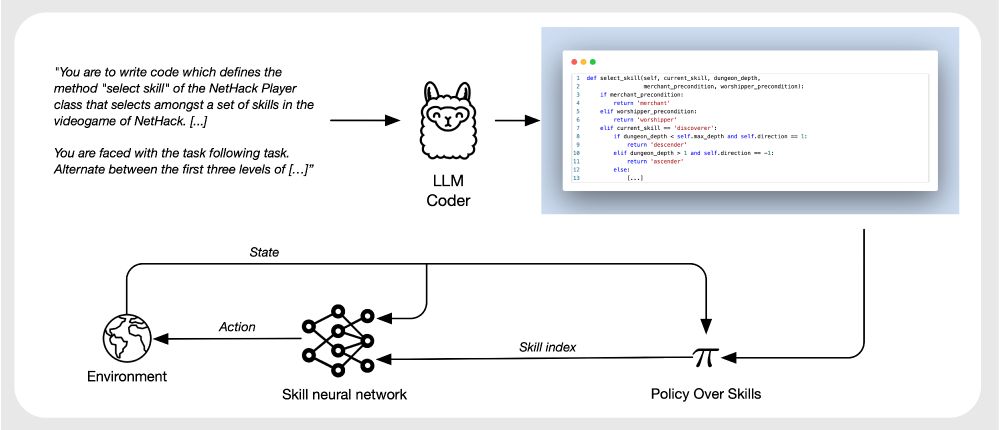
Once the skill policies are learned, MaestroMotif can adapt, zero-shot, to new instructions and solve complex tasks simply by re-combining skills, similarly to motifs in a composition. In other words, it writes a different code policy over skills which achieves a completely different task.
February 4, 2025 at 7:22 PM
Once the skill policies are learned, MaestroMotif can adapt, zero-shot, to new instructions and solve complex tasks simply by re-combining skills, similarly to motifs in a composition. In other words, it writes a different code policy over skills which achieves a completely different task.
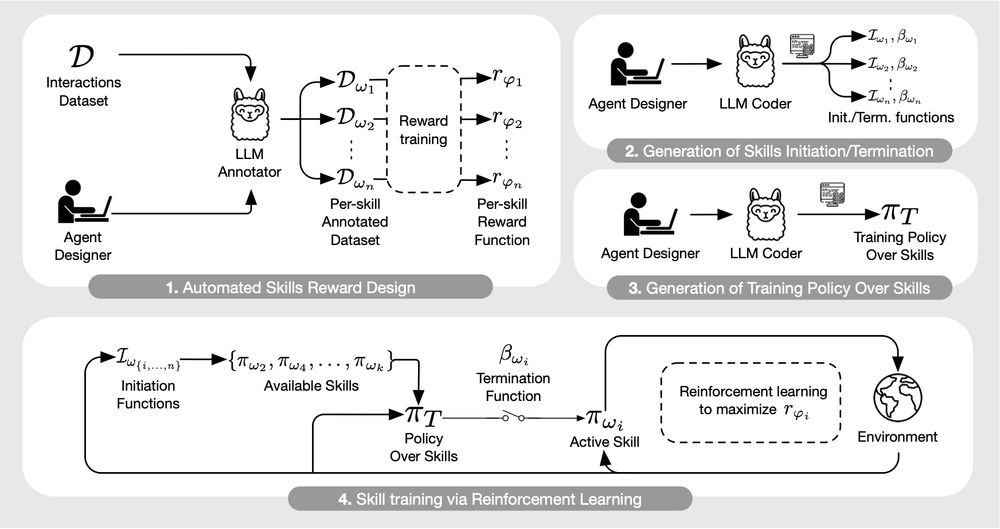
MaestroMotif is a scalable and effective algorithm for AI assisted skill design. It starts by leveraging an agent designer’s prior knowledge about a domain who defines a set of useful skills, or agents. Agents here are described on a high level in natural language.
