




Forecasting Research Institute
@research-fri.bsky.social
Research institute focused on developing forecasting methods to improve decision-making on high-stakes issues, co-founded by chief scientist Philip Tetlock. https://forecastingresearch.org/
Insight #5: Expert groups mostly agree.
CS, economics, policy, and industry experts predict similar futures.
Superforecasters and experts align closely — though where there is disagreement, superforecasters often expect slower progress.
CS, economics, policy, and industry experts predict similar futures.
Superforecasters and experts align closely — though where there is disagreement, superforecasters often expect slower progress.


November 10, 2025 at 6:25 PM
Insight #5: Expert groups mostly agree.
CS, economics, policy, and industry experts predict similar futures.
Superforecasters and experts align closely — though where there is disagreement, superforecasters often expect slower progress.
CS, economics, policy, and industry experts predict similar futures.
Superforecasters and experts align closely — though where there is disagreement, superforecasters often expect slower progress.
Insight #4: Experts predict faster AI progress than the public.
2030 forecasts:
🚗 20% vs 12% rides autonomous
💻 18% vs 10% work hours AI-assisted
💊 25% vs 15% AI-developed drug sales
Experts see faster change overall.
2030 forecasts:
🚗 20% vs 12% rides autonomous
💻 18% vs 10% work hours AI-assisted
💊 25% vs 15% AI-developed drug sales
Experts see faster change overall.


November 10, 2025 at 6:25 PM
Insight #4: Experts predict faster AI progress than the public.
2030 forecasts:
🚗 20% vs 12% rides autonomous
💻 18% vs 10% work hours AI-assisted
💊 25% vs 15% AI-developed drug sales
Experts see faster change overall.
2030 forecasts:
🚗 20% vs 12% rides autonomous
💻 18% vs 10% work hours AI-assisted
💊 25% vs 15% AI-developed drug sales
Experts see faster change overall.
We’ve analyzed 600,000+ words of expert rationales.
These explain why experts disagree — on things like AI’s effect on science, and whether it’ll achieve major breakthroughs.
These explain why experts disagree — on things like AI’s effect on science, and whether it’ll achieve major breakthroughs.


November 10, 2025 at 6:25 PM
We’ve analyzed 600,000+ words of expert rationales.
These explain why experts disagree — on things like AI’s effect on science, and whether it’ll achieve major breakthroughs.
These explain why experts disagree — on things like AI’s effect on science, and whether it’ll achieve major breakthroughs.
Insight #2: Big disagreements among experts.
Top quartile: >50% of new 2040 drugs AI-discovered.
Bottom quartile: <10%.
Top quartile: >81% chance AI solves a Millennium Prize Problem by 2040.
Bottom quartile: <30%
Top quartile: >50% of new 2040 drugs AI-discovered.
Bottom quartile: <10%.
Top quartile: >81% chance AI solves a Millennium Prize Problem by 2040.
Bottom quartile: <30%

November 10, 2025 at 6:25 PM
Insight #2: Big disagreements among experts.
Top quartile: >50% of new 2040 drugs AI-discovered.
Bottom quartile: <10%.
Top quartile: >81% chance AI solves a Millennium Prize Problem by 2040.
Bottom quartile: <30%
Top quartile: >50% of new 2040 drugs AI-discovered.
Bottom quartile: <10%.
Top quartile: >81% chance AI solves a Millennium Prize Problem by 2040.
Bottom quartile: <30%
Experts rate AI’s 2040 impact on Nate Silver's “Technological Richter Scale.”
They expect AI ≈ “tech of the century” (like electricity).
32% think it’ll be “tech of the millennium” (like the printing press).
They expect AI ≈ “tech of the century” (like electricity).
32% think it’ll be “tech of the millennium” (like the printing press).

