
Christoph Reich
@christophreich.bsky.social
110 followers
250 following
13 posts
@ellis.eu Ph.D. Student @CVG (@dcremers.bsky.social), @visinf.bsky.social & @oxford-vgg.bsky.social | Ph.D. Scholar @zuseschooleliza.bsky.social | M.Sc. & B.Sc. @tuda.bsky.social | Prev. @neclabsamerica.bsky.social
https://christophreich1996.github.io
Posts
Media
Videos
Starter Packs

Reposted by Christoph Reich







Reposted by Christoph Reich



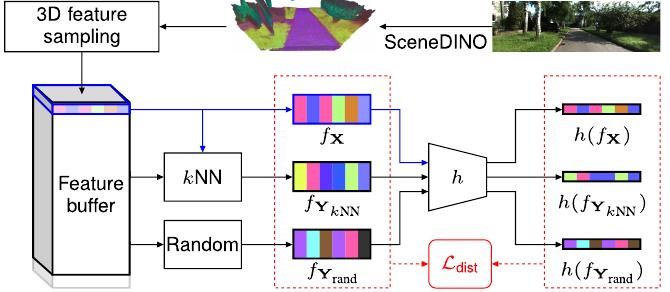

Reposted by Christoph Reich

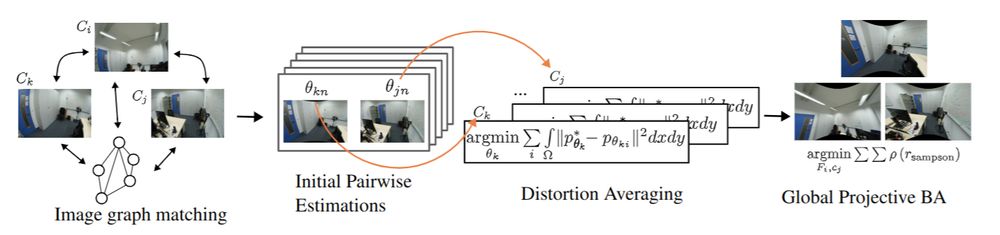






Reposted by Christoph Reich

arxiv cs.CV
@arxiv-cs-cv.bsky.social
· Jul 9
Reposted by Christoph Reich


Reposted by Christoph Reich




Reposted by Christoph Reich

Reposted by Christoph Reich

Reposted by Christoph Reich

Reposted by Christoph Reich



Reposted by Christoph Reich
