Ofir Press
@ofirpress.bsky.social
650 followers
380 following
24 posts
I develop tough benchmarks for LMs and then I build agents to try and beat those benchmarks. Postdoc @ Princeton University.
https://ofir.io/about
Posts
Media
Videos
Starter Packs
Reposted by Ofir Press




Reposted by Ofir Press





Reposted by Ofir Press





Reposted by Ofir Press

Ofir Press
@ofirpress.bsky.social
· Dec 20
Ofir Press
@ofirpress.bsky.social
· Dec 19

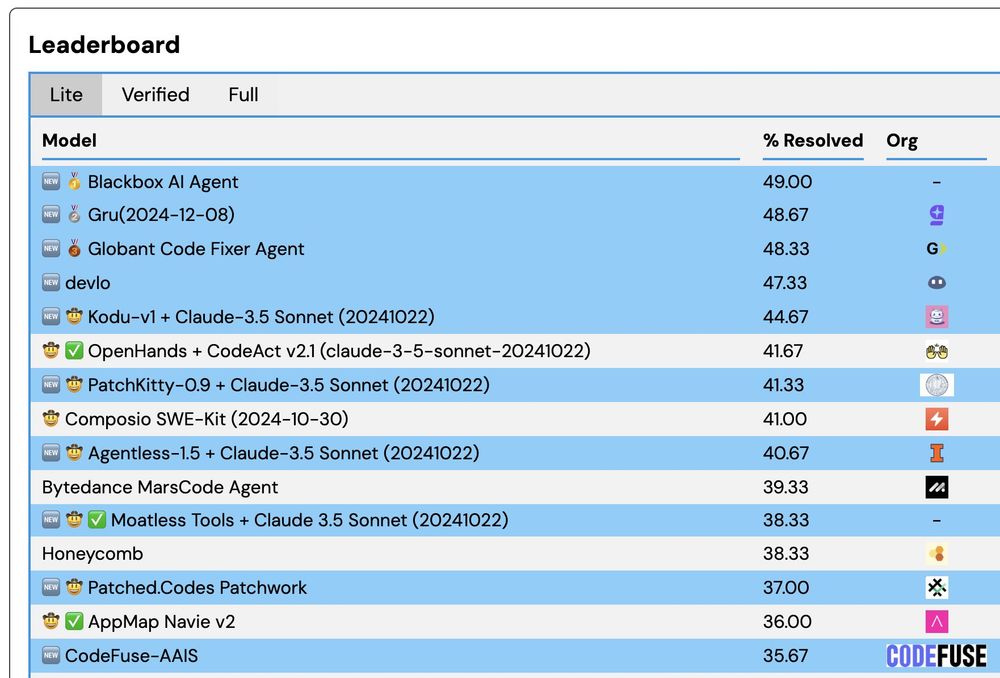
SWT-Bench: Assessing capabilities at Unit Test Generation
Check out the SWT-Bench leaderboard! SWT-Bench is a benchmark designed to assess the capabilities of large language models and Code Agents in generating unit tests on real-world code repositories, dev...
swtbench.com
Ofir Press
@ofirpress.bsky.social
· Dec 18
Ofir Press
@ofirpress.bsky.social
· Dec 18
Reposted by Ofir Press




Reposted by Ofir Press


