Robin Hesse
@robinhesse.bsky.social
55 followers
120 following
3 posts
PhD student in explainable AI for computer vision @visinf.bsky.social @tuda.bsky.social - Prev. intern AWS and @maxplanck.de
Posts
Media
Videos
Starter Packs
Reposted by Robin Hesse

Reposted by Robin Hesse





Reposted by Robin Hesse


Reposted by Robin Hesse

Reposted by Robin Hesse

Reposted by Robin Hesse


Reposted by Robin Hesse




Reposted by Robin Hesse


Reposted by Robin Hesse
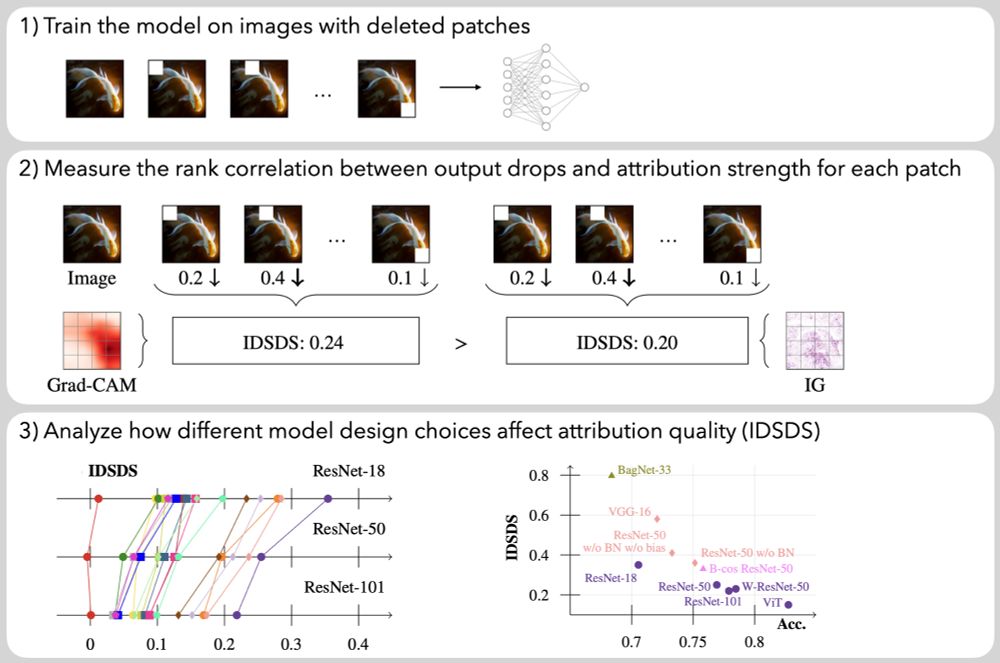
Visual Inference Lab
@visinf.bsky.social
· Jun 11

Reposted by Robin Hesse


Reposted by Robin Hesse

Reposted by Robin Hesse