November 10, 2025 at 6:25 PM
Experts rate AI’s 2040 impact on Nate Silver's “Technological Richter Scale.”
They expect AI ≈ “tech of the century” (like electricity).
32% think it’ll be “tech of the millennium” (like the printing press).
They expect AI ≈ “tech of the century” (like electricity).
32% think it’ll be “tech of the millennium” (like the printing press).
Insight #1: Experts expect sizeable near-term effects.
By 2030:
⌚ 18% of work hours AI-assisted
⚡ 7% of US electricity to AI
🧮 75% accuracy on FrontierMath
🚗 20% of ride-hailing = autonomous
By 2040:
👥 30% use AI companionship daily
💊 25% of new drugs AI-discovered
By 2030:
⌚ 18% of work hours AI-assisted
⚡ 7% of US electricity to AI
🧮 75% accuracy on FrontierMath
🚗 20% of ride-hailing = autonomous
By 2040:
👥 30% use AI companionship daily
💊 25% of new drugs AI-discovered

November 10, 2025 at 6:25 PM
Insight #1: Experts expect sizeable near-term effects.
By 2030:
⌚ 18% of work hours AI-assisted
⚡ 7% of US electricity to AI
🧮 75% accuracy on FrontierMath
🚗 20% of ride-hailing = autonomous
By 2040:
👥 30% use AI companionship daily
💊 25% of new drugs AI-discovered
By 2030:
⌚ 18% of work hours AI-assisted
⚡ 7% of US electricity to AI
🧮 75% accuracy on FrontierMath
🚗 20% of ride-hailing = autonomous
By 2040:
👥 30% use AI companionship daily
💊 25% of new drugs AI-discovered
Today we’re launching the most rigorous, ongoing source of expert forecasts on the future of AI: the Longitudinal Expert AI Panel (LEAP).
339 top experts across AI, CS, economics, and policy will forecast AI’s trajectory monthly for 3 years.
🧵👇
339 top experts across AI, CS, economics, and policy will forecast AI’s trajectory monthly for 3 years.
🧵👇


November 10, 2025 at 6:25 PM
Today we’re launching the most rigorous, ongoing source of expert forecasts on the future of AI: the Longitudinal Expert AI Panel (LEAP).
339 top experts across AI, CS, economics, and policy will forecast AI’s trajectory monthly for 3 years.
🧵👇
339 top experts across AI, CS, economics, and policy will forecast AI’s trajectory monthly for 3 years.
🧵👇
⬆️LLMs’ forecasting abilities are improving.
GPT-4 achieved a difficulty-adjusted Brier score of 0.131.
~2 years later, GPT-4.5 scored 0.101—a substantial improvement.
A linear extrapolation of SOTA LLM forecasting performance suggests LLMs will match superforecasters in November 2026.
GPT-4 achieved a difficulty-adjusted Brier score of 0.131.
~2 years later, GPT-4.5 scored 0.101—a substantial improvement.
A linear extrapolation of SOTA LLM forecasting performance suggests LLMs will match superforecasters in November 2026.

October 9, 2025 at 12:26 PM
⬆️LLMs’ forecasting abilities are improving.
GPT-4 achieved a difficulty-adjusted Brier score of 0.131.
~2 years later, GPT-4.5 scored 0.101—a substantial improvement.
A linear extrapolation of SOTA LLM forecasting performance suggests LLMs will match superforecasters in November 2026.
GPT-4 achieved a difficulty-adjusted Brier score of 0.131.
~2 years later, GPT-4.5 scored 0.101—a substantial improvement.
A linear extrapolation of SOTA LLM forecasting performance suggests LLMs will match superforecasters in November 2026.
📈 LLMs have surpassed the general public.
A year ago, when we first released ForecastBench, the median public forecast sat at #2 in our leaderboard—trailing behind only superforecasters.
Today, the median public forecast is beaten by multiple LLMs, putting it at #22 in our new leaderboard.
A year ago, when we first released ForecastBench, the median public forecast sat at #2 in our leaderboard—trailing behind only superforecasters.
Today, the median public forecast is beaten by multiple LLMs, putting it at #22 in our new leaderboard.

