
Jon Barron
@jonbarron.bsky.social
3.6K followers
150 following
250 posts
AI researcher at Google DeepMind. Synthesized views are my own.
📍SF Bay Area 🔗 http://jonbarron.info
This feed is a partial mirror of https://twitter.com/jon_barron
Posts
Media
Videos
Starter Packs

Reposted by Jon Barron


Reposted by Jon Barron


Jon Barron
@jonbarron.bsky.social
· Jul 3
Jon Barron
@jonbarron.bsky.social
· Jul 3
Jon Barron
@jonbarron.bsky.social
· Jul 3
Jon Barron
@jonbarron.bsky.social
· Jun 29
Reposted by Jon Barron


Reposted by Jon Barron

Jon Barron
@jonbarron.bsky.social
· Apr 9
Jon Barron
@jonbarron.bsky.social
· Apr 8
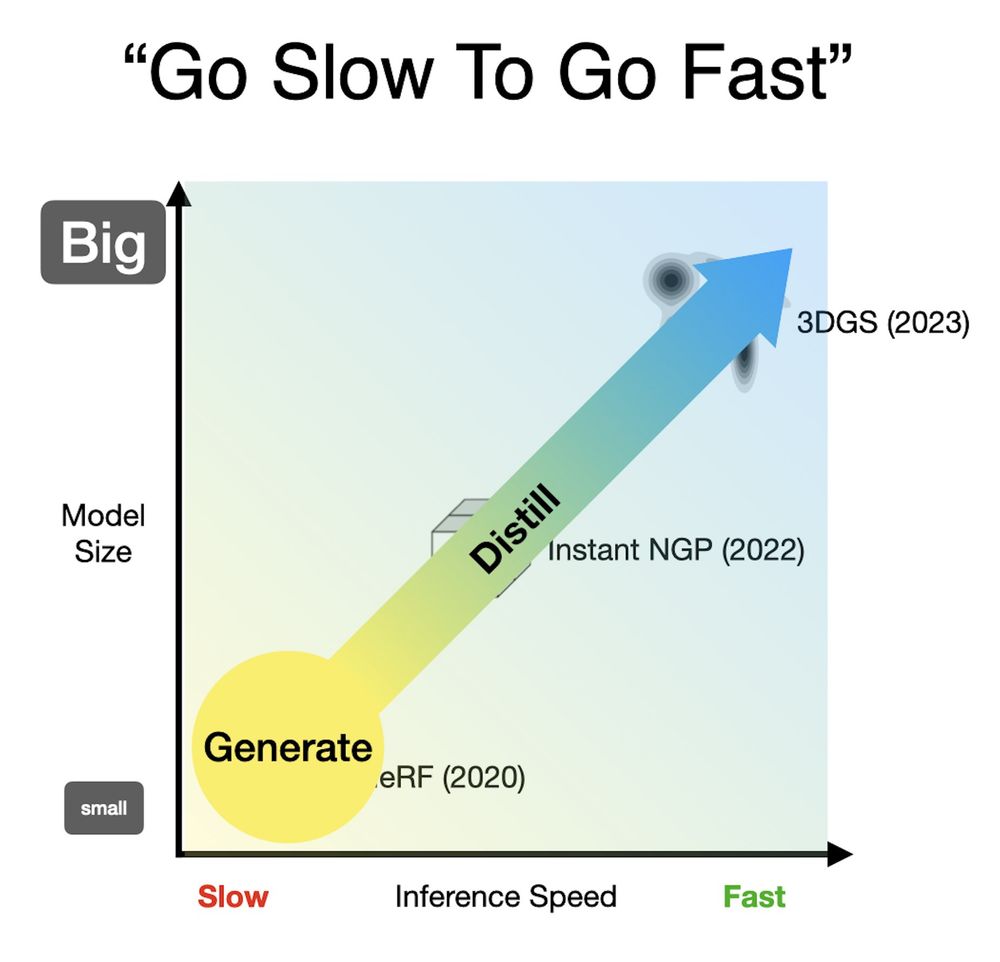
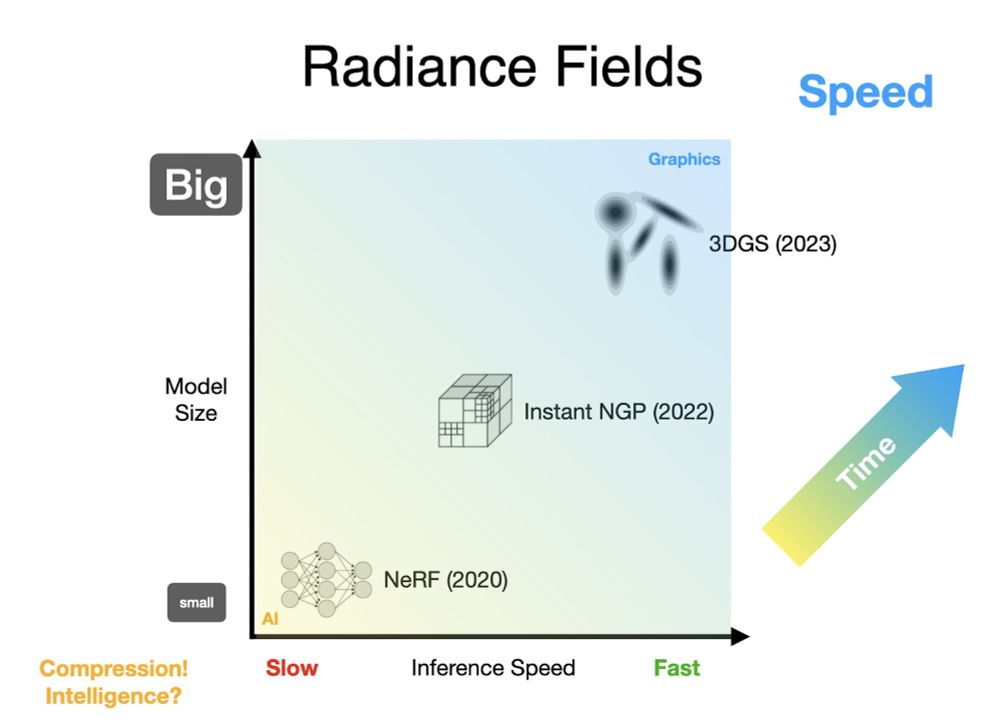
