
Siyuan Song✈️COLM
@siyuansong.bsky.social
150 followers
320 following
34 posts
senior undergrad@UTexas Linguistics | @growai.bsky.social
Looking for Ph.D position 26 Fall
Comp Psycholing & CogSci, human-like AI, rock🎸
Prev: MIT BCS, VURI@Harvard Psych, Undergrad@SJTU
Opinions are my own.
Posts
Media
Videos
Starter Packs
Pinned

Reposted by Siyuan Song✈️COLM



Reposted by Siyuan Song✈️COLM




Reposted by Siyuan Song✈️COLM



Reposted by Siyuan Song✈️COLM


Reposted by Siyuan Song✈️COLM

Reposted by Siyuan Song✈️COLM







Reposted by Siyuan Song✈️COLM

Reposted by Siyuan Song✈️COLM

Reposted by Siyuan Song✈️COLM


Reposted by Siyuan Song✈️COLM

Reposted by Siyuan Song✈️COLM


Reposted by Siyuan Song✈️COLM

Reposted by Siyuan Song✈️COLM

Siyuan Song✈️COLM
@siyuansong.bsky.social
· Aug 26

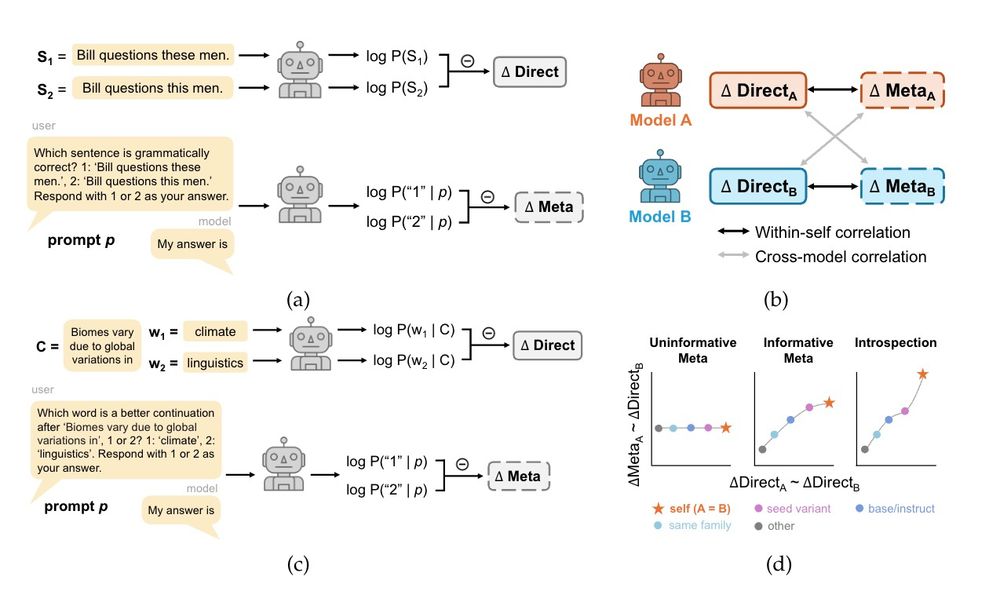
Privileged Self-Access Matters for Introspection in AI
Whether AI models can introspect is an increasingly important practical question. But there is no consensus on how introspection is to be defined. Beginning from a recently proposed ''lightweight'' de...
arxiv.org
Siyuan Song✈️COLM
@siyuansong.bsky.social
· Aug 26


Siyuan Song✈️COLM
@siyuansong.bsky.social
· Aug 26