




sageev
@sageev.bsky.social
"a symptom of an approaching nervous breakdown is the belief that one's work is terribly important"--bertrand russell
ML, music, generative models, robustness, ML & health
curr & prev affils:
Dalhousie University (CS), Vector Institute, Google Research
ML, music, generative models, robustness, ML & health
curr & prev affils:
Dalhousie University (CS), Vector Institute, Google Research
Sharpn🔪ss predicts ✅generalz'n xcept when it doesn't,eg ✖️formers
But what's🔪?Which point is🔪er?
Find out
*why it's a tricky Q(hint: #symmetry)
*why our answer does let🔪predict generalz'n, even in ✅formers!
@ our #ICML2025 #spotlight E-2001 on Wed 11AM
by MF da Silva and F Dangel
@vectorinstitute.ai
But what's🔪?Which point is🔪er?
Find out
*why it's a tricky Q(hint: #symmetry)
*why our answer does let🔪predict generalz'n, even in ✅formers!
@ our #ICML2025 #spotlight E-2001 on Wed 11AM
by MF da Silva and F Dangel
@vectorinstitute.ai

July 15, 2025 at 6:04 PM
Sharpn🔪ss predicts ✅generalz'n xcept when it doesn't,eg ✖️formers
But what's🔪?Which point is🔪er?
Find out
*why it's a tricky Q(hint: #symmetry)
*why our answer does let🔪predict generalz'n, even in ✅formers!
@ our #ICML2025 #spotlight E-2001 on Wed 11AM
by MF da Silva and F Dangel
@vectorinstitute.ai
But what's🔪?Which point is🔪er?
Find out
*why it's a tricky Q(hint: #symmetry)
*why our answer does let🔪predict generalz'n, even in ✅formers!
@ our #ICML2025 #spotlight E-2001 on Wed 11AM
by MF da Silva and F Dangel
@vectorinstitute.ai
I've been finding a way to get chatGPT to talk in a tone I haven't seen/read it take on before... interesting...
Just a few examples here. Note that the use of 'bold' was chatGPT's own choice, and I had not mentioned anything about safety nets in my interactions in this session.
Just a few examples here. Note that the use of 'bold' was chatGPT's own choice, and I had not mentioned anything about safety nets in my interactions in this session.
June 22, 2025 at 8:48 PM
I've been finding a way to get chatGPT to talk in a tone I haven't seen/read it take on before... interesting...
Just a few examples here. Note that the use of 'bold' was chatGPT's own choice, and I had not mentioned anything about safety nets in my interactions in this session.
Just a few examples here. Note that the use of 'bold' was chatGPT's own choice, and I had not mentioned anything about safety nets in my interactions in this session.
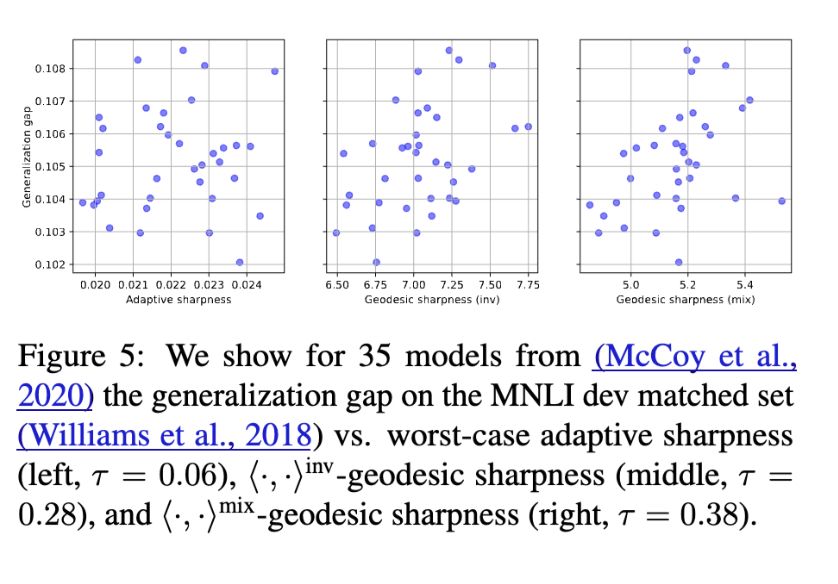
[6a/8] 🔦 Why does this matter?
Perturbations are no longer arbitrary—they respect functional equivalences in transformer weights.
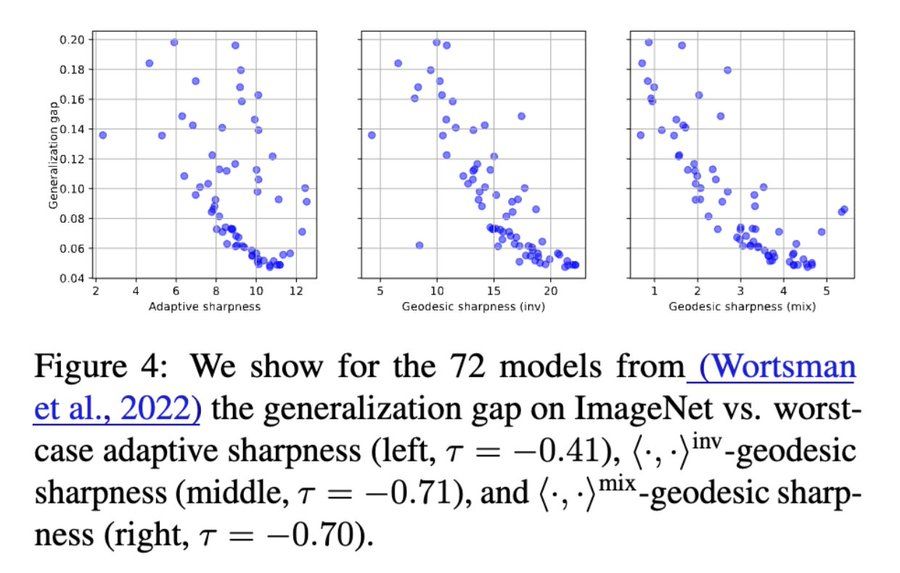
Result: Geodesic sharpness shows clearer, stronger correlations (as measured by the tau correlation coefficient) with generalization. 📈
Perturbations are no longer arbitrary—they respect functional equivalences in transformer weights.
