

Jan-Ole Koslik
@olemole.bsky.social
280 followers
940 following
13 posts
PhD student 🎓 in Statistics at Bielefeld University interested in doubly stochastic processes and their application to ecology 🦅, sports 🏈, and finance 📈.
Website: https://janoleko.github.io
GitHub: https://github.com/janoleko
Posts
Media
Videos
Starter Packs

Jan-Ole Koslik
@olemole.bsky.social
· Sep 5
Fast Numerical Maximum Likelihood Estimation for Latent Markov Models
A variety of latent Markov models, including hidden Markov models, hidden semi-Markov models, state-space models and continuous-time variants can be formulated and estimated within the same framework ...
janoleko.github.io
Reposted by Jan-Ole Koslik

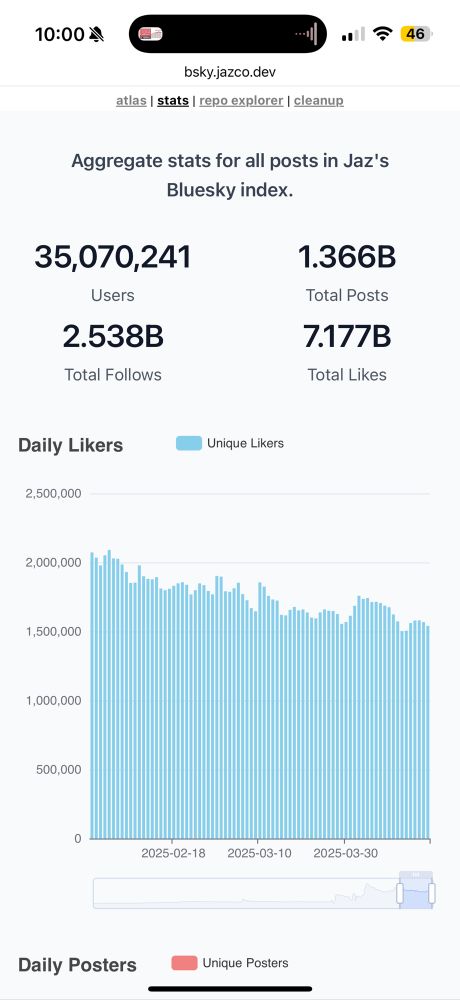
Jan-Ole Koslik
@olemole.bsky.social
· Mar 19
Fast Numerical Maximum Likelihood Estimation for Latent Markov Models
A variety of latent Markov models, including hidden Markov models, hidden semi-Markov models, state-space models and continuous-time variants can be formulated and estimated within the same framework ...
janoleko.github.io

