



Orion Weller
@orionweller.bsky.social
PhD Student at Johns Hopkins University. Previously: Allen Institute for AI, Apple, Samaya AI. Research for #NLProc #IR
Ever wonder how test-time compute would do in retrieval? 🤔
introducing ✨rank1✨
rank1 is distilled from R1 & designed for reranking.
rank1 is state-of-the-art at complex reranking tasks in reasoning, instruction-following, and general semantics (often 2x RankLlama 🤯)
🧵
introducing ✨rank1✨
rank1 is distilled from R1 & designed for reranking.
rank1 is state-of-the-art at complex reranking tasks in reasoning, instruction-following, and general semantics (often 2x RankLlama 🤯)
🧵


February 26, 2025 at 2:57 PM
Ever wonder how test-time compute would do in retrieval? 🤔
introducing ✨rank1✨
rank1 is distilled from R1 & designed for reranking.
rank1 is state-of-the-art at complex reranking tasks in reasoning, instruction-following, and general semantics (often 2x RankLlama 🤯)
🧵
introducing ✨rank1✨
rank1 is distilled from R1 & designed for reranking.
rank1 is state-of-the-art at complex reranking tasks in reasoning, instruction-following, and general semantics (often 2x RankLlama 🤯)
🧵
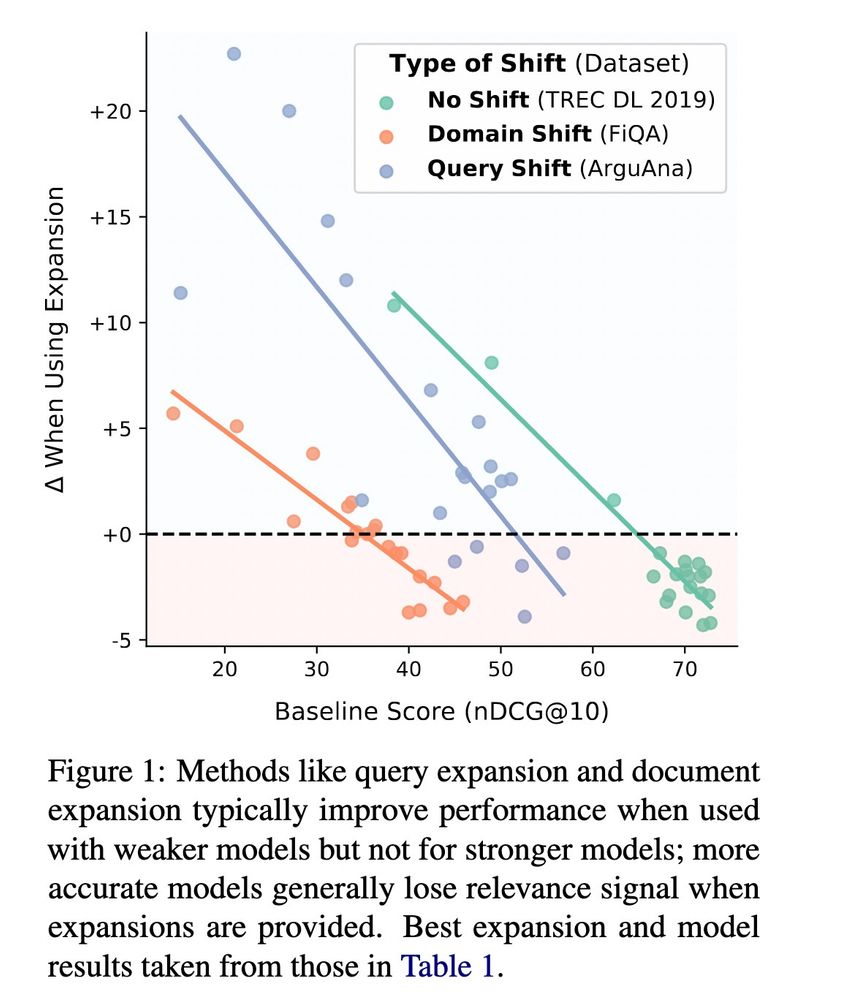
Why is this the case? Weaker IR models benefit from the additional information provided by LLMs (e.g. recall) but strong IR models (like large rerankers) lose information they need when ranking the top documents (e.g. precision).

November 18, 2024 at 10:30 AM
Why is this the case? Weaker IR models benefit from the additional information provided by LLMs (e.g. recall) but strong IR models (like large rerankers) lose information they need when ranking the top documents (e.g. precision).
We show that this finding holds both in-domain and for 4 different types of distribution shift (domain, relevance, long queries, short docs) across 12 datasets.
Interestingly, these effects are the least strong on long query shift (e.g. paragraph+ sized queries, a la ArguAna).
Interestingly, these effects are the least strong on long query shift (e.g. paragraph+ sized queries, a la ArguAna).




November 18, 2024 at 10:30 AM
We show that this finding holds both in-domain and for 4 different types of distribution shift (domain, relevance, long queries, short docs) across 12 datasets.
Interestingly, these effects are the least strong on long query shift (e.g. paragraph+ sized queries, a la ArguAna).
Interestingly, these effects are the least strong on long query shift (e.g. paragraph+ sized queries, a la ArguAna).
We conduct a comprehensive evaluation on when you should use LLM-based query and doc expansion.
It turns out there's a strong and consistent negative correlation between model performance and gains from using expansion. And it holds for all 20+ rankers we tested!
It turns out there's a strong and consistent negative correlation between model performance and gains from using expansion. And it holds for all 20+ rankers we tested!

November 18, 2024 at 10:30 AM
We conduct a comprehensive evaluation on when you should use LLM-based query and doc expansion.
It turns out there's a strong and consistent negative correlation between model performance and gains from using expansion. And it holds for all 20+ rankers we tested!
It turns out there's a strong and consistent negative correlation between model performance and gains from using expansion. And it holds for all 20+ rankers we tested!
Using LLMs for query or document expansion in retrieval (e.g. HyDE and Doc2Query) have scores going 📈
But do these approaches work for all IR models and for different types of distribution shifts? Turns out its actually more 📉 🚨
📝 (arxiv soon): orionweller.github.io/assets/pdf/L...
But do these approaches work for all IR models and for different types of distribution shifts? Turns out its actually more 📉 🚨
📝 (arxiv soon): orionweller.github.io/assets/pdf/L...
November 18, 2024 at 10:30 AM
Using LLMs for query or document expansion in retrieval (e.g. HyDE and Doc2Query) have scores going 📈
But do these approaches work for all IR models and for different types of distribution shifts? Turns out its actually more 📉 🚨
📝 (arxiv soon): orionweller.github.io/assets/pdf/L...
But do these approaches work for all IR models and for different types of distribution shifts? Turns out its actually more 📉 🚨
📝 (arxiv soon): orionweller.github.io/assets/pdf/L...