Posts
Media
Videos
Starter Packs

Reposted by Qing Yao



Reposted by Qing Yao

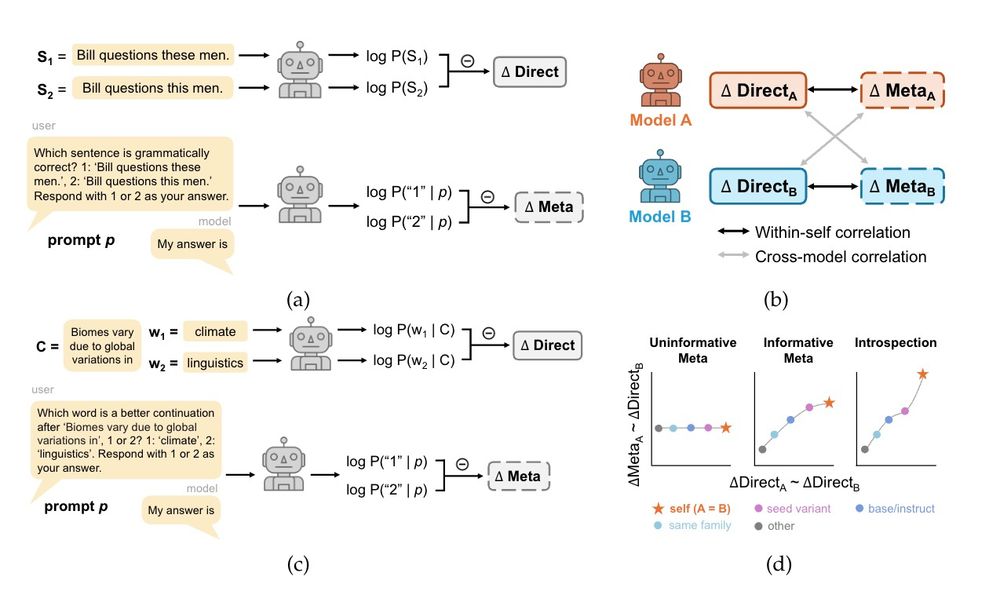

Reposted by Qing Yao


Reposted by Qing Yao



