Max Seitzer
@maxseitzer.bsky.social
65 followers
39 following
11 posts
Research Scientist in the DINO team at Meta FAIR. Previously: PhD at Max-Planck Institute for Intelligent Systems, Tübingen. Representation learning, agents, structure.
Posts
Media
Videos
Starter Packs
Pinned







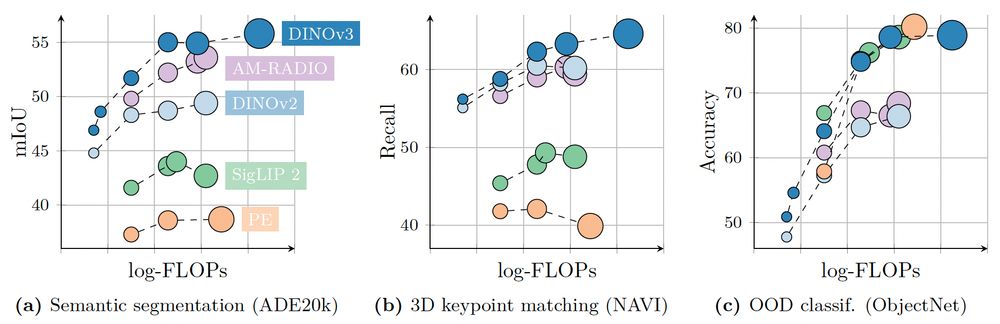

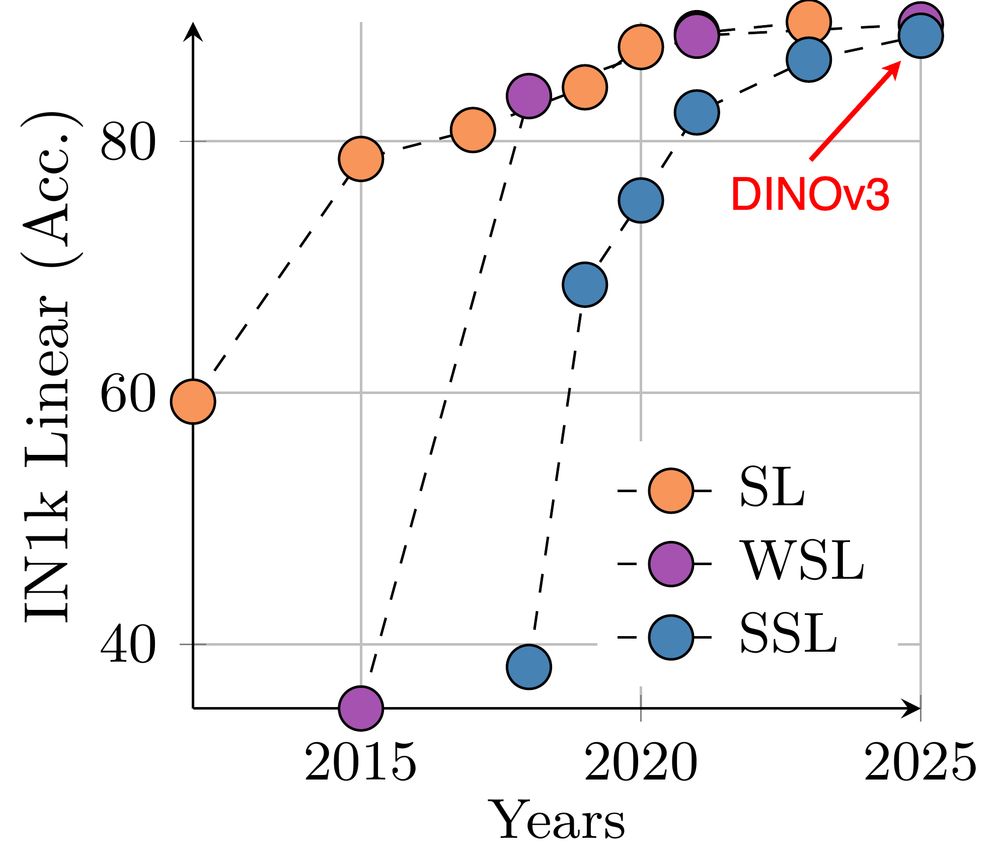
Max Seitzer
@maxseitzer.bsky.social
· Aug 14


Reposted by Max Seitzer

Reposted by Max Seitzer


Reposted by Max Seitzer
