Tiago Pimentel
@tpimentel.bsky.social
2.2K followers
120 following
32 posts
Postdoc at ETH. Formerly, PhD student at the University of Cambridge :)
Posts
Media
Videos
Starter Packs
Pinned

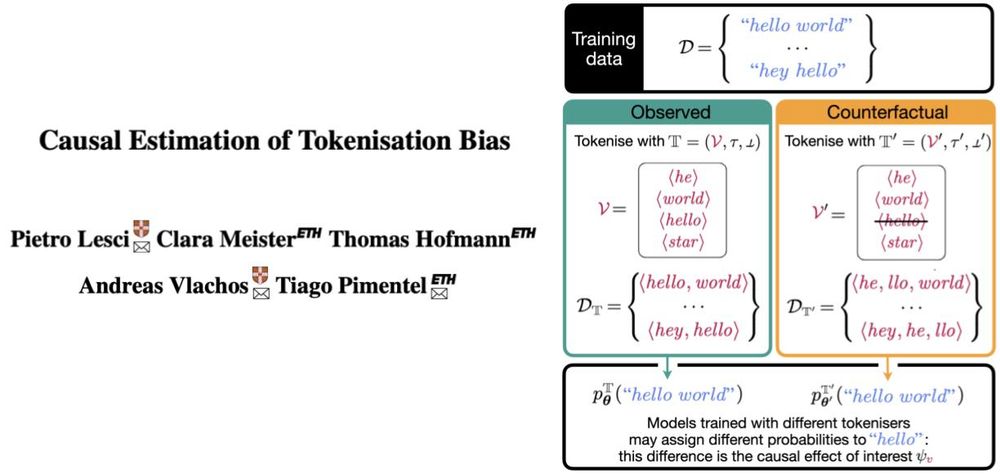
Reposted by Tiago Pimentel


Reposted by Tiago Pimentel

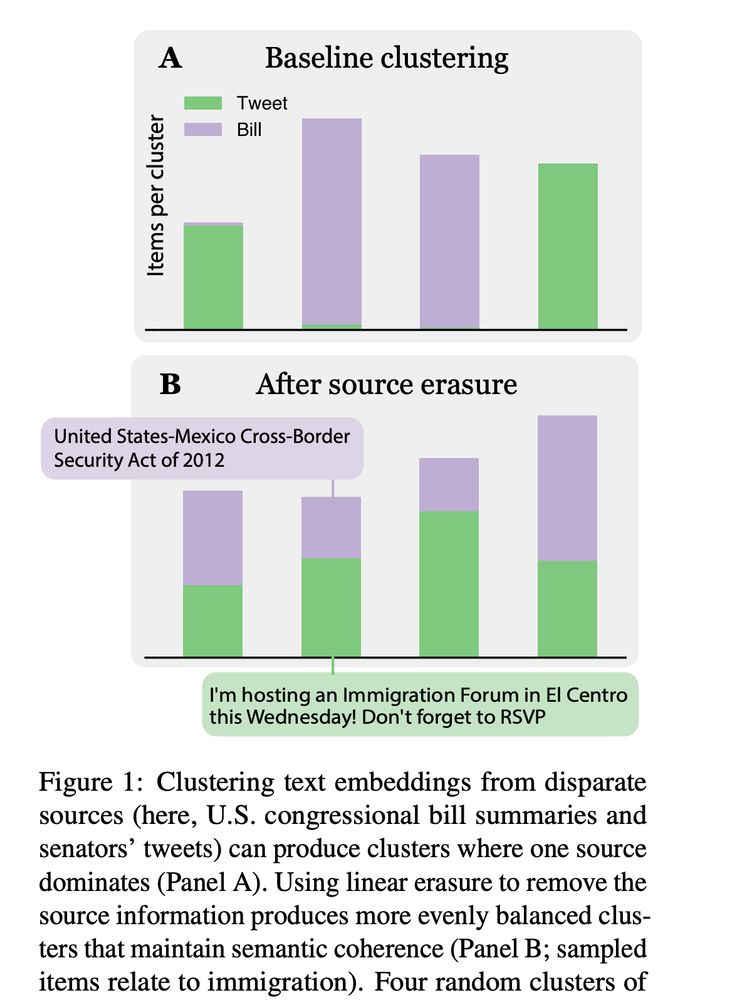





Tiago Pimentel
@tpimentel.bsky.social
· Jul 27

Reposted by Tiago Pimentel

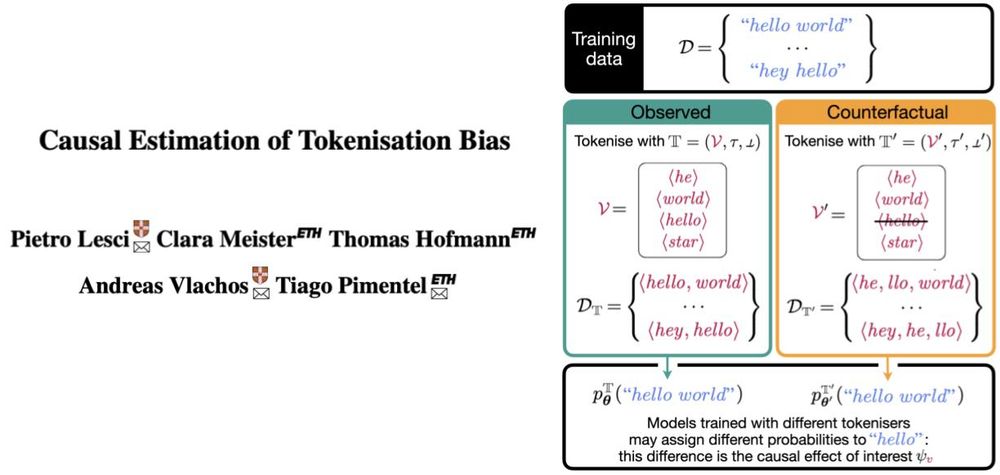
Reposted by Tiago Pimentel


Tiago Pimentel
@tpimentel.bsky.social
· Jul 14
Tiago Pimentel
@tpimentel.bsky.social
· Jul 14
Tiago Pimentel
@tpimentel.bsky.social
· Jul 14
Tiago Pimentel
@tpimentel.bsky.social
· Jul 14
Tiago Pimentel
@tpimentel.bsky.social
· Jul 14

The Non-Linear Representation Dilemma: Is Causal Abstraction Enough for Mechanistic Interpretability?
The concept of causal abstraction got recently popularised to demystify the opaque decision-making processes of machine learning models; in short, a neural network can be abstracted as a higher-level ...
arxiv.org
Reposted by Tiago Pimentel
Reposted by Tiago Pimentel

Tom McCoy
@rtommccoy.bsky.social
· Jun 4
Reposted by Tiago Pimentel