Reposted by Jan-Ole Koslik





Reposted by Jan-Ole Koslik


Reposted by Jan-Ole Koslik

Reposted by Jan-Ole Koslik


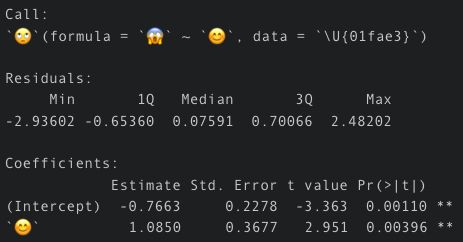
Reposted by Jan-Ole Koslik

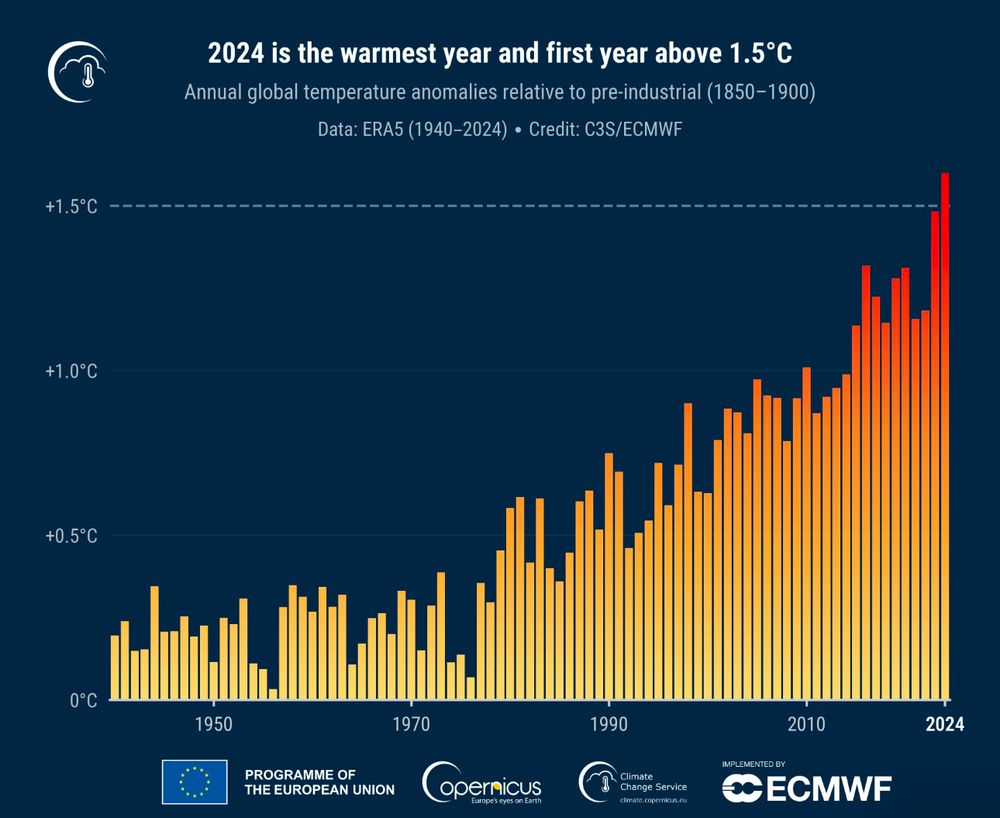
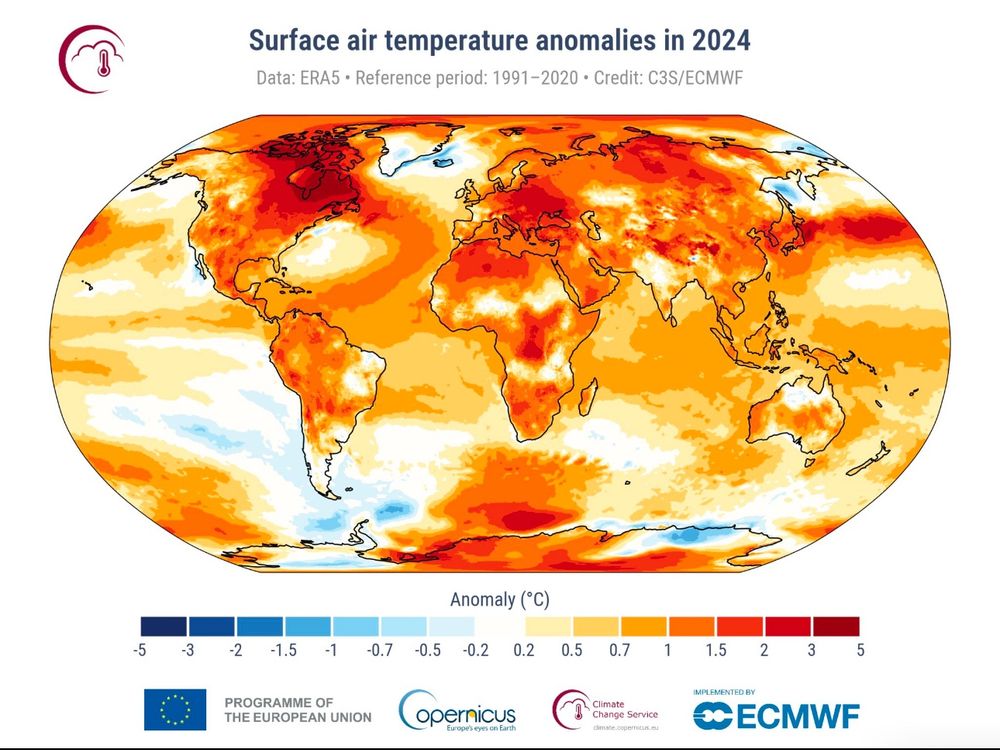
Reposted by Jan-Ole Koslik


