Pietro Lesci
@pietrolesci.bsky.social
250 followers
1K following
23 posts
PhD student at Cambridge University. Causality & language models. Passionate musician, professional debugger.
pietrolesci.github.io
Posts
Media
Videos
Starter Packs


Reposted by Pietro Lesci

Tiago Pimentel
@tpimentel.bsky.social
· Jul 27

Reposted by Pietro Lesci





Pietro Lesci
@pietrolesci.bsky.social
· Jul 27
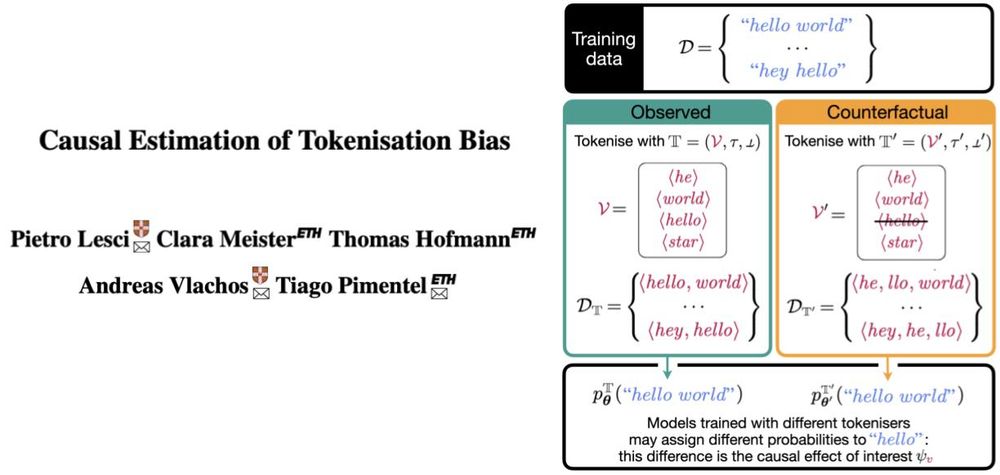

Pietro Lesci
@pietrolesci.bsky.social
· Jun 5
Pietro Lesci
@pietrolesci.bsky.social
· Jun 5

Pietro Lesci
@pietrolesci.bsky.social
· Jun 5
Pietro Lesci
@pietrolesci.bsky.social
· Jun 5
Pietro Lesci
@pietrolesci.bsky.social
· Jun 5
Pietro Lesci
@pietrolesci.bsky.social
· Jun 5
Reposted by Pietro Lesci
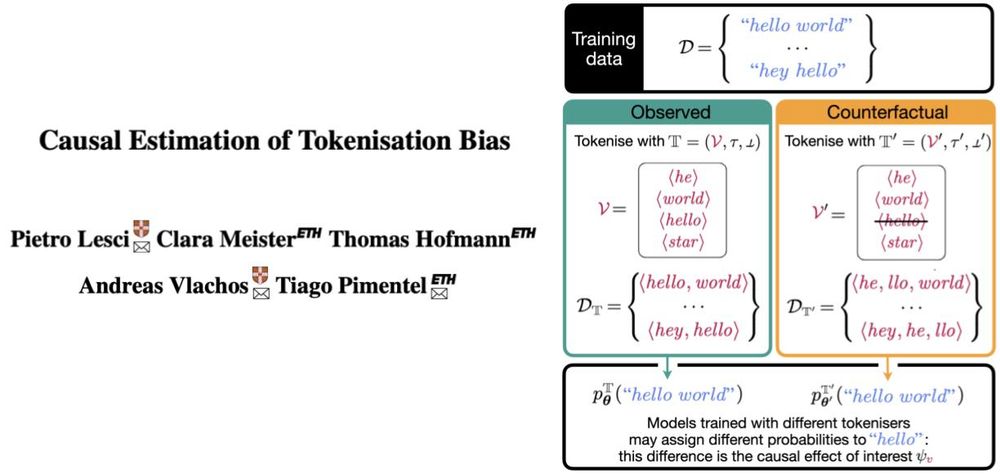
Reposted by Pietro Lesci



Pietro Lesci
@pietrolesci.bsky.social
· Apr 30


Pietro Lesci
@pietrolesci.bsky.social
· Apr 22
Pietro Lesci
@pietrolesci.bsky.social
· Apr 22
Pietro Lesci
@pietrolesci.bsky.social
· Apr 22
Pietro Lesci
@pietrolesci.bsky.social
· Apr 22
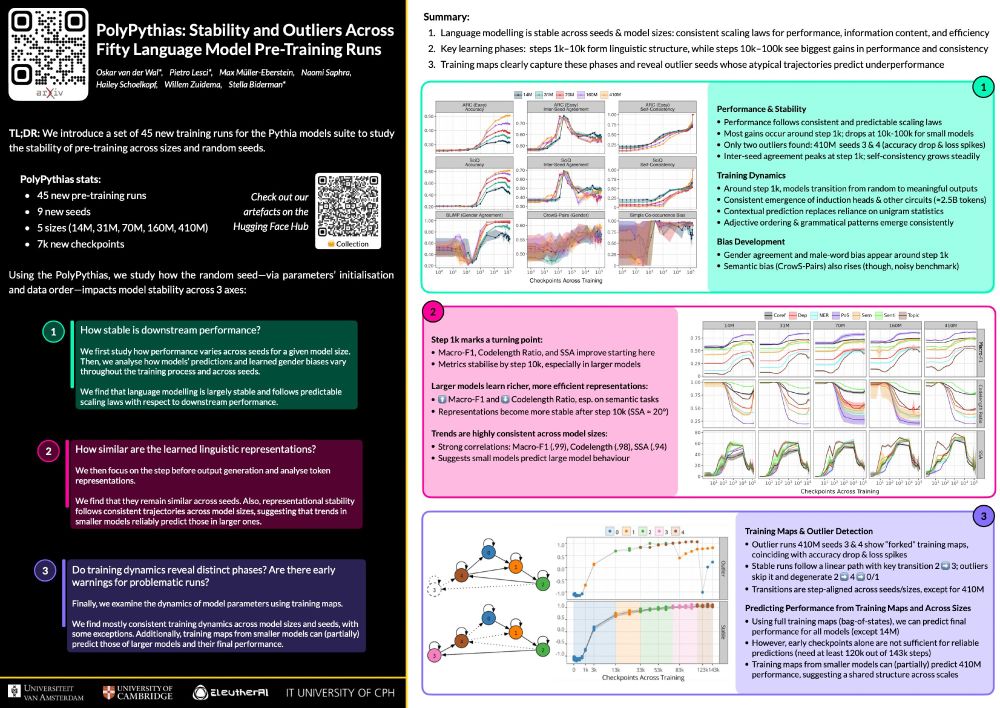
Reposted by Pietro Lesci

Alex Thiery
@alexxthiery.bsky.social
· Nov 26