Robin Ryder
@robinryder.bsky.social
850 followers
120 following
83 posts
Mathematician at Imperial College London. Bayesian statistics, Data science, Languages, Phylogenies.
Posts
Media
Videos
Starter Packs
Reposted by Robin Ryder



Reposted by Robin Ryder

Reposted by Robin Ryder




Robin Ryder
@robinryder.bsky.social
· Aug 28



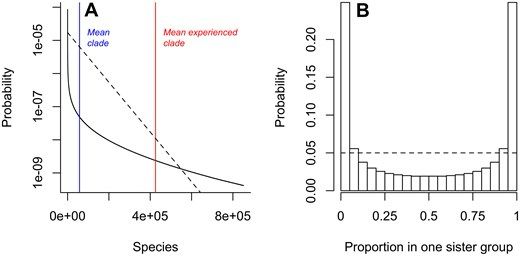



Reposted by Robin Ryder


Reposted by Robin Ryder

Reposted by Robin Ryder
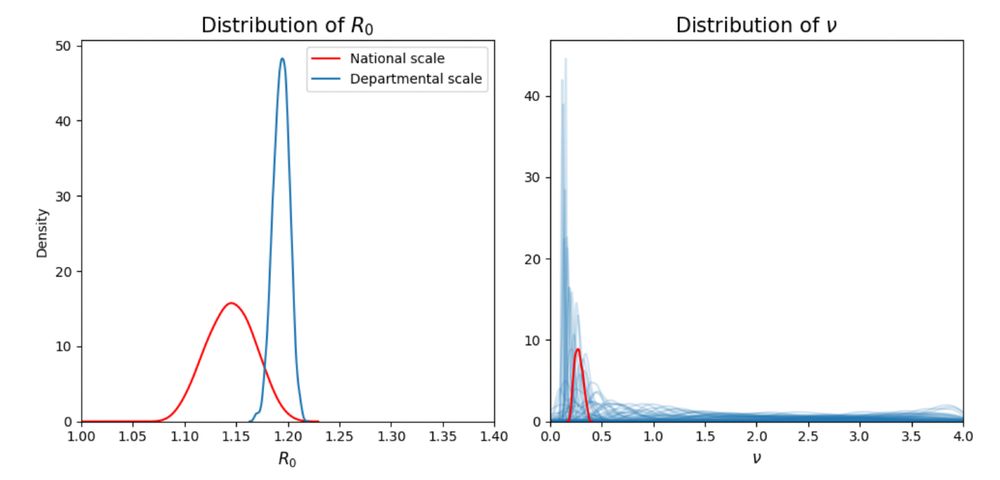
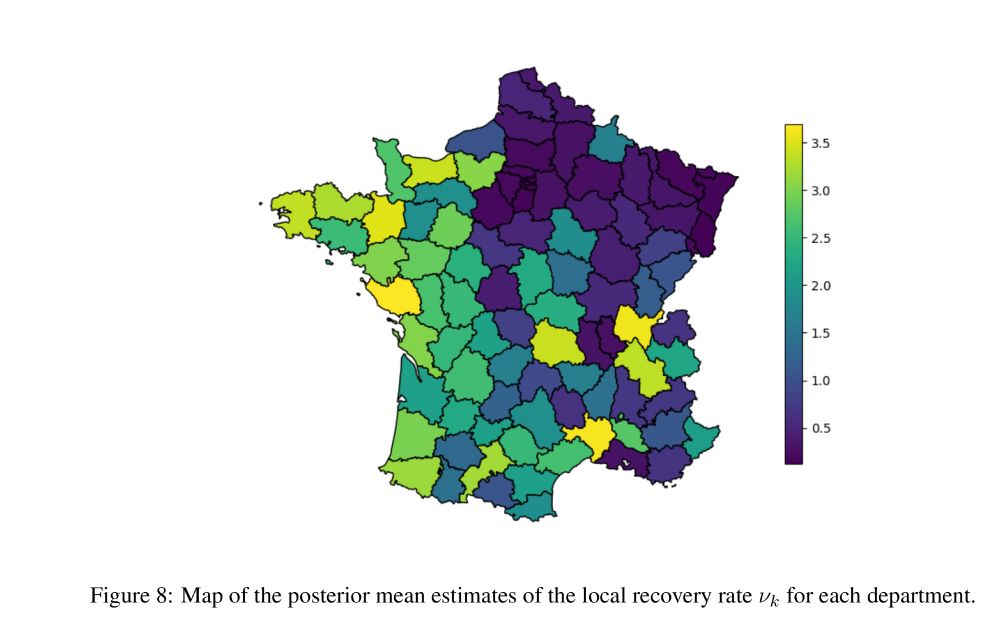
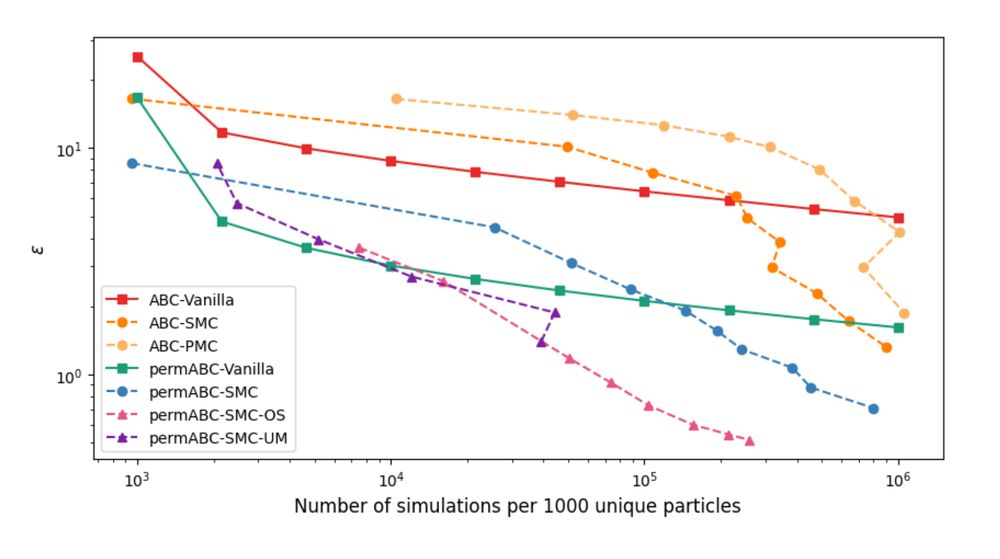
Robin Ryder
@robinryder.bsky.social
· Jul 9
Robin Ryder
@robinryder.bsky.social
· Jul 9
Robin Ryder
@robinryder.bsky.social
· Jul 9