October 9, 2025 at 12:26 PM
📈 LLMs have surpassed the general public.
A year ago, when we first released ForecastBench, the median public forecast sat at #2 in our leaderboard—trailing behind only superforecasters.
Today, the median public forecast is beaten by multiple LLMs, putting it at #22 in our new leaderboard.
A year ago, when we first released ForecastBench, the median public forecast sat at #2 in our leaderboard—trailing behind only superforecasters.
Today, the median public forecast is beaten by multiple LLMs, putting it at #22 in our new leaderboard.
Superforecasters still outperform leading LLMs.
👇Superforecasters top the ForecastBench leaderboard, with a difficulty-adjusted Brier score of 0.081 (lower Brier scores indicate higher accuracy).
🤖The best-performing LLM in our dataset is @OpenAI’s GPT-4.5 with a score of 0.101—a gap of 0.02.
👇Superforecasters top the ForecastBench leaderboard, with a difficulty-adjusted Brier score of 0.081 (lower Brier scores indicate higher accuracy).
🤖The best-performing LLM in our dataset is @OpenAI’s GPT-4.5 with a score of 0.101—a gap of 0.02.

October 9, 2025 at 12:26 PM
Superforecasters still outperform leading LLMs.
👇Superforecasters top the ForecastBench leaderboard, with a difficulty-adjusted Brier score of 0.081 (lower Brier scores indicate higher accuracy).
🤖The best-performing LLM in our dataset is @OpenAI’s GPT-4.5 with a score of 0.101—a gap of 0.02.
👇Superforecasters top the ForecastBench leaderboard, with a difficulty-adjusted Brier score of 0.081 (lower Brier scores indicate higher accuracy).
🤖The best-performing LLM in our dataset is @OpenAI’s GPT-4.5 with a score of 0.101—a gap of 0.02.
Is AI on track to match top human forecasters at predicting the future?
Today, FRI is releasing an update to ForecastBench—our benchmark that tracks how accurate large language models (LLMs) are at forecasting real-world events.
Here’s what you need to know: 🧵
Today, FRI is releasing an update to ForecastBench—our benchmark that tracks how accurate large language models (LLMs) are at forecasting real-world events.
Here’s what you need to know: 🧵

October 9, 2025 at 12:26 PM
Is AI on track to match top human forecasters at predicting the future?
Today, FRI is releasing an update to ForecastBench—our benchmark that tracks how accurate large language models (LLMs) are at forecasting real-world events.
Here’s what you need to know: 🧵
Today, FRI is releasing an update to ForecastBench—our benchmark that tracks how accurate large language models (LLMs) are at forecasting real-world events.
Here’s what you need to know: 🧵
And these are the top-10 most surprising questions for experts forecasting within their area of expertise.

September 2, 2025 at 12:06 PM
And these are the top-10 most surprising questions for experts forecasting within their area of expertise.
We identified questions that were most ‘surprising’ to our forecasters—where the aggregate forecast diverged most from reality.
These are the 10 most surprising questions for superforecasters, calculated using the standardized absolute forecast errors (SAFE) metric. Full details in the paper.
These are the 10 most surprising questions for superforecasters, calculated using the standardized absolute forecast errors (SAFE) metric. Full details in the paper.

September 2, 2025 at 12:06 PM
We identified questions that were most ‘surprising’ to our forecasters—where the aggregate forecast diverged most from reality.
These are the 10 most surprising questions for superforecasters, calculated using the standardized absolute forecast errors (SAFE) metric. Full details in the paper.
These are the 10 most surprising questions for superforecasters, calculated using the standardized absolute forecast errors (SAFE) metric. Full details in the paper.
We didn’t find a correlation between short-run accuracy and existential risk beliefs.
Ideally, we’d use short-term forecasting accuracy to assess the reliability of judgments about humanity’s long-term future.
In our data, no such relationship emerged.
Ideally, we’d use short-term forecasting accuracy to assess the reliability of judgments about humanity’s long-term future.
In our data, no such relationship emerged.