Qing Yao
@qyao.bsky.social
· Mar 31
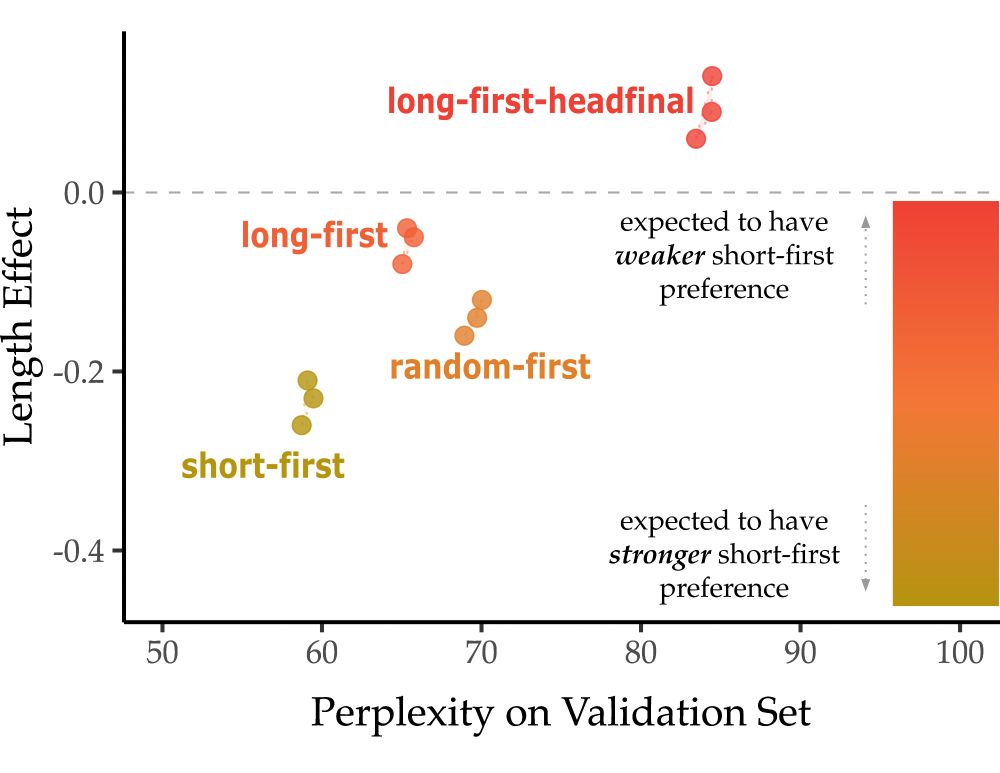
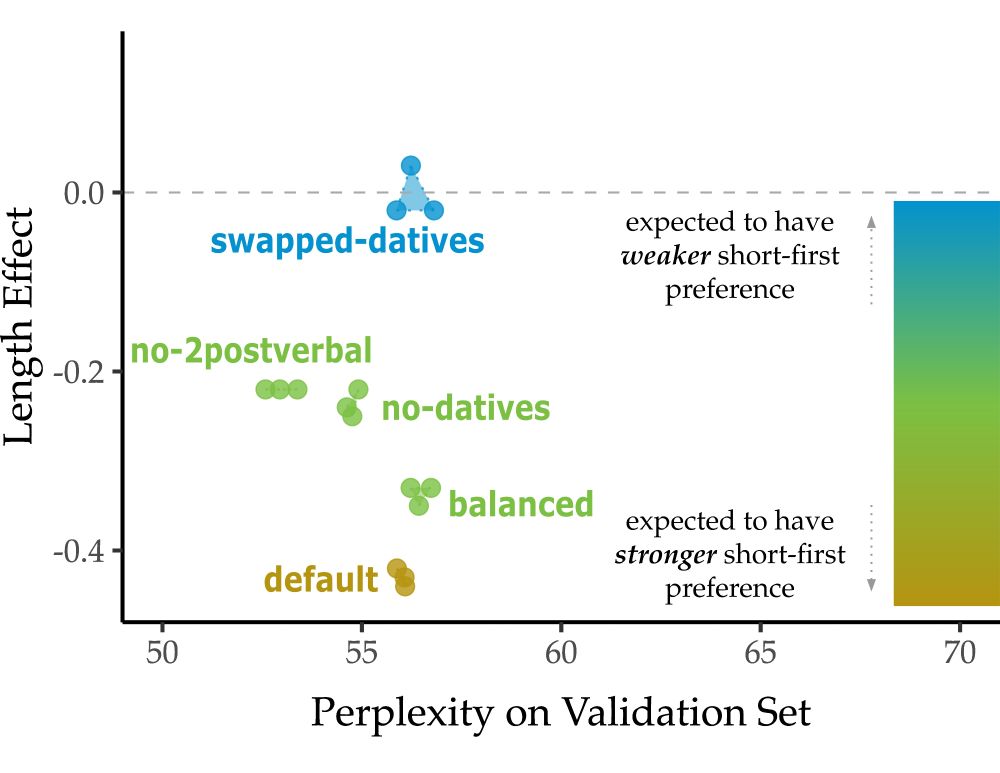
Qing Yao
@qyao.bsky.social
· Mar 31
Qing Yao
@qyao.bsky.social