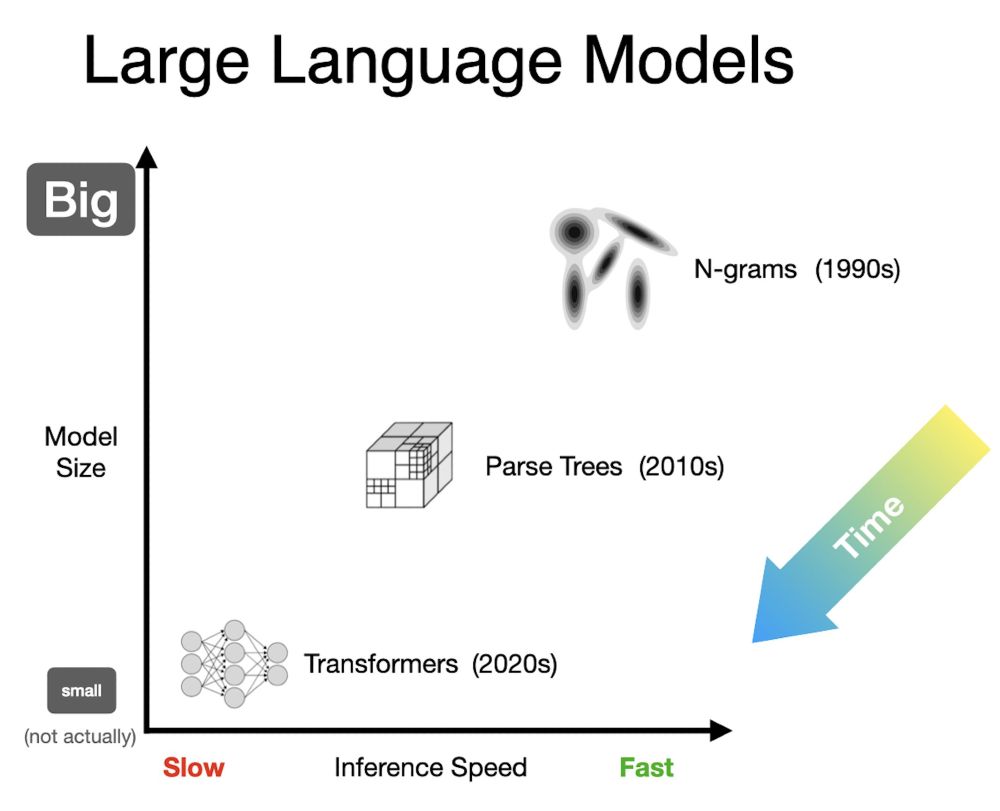
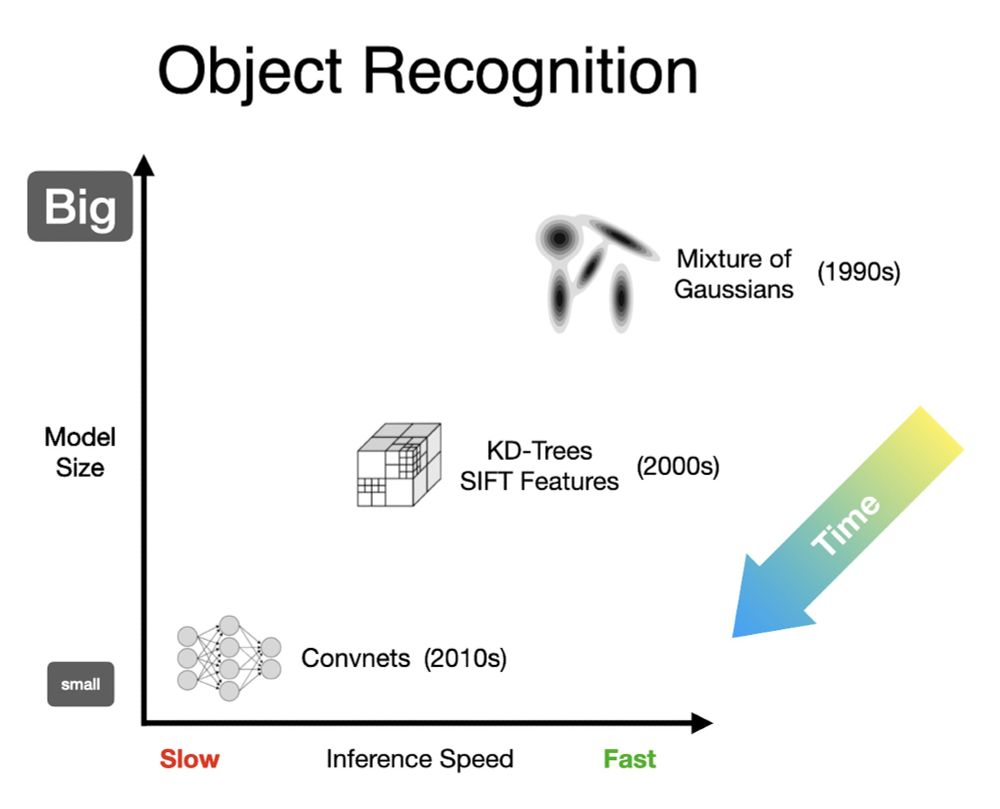
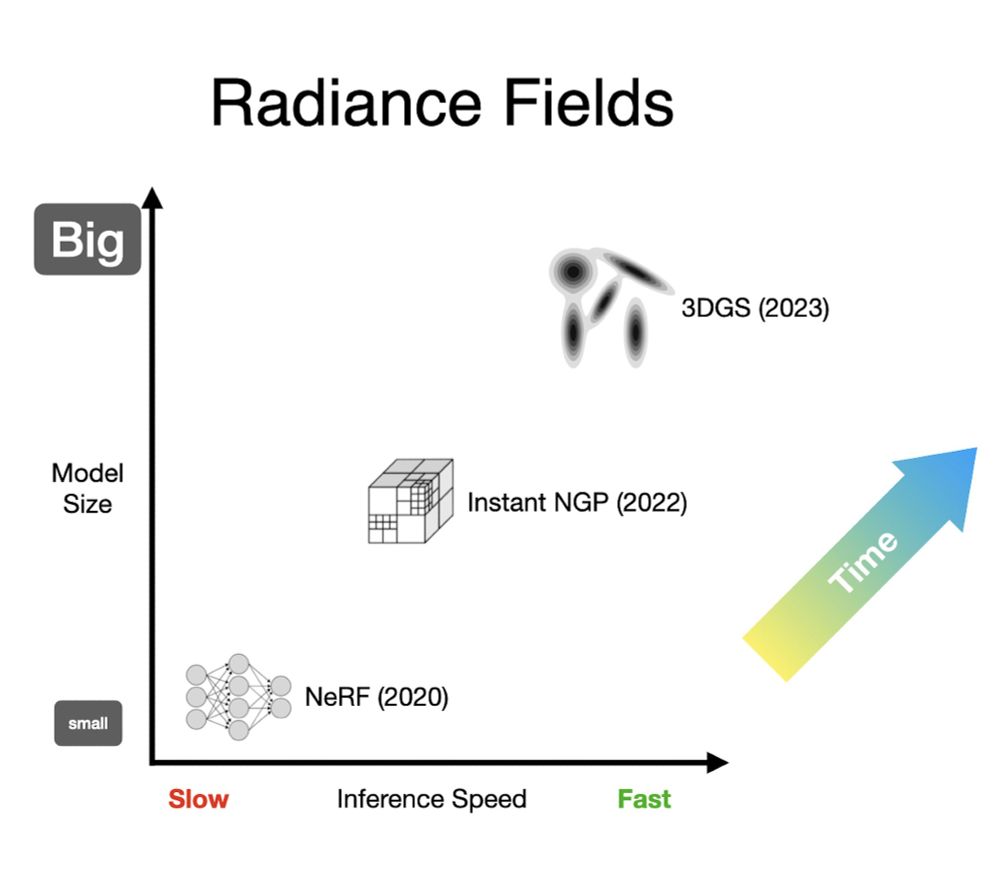



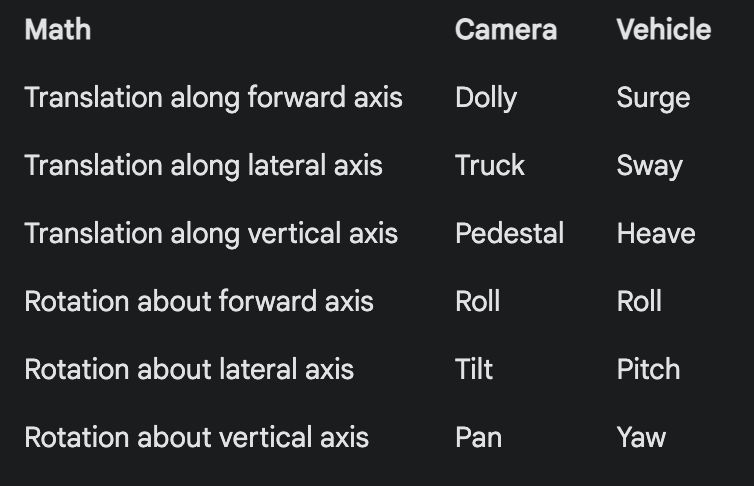
Jon Barron
@jonbarron.bsky.social
· Mar 11
Jon Barron
@jonbarron.bsky.social
· Mar 3