September 2, 2025 at 12:06 PM
We didn’t find a correlation between short-run accuracy and existential risk beliefs.
Ideally, we’d use short-term forecasting accuracy to assess the reliability of judgments about humanity’s long-term future.
In our data, no such relationship emerged.
Ideally, we’d use short-term forecasting accuracy to assess the reliability of judgments about humanity’s long-term future.
In our data, no such relationship emerged.
Superforecasters and domain experts were equally accurate on short-run questions.
The performance gap between the most and least accurate XPT participant groups spanned just 0.18 standard deviations, and was not statistically significant.
The performance gap between the most and least accurate XPT participant groups spanned just 0.18 standard deviations, and was not statistically significant.

September 2, 2025 at 12:06 PM
Superforecasters and domain experts were equally accurate on short-run questions.
The performance gap between the most and least accurate XPT participant groups spanned just 0.18 standard deviations, and was not statistically significant.
The performance gap between the most and least accurate XPT participant groups spanned just 0.18 standard deviations, and was not statistically significant.
Climate tech progress was overestimated.
Superforecasters predicted green H₂ would cost $4.50/kg in 2024. Experts said $3.50/kg.
In reality, it was $7.50/kg.
For direct air capture, superforecasters predicted 0.32 MtCO₂/year and experts said 0.60 MtCO₂/year in 2024.
In reality: 0.01 MtCO₂/year.
Superforecasters predicted green H₂ would cost $4.50/kg in 2024. Experts said $3.50/kg.
In reality, it was $7.50/kg.
For direct air capture, superforecasters predicted 0.32 MtCO₂/year and experts said 0.60 MtCO₂/year in 2024.
In reality: 0.01 MtCO₂/year.

September 2, 2025 at 12:06 PM
Climate tech progress was overestimated.
Superforecasters predicted green H₂ would cost $4.50/kg in 2024. Experts said $3.50/kg.
In reality, it was $7.50/kg.
For direct air capture, superforecasters predicted 0.32 MtCO₂/year and experts said 0.60 MtCO₂/year in 2024.
In reality: 0.01 MtCO₂/year.
Superforecasters predicted green H₂ would cost $4.50/kg in 2024. Experts said $3.50/kg.
In reality, it was $7.50/kg.
For direct air capture, superforecasters predicted 0.32 MtCO₂/year and experts said 0.60 MtCO₂/year in 2024.
In reality: 0.01 MtCO₂/year.
The International Mathematical Olympiad results were even more surprising.
AI systems achieved gold-level performance at the IMO in July 2025.
Superforecasters assigned this outcome just a 2.3% probability. Domain experts put it at 8.6%.
AI systems achieved gold-level performance at the IMO in July 2025.
Superforecasters assigned this outcome just a 2.3% probability. Domain experts put it at 8.6%.

September 2, 2025 at 12:06 PM
The International Mathematical Olympiad results were even more surprising.
AI systems achieved gold-level performance at the IMO in July 2025.
Superforecasters assigned this outcome just a 2.3% probability. Domain experts put it at 8.6%.
AI systems achieved gold-level performance at the IMO in July 2025.
Superforecasters assigned this outcome just a 2.3% probability. Domain experts put it at 8.6%.
Respondents underestimated AI progress.
Participants predicted the state-of-the-art accuracy of AI on MATH, MMLU, and QuaLITY benchmarks by mid-2025.
Experts gave probabilities of 21.4%, 25% and 43.5% to the achieved outcomes.
Superforecasters gave even lower probabilities: 9.3%, 7.2% and 20.1%.
Participants predicted the state-of-the-art accuracy of AI on MATH, MMLU, and QuaLITY benchmarks by mid-2025.
Experts gave probabilities of 21.4%, 25% and 43.5% to the achieved outcomes.
Superforecasters gave even lower probabilities: 9.3%, 7.2% and 20.1%.