· Mar 31
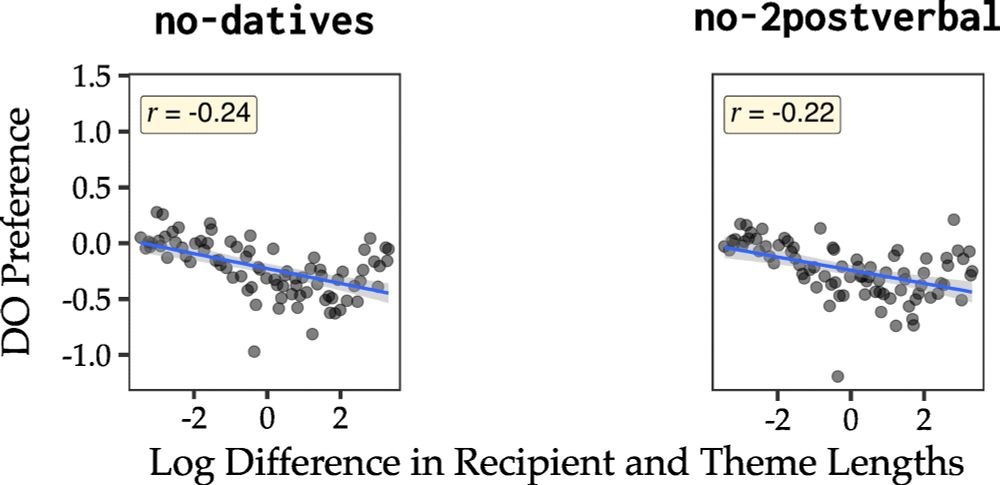
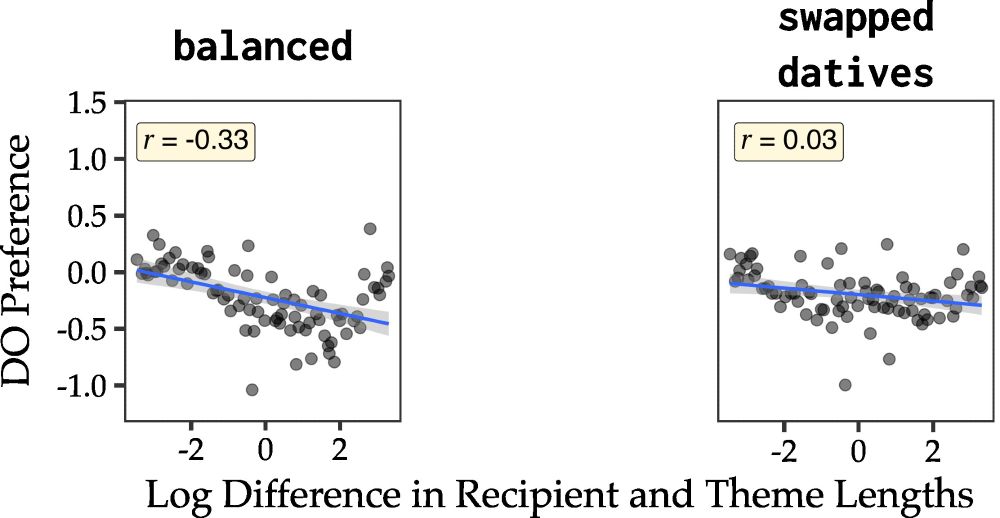
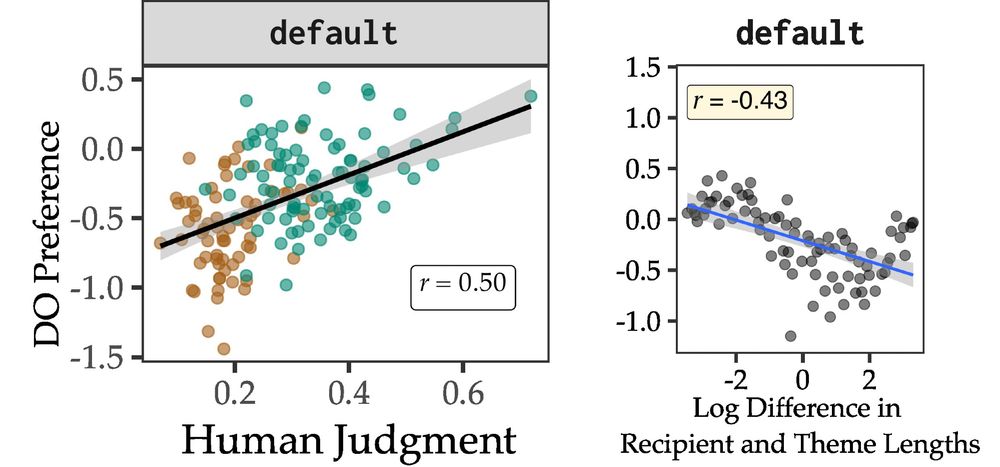
Qing Yao
@qyao.bsky.social
· Mar 31

