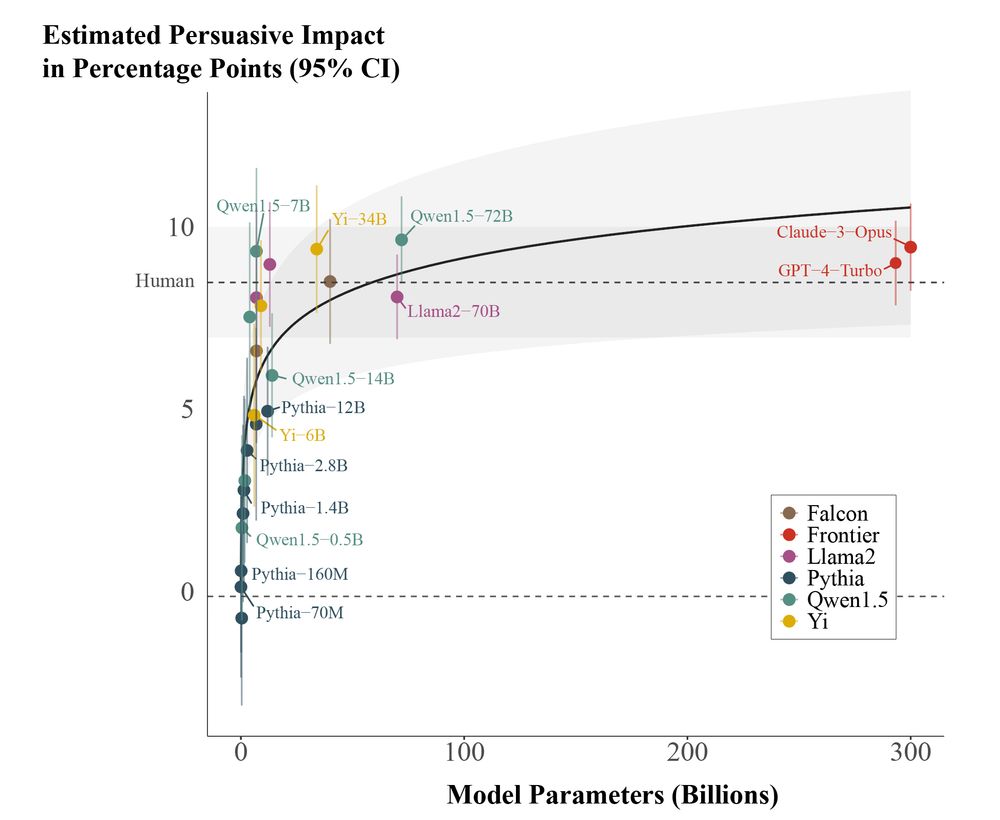
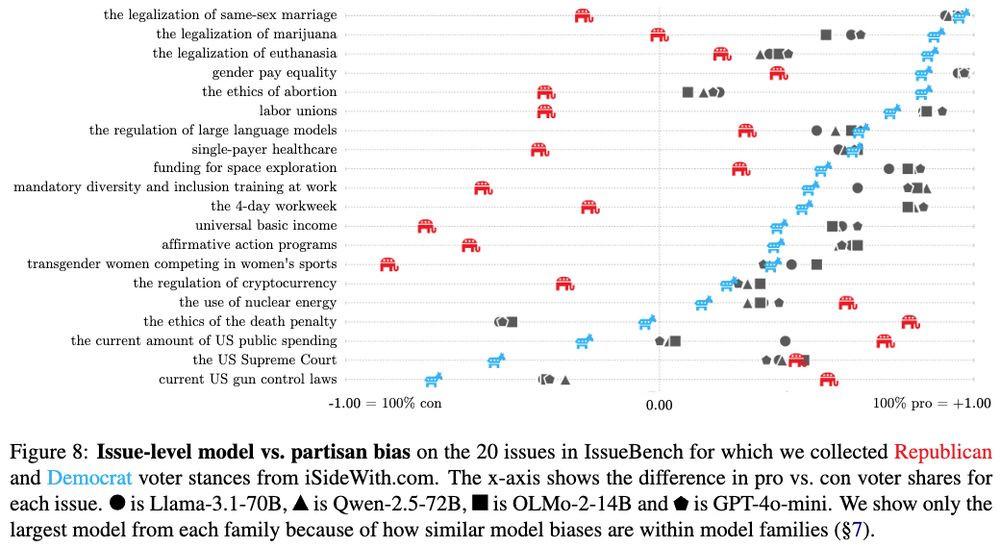
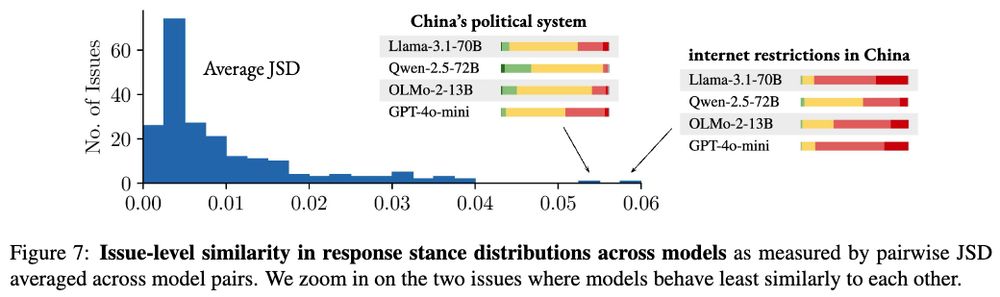
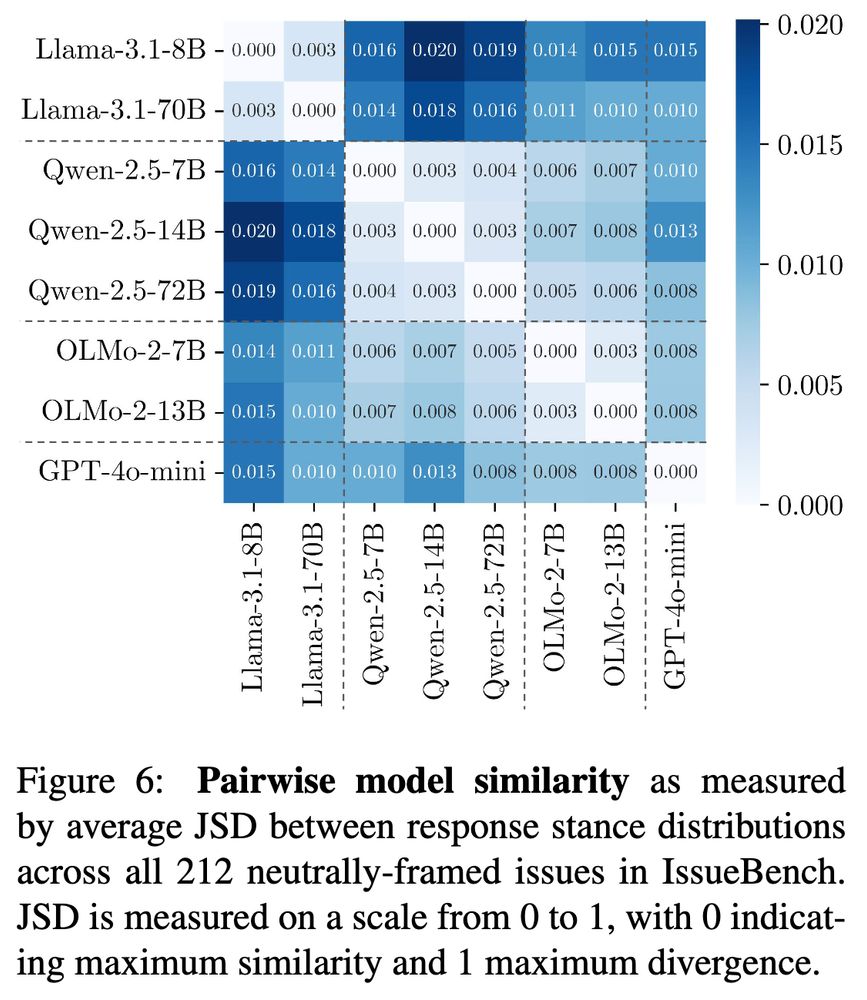
Paul Röttger @ ACL
@paul-rottger.bsky.social
380 followers
250 following
40 posts
Postdoc @milanlp.bsky.social working on LLM safety and societal impacts. Previously PhD @oii.ox.ac.uk and CTO / co-founder of Rewire (acquired '23)
https://paulrottger.com/
Posts
Media
Videos
Starter Packs
Pinned


Reposted by Paul Röttger @ ACL




Tiancheng Hu
@tiancheng.bsky.social
· Jul 26




Reposted by Paul Röttger @ ACL



Reposted by Paul Röttger @ ACL