February 4, 2025 at 7:22 PM
MaestroMotif is a scalable and effective algorithm for AI assisted skill design. It starts by leveraging an agent designer’s prior knowledge about a domain who defines a set of useful skills, or agents. Agents here are described on a high level in natural language.
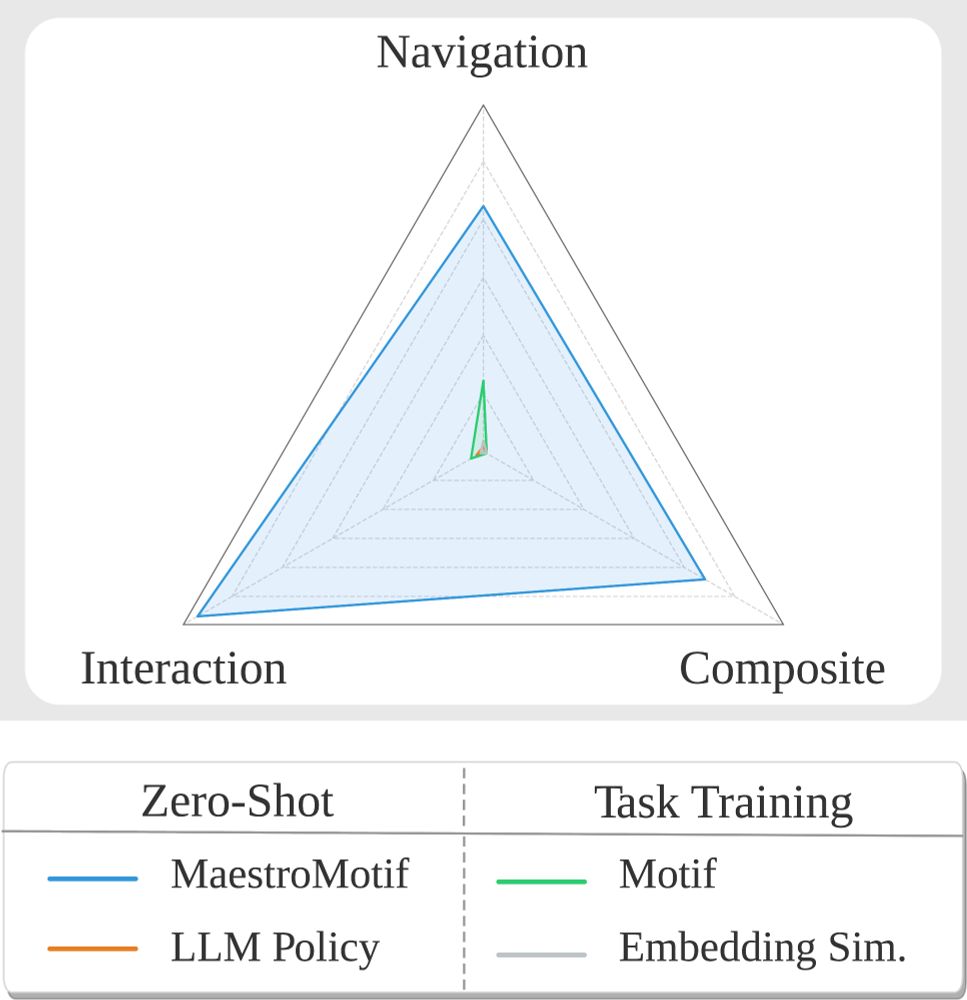
MaestroMotif builds on our previous work, Motif, which pioneered learning RL policies from AI feedback. At the time, it set a new state-of-the-art on the open-ended domain of NetHack. With MaestroMotif, we improve on this performance by two orders of magnitude. But, how are these gains obtained?
February 4, 2025 at 7:22 PM
MaestroMotif builds on our previous work, Motif, which pioneered learning RL policies from AI feedback. At the time, it set a new state-of-the-art on the open-ended domain of NetHack. With MaestroMotif, we improve on this performance by two orders of magnitude. But, how are these gains obtained?