Qing Yao
@qyao.bsky.social
· Mar 31
Qing Yao
@qyao.bsky.social
· Mar 31
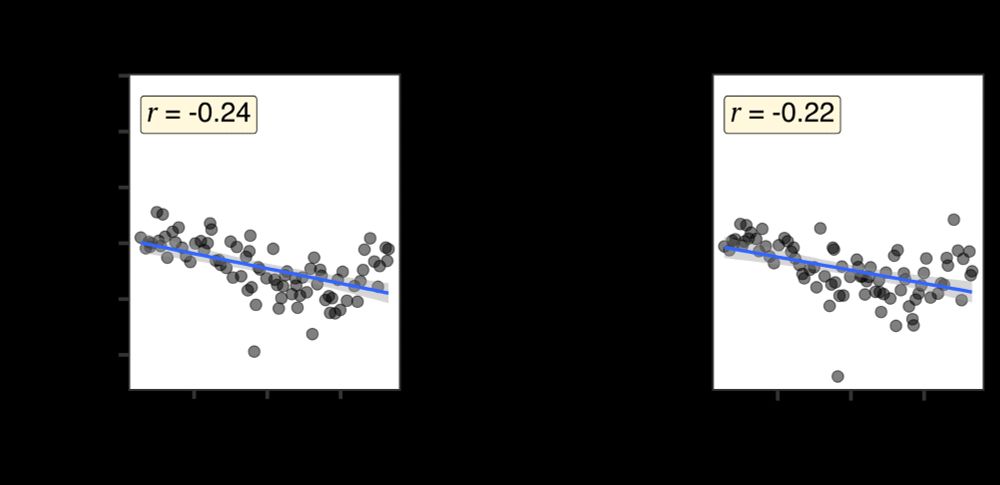
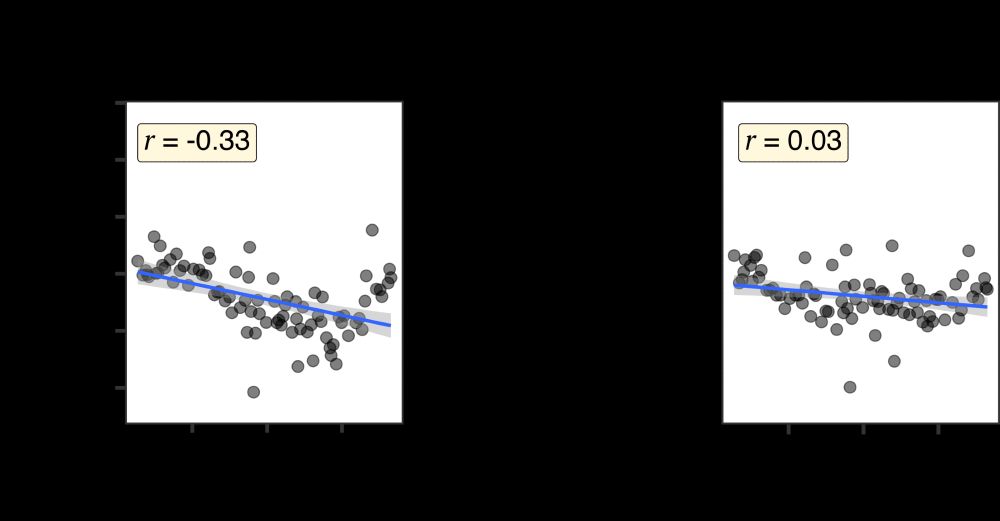
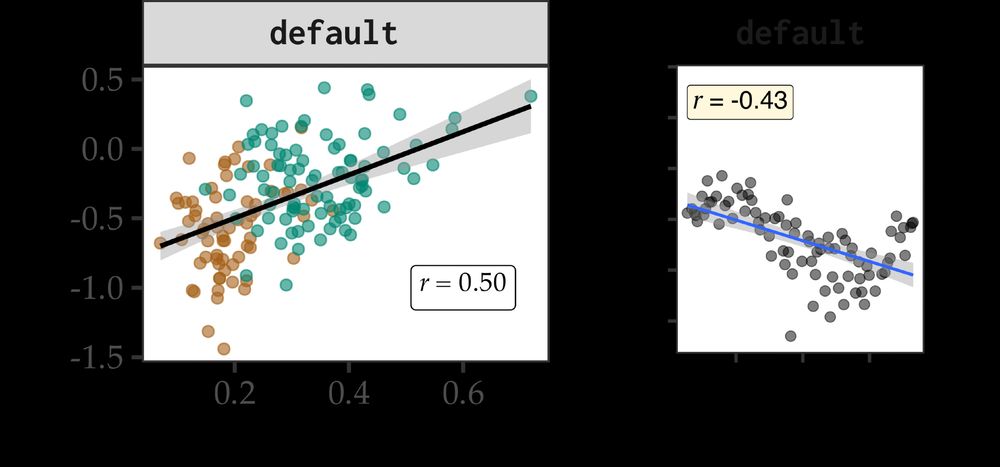
Qing Yao
@qyao.bsky.social
· Mar 31