September 2, 2025 at 12:06 PM
Respondents underestimated AI progress.
Participants predicted the state-of-the-art accuracy of AI on MATH, MMLU, and QuaLITY benchmarks by mid-2025.
Experts gave probabilities of 21.4%, 25% and 43.5% to the achieved outcomes.
Superforecasters gave even lower probabilities: 9.3%, 7.2% and 20.1%.
Participants predicted the state-of-the-art accuracy of AI on MATH, MMLU, and QuaLITY benchmarks by mid-2025.
Experts gave probabilities of 21.4%, 25% and 43.5% to the achieved outcomes.
Superforecasters gave even lower probabilities: 9.3%, 7.2% and 20.1%.
In 2022, we convened 169 experts and superforecasters for the Existential Risk Persuasion Tournament (XPT). We collected thousands of forecasts in 172 questions across time horizons.
We now have answers for 38 questions covering AI, climate tech, bioweapons and more.
Here’s what we found out: 🧵
We now have answers for 38 questions covering AI, climate tech, bioweapons and more.
Here’s what we found out: 🧵

September 2, 2025 at 12:06 PM
In 2022, we convened 169 experts and superforecasters for the Existential Risk Persuasion Tournament (XPT). We collected thousands of forecasts in 172 questions across time horizons.
We now have answers for 38 questions covering AI, climate tech, bioweapons and more.
Here’s what we found out: 🧵
We now have answers for 38 questions covering AI, climate tech, bioweapons and more.
Here’s what we found out: 🧵
Great to see our report on LLM-enabled biorisk covered in the latest issue of The Economist: www.economist.com/briefing/202...

July 25, 2025 at 4:11 PM
Great to see our report on LLM-enabled biorisk covered in the latest issue of The Economist: www.economist.com/briefing/202...
But forecasters see promising avenues for mitigation; experts believe strong safeguards could bring risk back near baseline levels.
Combining proprietary models + anti-jailbreaking measures + mandatory DNA synthesis screening dropped risk from 1.25% back to 0.4%.
Combining proprietary models + anti-jailbreaking measures + mandatory DNA synthesis screening dropped risk from 1.25% back to 0.4%.