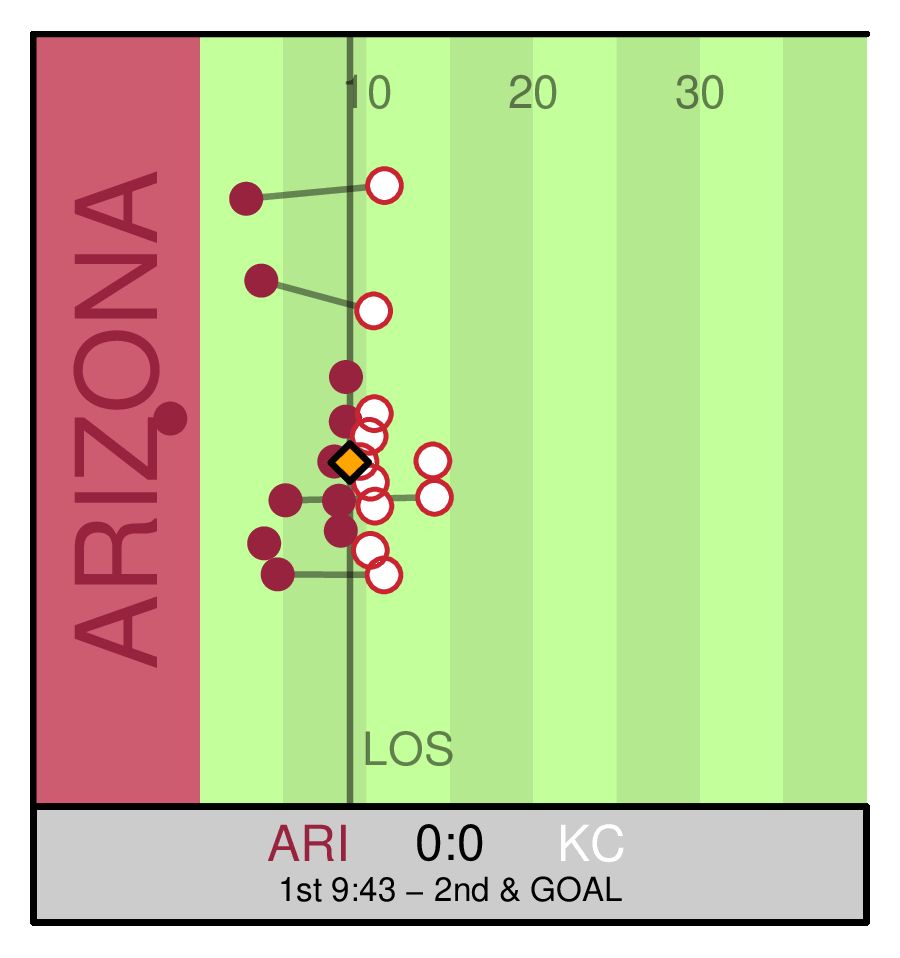
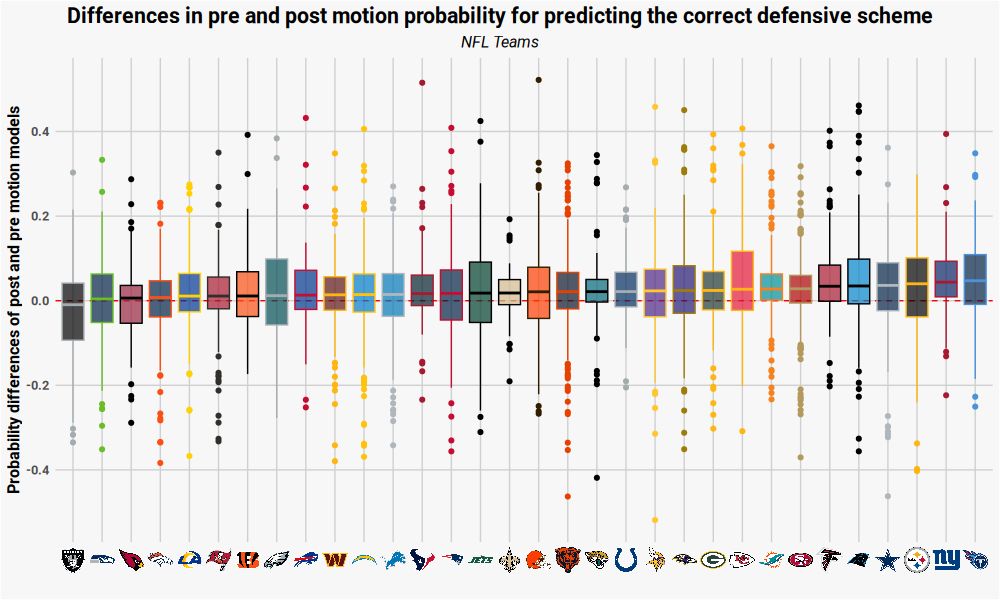
Reposted by Jan-Ole Koslik

Reposted by Jan-Ole Koslik

![Example
With a matrix
> x <- matrix(rnorm(20 * 500), nrow = 20, ncol = 500)
it is many times faster to calculate medians column by column using
> mu <- matrixStats::colMedians(x)
than using
> mu <- apply(x, MARGIN = 2, FUN = median)
Moreover, if performing calculations on a subset of rows and/or columns, using
> mu <- colMedians(x, rows = 33:158, cols = 1001:3000)
is much faster and more memory efficient than
> mu <- apply(x[33:158, 1001:3000], MARGIN = 2, FUN = median)](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:z4cp3uwgxiioi7uaxn2boq47/bafkreia5r4zydpx435mcoo4gbd2halv3uhaqw4pywcpwkwtrjla4tyjvoq@jpeg)

Jan-Ole Koslik
@olemole.bsky.social
· Dec 30

Jan-Ole Koslik
@olemole.bsky.social
· Dec 30

Reposted by Jan-Ole Koslik


Reposted by Jan-Ole Koslik


Reposted by Jan-Ole Koslik


Reposted by Jan-Ole Koslik

