micha heilbron
@mheilbron.bsky.social
780 followers
320 following
64 posts
Assistant Professor of Cognitive AI @UvA Amsterdam
language and vision in brains & machines
cognitive science 🤝 AI 🤝 cognitive neuroscience
michaheilbron.github.io
Posts
Media
Videos
Starter Packs



micha heilbron
@mheilbron.bsky.social
· Aug 18
micha heilbron
@mheilbron.bsky.social
· Aug 18




micha heilbron
@mheilbron.bsky.social
· Aug 18
micha heilbron
@mheilbron.bsky.social
· Aug 18
micha heilbron
@mheilbron.bsky.social
· Aug 18

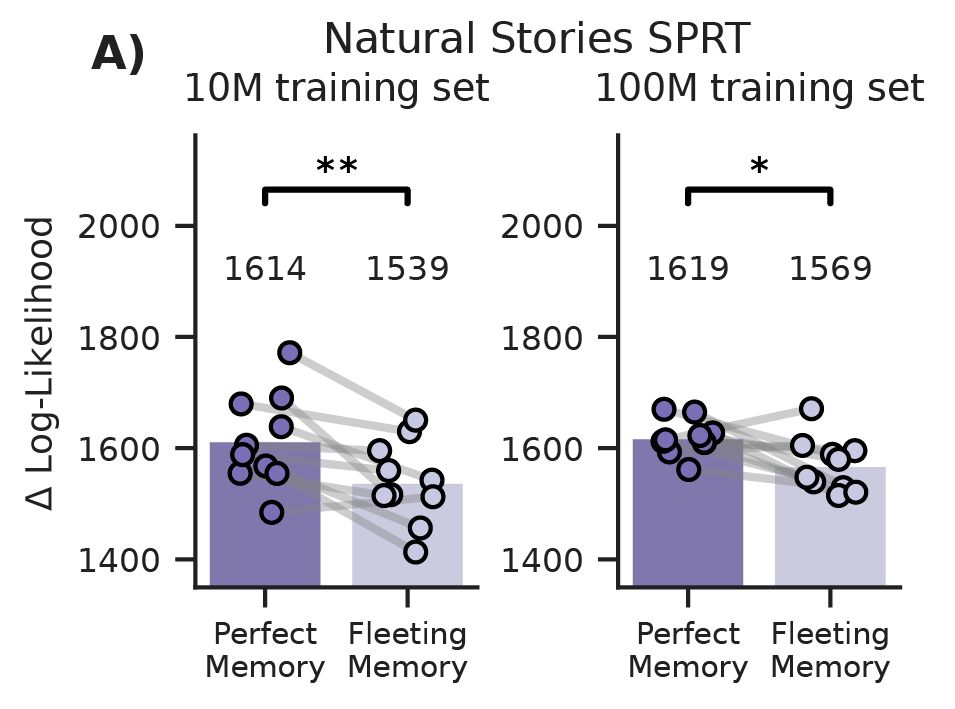
Human-like fleeting memory improves language learning but impairs reading time prediction in transformer language models
Human memory is fleeting. As words are processed, the exact wordforms that make up incoming sentences are rapidly lost. Cognitive scientists have long believed that this limitation of memory may, para...
arxiv.org


Reposted by micha heilbron

Reposted by micha heilbron
micha heilbron
@mheilbron.bsky.social
· May 23

Higher-level spatial prediction in natural vision across mouse visual cortex
Theories of predictive processing propose that sensory systems constantly predict incoming signals, based on spatial and temporal context. However, evidence for prediction in sensory cortex largely co...
www.biorxiv.org
micha heilbron
@mheilbron.bsky.social
· May 23
micha heilbron
@mheilbron.bsky.social
· May 23
micha heilbron
@mheilbron.bsky.social
· May 23
micha heilbron
@mheilbron.bsky.social
· May 23