July 1, 2025 at 12:00 PM
But forecasters see promising avenues for mitigation; experts believe strong safeguards could bring risk back near baseline levels.
Combining proprietary models + anti-jailbreaking measures + mandatory DNA synthesis screening dropped risk from 1.25% back to 0.4%.
Combining proprietary models + anti-jailbreaking measures + mandatory DNA synthesis screening dropped risk from 1.25% back to 0.4%.
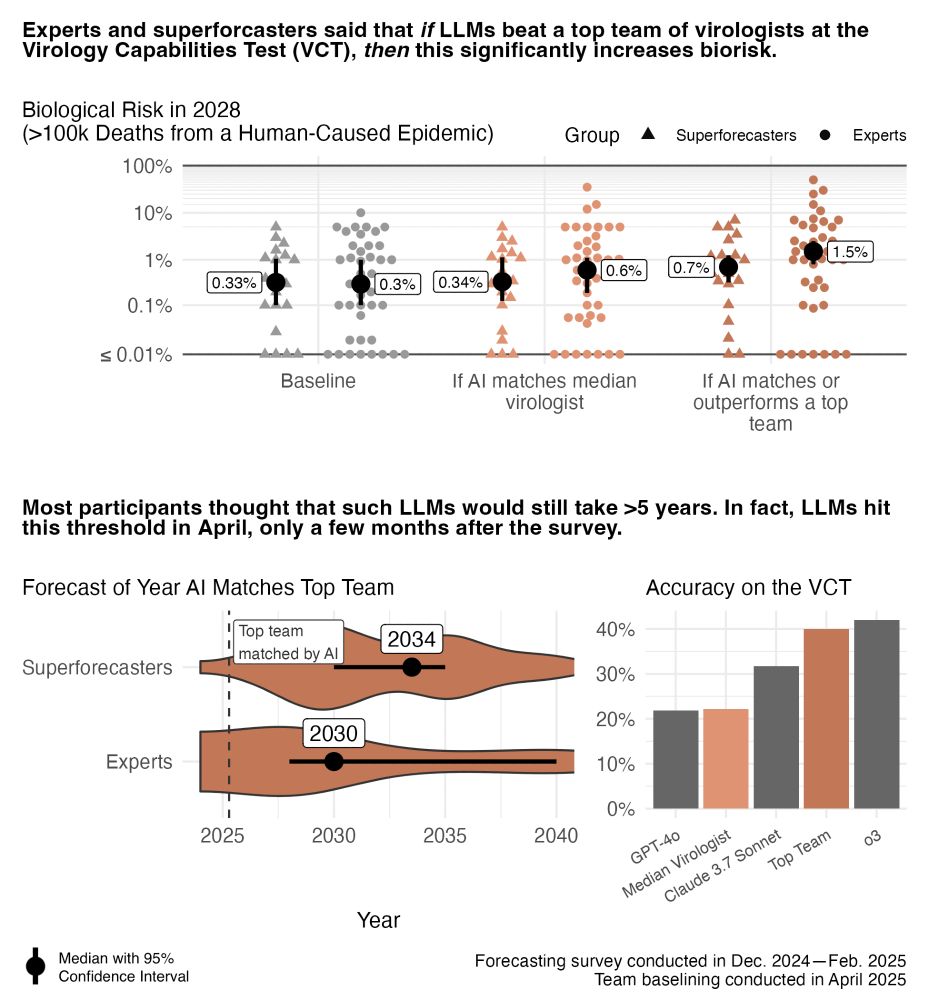
Experts predicted AI models would match a top virologist team on troubleshooting tests in 2030. Superforecasters thought it would take until 2034.
Both groups thought this capability would increase risk of a human-caused epidemic, with experts predicting a higher probability than superforecasters.
Both groups thought this capability would increase risk of a human-caused epidemic, with experts predicting a higher probability than superforecasters.
July 1, 2025 at 12:00 PM
Experts predicted AI models would match a top virologist team on troubleshooting tests in 2030. Superforecasters thought it would take until 2034.
Both groups thought this capability would increase risk of a human-caused epidemic, with experts predicting a higher probability than superforecasters.
Both groups thought this capability would increase risk of a human-caused epidemic, with experts predicting a higher probability than superforecasters.
Most experts predicted most dangerous AI capabilities wouldn't emerge until 2030-2040.
However, results from a collaboration with @securebio.org suggest that OpenAI's o3 model already matches top virologist teams on troubleshooting tests.
However, results from a collaboration with @securebio.org suggest that OpenAI's o3 model already matches top virologist teams on troubleshooting tests.

July 1, 2025 at 12:00 PM
Most experts predicted most dangerous AI capabilities wouldn't emerge until 2030-2040.
However, results from a collaboration with @securebio.org suggest that OpenAI's o3 model already matches top virologist teams on troubleshooting tests.
However, results from a collaboration with @securebio.org suggest that OpenAI's o3 model already matches top virologist teams on troubleshooting tests.
We surveyed 46 biosecurity/biology experts + 22 top forecasters on AI biorisk.
Key finding: the median expert thinks the baseline risk of a human-caused epidemic (>100k deaths) is 0.3% annually. But this figure rose to 1.5% conditional on certain LLM capabilities.
Key finding: the median expert thinks the baseline risk of a human-caused epidemic (>100k deaths) is 0.3% annually. But this figure rose to 1.5% conditional on certain LLM capabilities.

July 1, 2025 at 12:00 PM
We surveyed 46 biosecurity/biology experts + 22 top forecasters on AI biorisk.
Key finding: the median expert thinks the baseline risk of a human-caused epidemic (>100k deaths) is 0.3% annually. But this figure rose to 1.5% conditional on certain LLM capabilities.
Key finding: the median expert thinks the baseline risk of a human-caused epidemic (>100k deaths) is 0.3% annually. But this figure rose to 1.5% conditional on certain LLM capabilities.