Michael Hanna
@michaelwhanna.bsky.social
720 followers
350 following
14 posts
PhD Student at the ILLC / UvA doing work at the intersection of (mechanistic) interpretability and cognitive science. Current Anthropic Fellow.
hannamw.github.io
Posts
Media
Videos
Starter Packs

Michael Hanna
@michaelwhanna.bsky.social
· Apr 30

Reposted by Michael Hanna


Reposted by Michael Hanna
Aaron Mueller
@amuuueller.bsky.social
· Mar 11

Incremental Sentence Processing Mechanisms in Autoregressive Transformer Language Models
Autoregressive transformer language models (LMs) possess strong syntactic abilities, often successfully handling phenomena from agreement to NPI licensing. However, the features they use to incrementa...
arxiv.org
Reposted by Michael Hanna


Michael Hanna
@michaelwhanna.bsky.social
· Jan 24
Reposted by Michael Hanna


Michael Hanna
@michaelwhanna.bsky.social
· Dec 19

Incremental Sentence Processing Mechanisms in Autoregressive Transformer Language Models
Autoregressive transformer language models (LMs) possess strong syntactic abilities, often successfully handling phenomena from agreement to NPI licensing. However, the features they use to incrementa...
arxiv.org
Michael Hanna
@michaelwhanna.bsky.social
· Dec 19
Michael Hanna
@michaelwhanna.bsky.social
· Dec 19
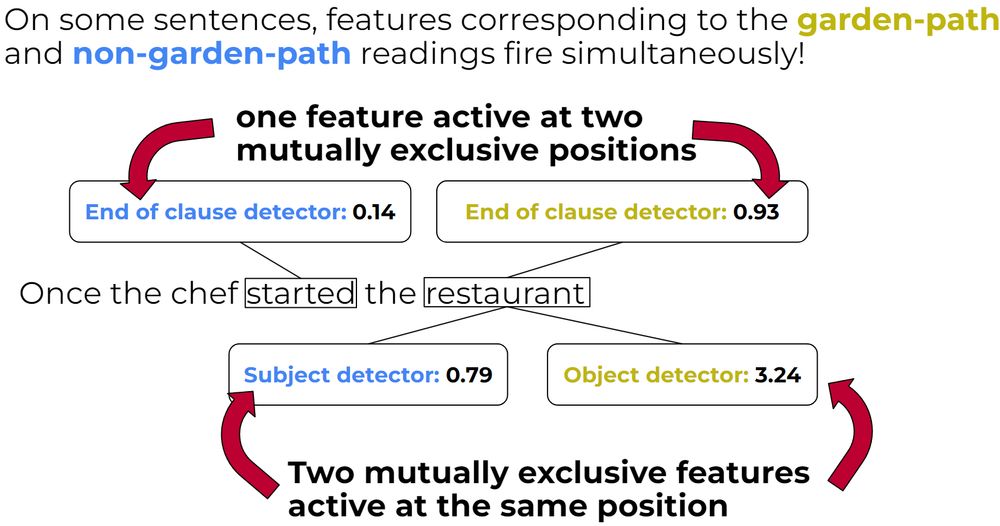



Michael Hanna
@michaelwhanna.bsky.social
· Dec 19

Reposted by Michael Hanna

Michael Hanna
@michaelwhanna.bsky.social
· Nov 26
Michael Hanna
@michaelwhanna.bsky.social
· Nov 22