Raphaël Millière
@raphaelmilliere.com
6.6K followers
950 following
130 posts
Philosopher of Artificial Intelligence & Cognitive Science
https://raphaelmilliere.com/
Posts
Media
Videos
Starter Packs
Pinned


Reposted by Raphaël Millière


Raphaël Millière
@raphaelmilliere.com
· Aug 21
Raphaël Millière
@raphaelmilliere.com
· Aug 14

Raphaël Millière
@raphaelmilliere.com
· Aug 11







Raphaël Millière
@raphaelmilliere.com
· Aug 11
Raphaël Millière
@raphaelmilliere.com
· Aug 11

Raphaël Millière
@raphaelmilliere.com
· Jul 18

Reposted by Raphaël Millière

Sam Gershman
@gershbrain.bsky.social
· Jul 9
Raphaël Millière
@raphaelmilliere.com
· Jun 10
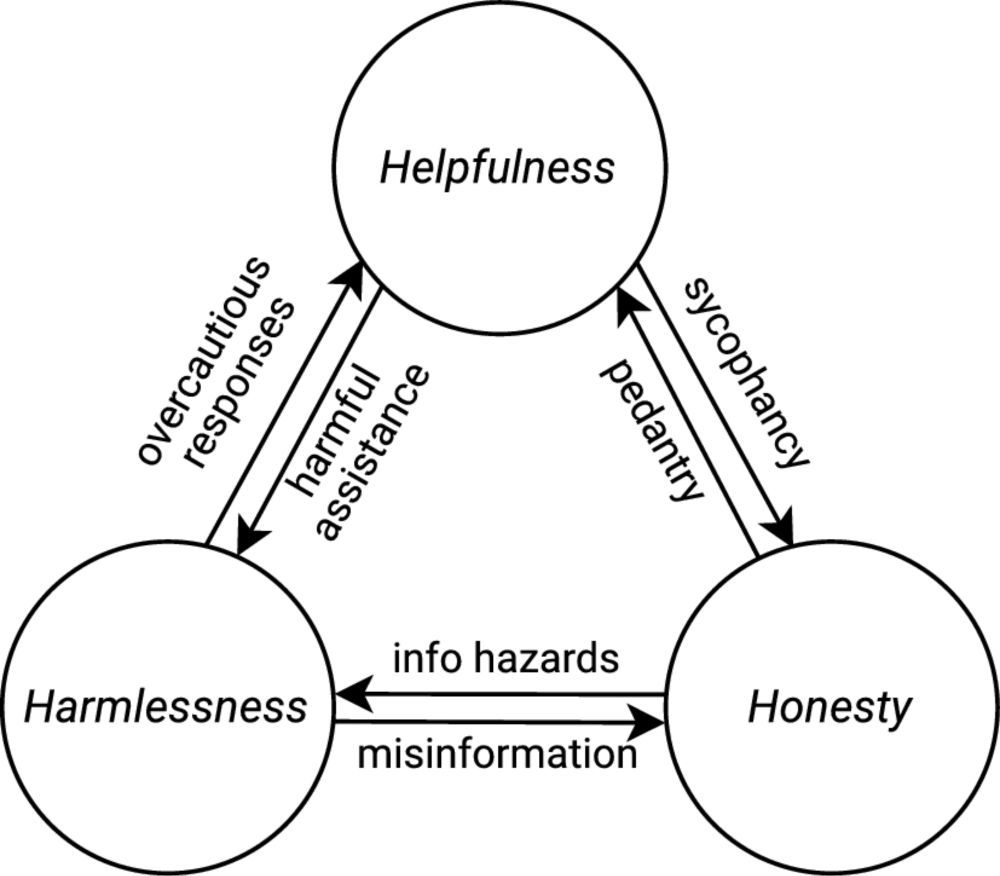
Normative conflicts and shallow AI alignment - Philosophical Studies
The progress of AI systems such as large language models (LLMs) raises increasingly pressing concerns about their safe deployment. This paper examines the value alignment problem for LLMs, arguing tha...
link.springer.com
Raphaël Millière
@raphaelmilliere.com
· Jun 10
Raphaël Millière
@raphaelmilliere.com
· Jun 10
Raphaël Millière
@raphaelmilliere.com
· Jun 10


Raphaël Millière
@raphaelmilliere.com
· Jun 10
Raphaël Millière
@raphaelmilliere.com
· Jun 10
Raphaël Millière
@raphaelmilliere.com
· Jun 10