Quentin Berthet
@qberthet.bsky.social
900 followers
130 following
31 posts
Machine learning
Google DeepMind
Paris
Posts
Media
Videos
Starter Packs
Pinned


Reposted by Quentin Berthet

Quentin Berthet
@qberthet.bsky.social
· Apr 17
Quentin Berthet
@qberthet.bsky.social
· Mar 25

Quentin Berthet
@qberthet.bsky.social
· Feb 22
Quentin Berthet
@qberthet.bsky.social
· Feb 21
Reposted by Quentin Berthet



Quentin Berthet
@qberthet.bsky.social
· Feb 10

Quentin Berthet
@qberthet.bsky.social
· Feb 10

Quentin Berthet
@qberthet.bsky.social
· Feb 10
Quentin Berthet
@qberthet.bsky.social
· Feb 10

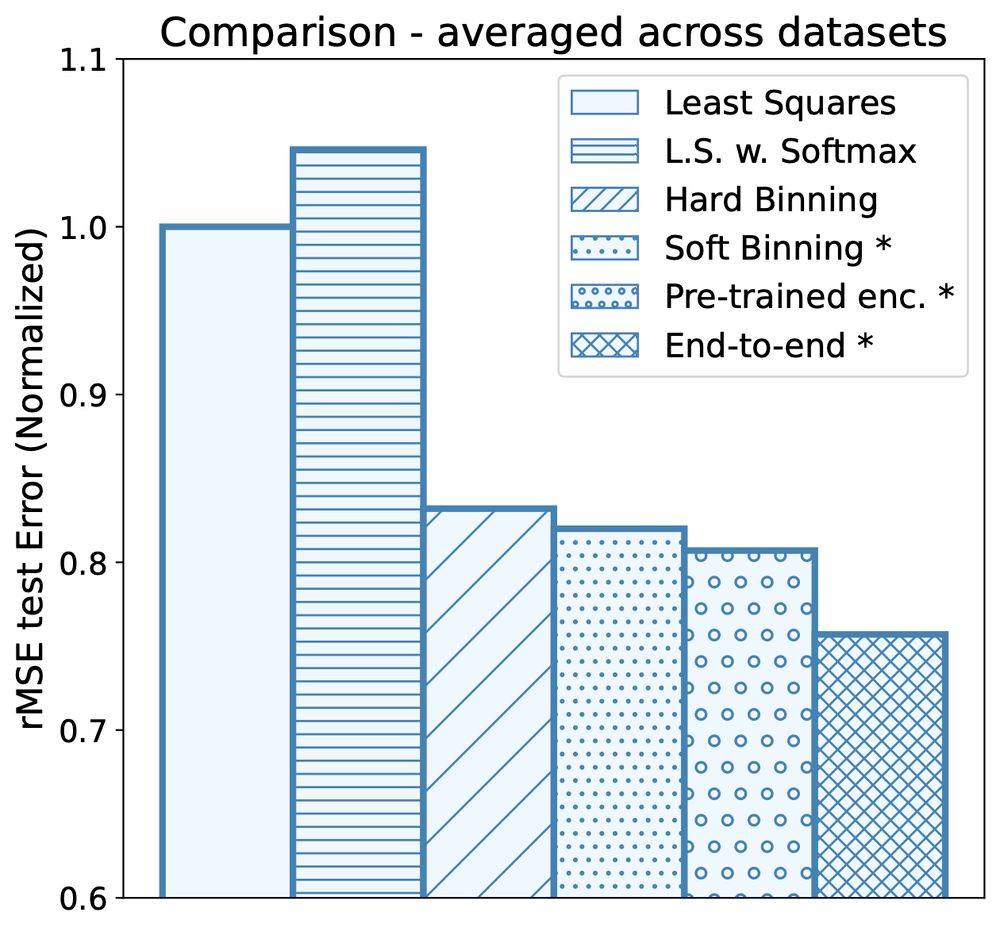
Building Bridges between Regression, Clustering, and Classification
Regression, the task of predicting a continuous scalar target y based on some features x is one of the most fundamental tasks in machine learning and statistics. It has been observed and...
arxiv.org
Reposted by Quentin Berthet


Reposted by Quentin Berthet


Quentin Berthet
@qberthet.bsky.social
· Feb 4