Result: Geodesic sharpness shows clearer, stronger correlations (as measured by the tau correlation coefficient) with generalization. 📈
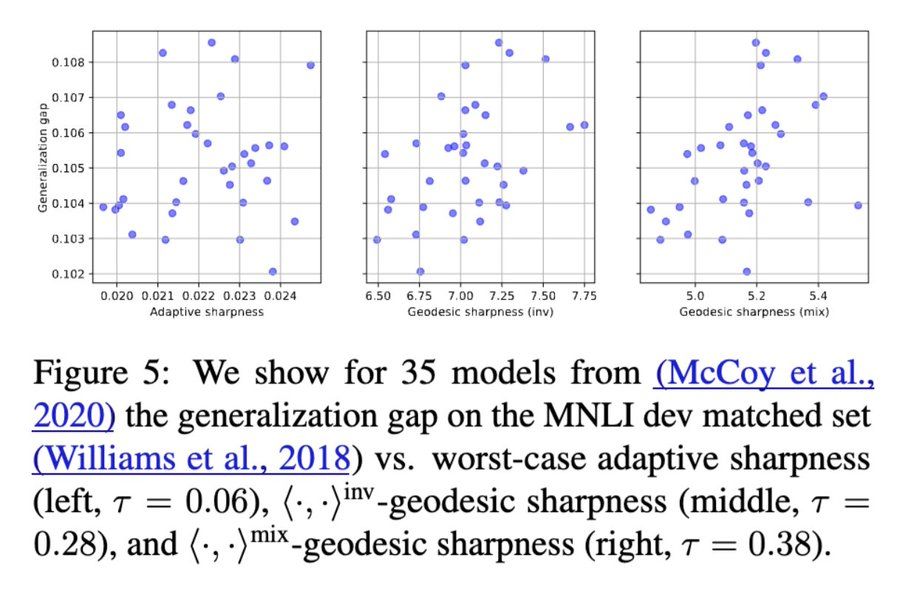
May 9, 2025 at 12:46 PM
[6a/8] 🔦 Why does this matter?
Perturbations are no longer arbitrary—they respect functional equivalences in transformer weights.
Result: Geodesic sharpness shows clearer, stronger correlations (as measured by the tau correlation coefficient) with generalization. 📈
Perturbations are no longer arbitrary—they respect functional equivalences in transformer weights.
Result: Geodesic sharpness shows clearer, stronger correlations (as measured by the tau correlation coefficient) with generalization. 📈
[5a/8] Our solution: ✨Ge🎯desic Sharpness✨
We need to redefine sharpness and measure it not directly in parameter space, but on a symmetry-aware quotient manifold.
We need to redefine sharpness and measure it not directly in parameter space, but on a symmetry-aware quotient manifold.
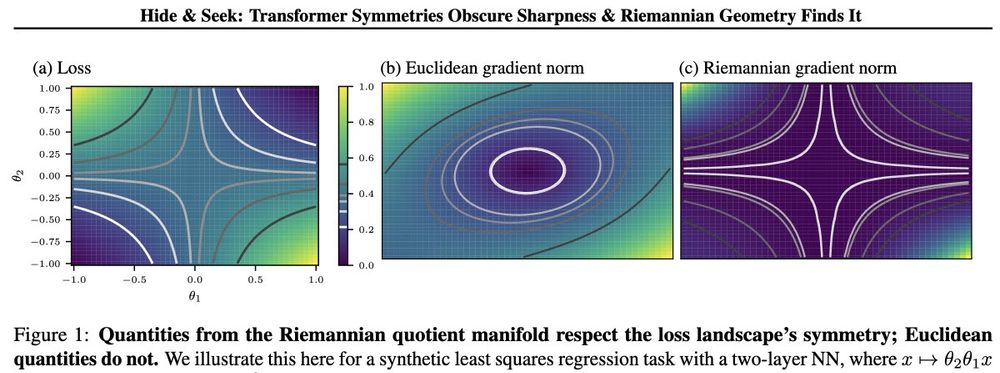
May 9, 2025 at 12:46 PM
[5a/8] Our solution: ✨Ge🎯desic Sharpness✨
We need to redefine sharpness and measure it not directly in parameter space, but on a symmetry-aware quotient manifold.
We need to redefine sharpness and measure it not directly in parameter space, but on a symmetry-aware quotient manifold.
[4/8] The disconnect between the geometry of the loss landscape and the geometry of differential objects (e.g. the loss gradient norm) is already present for extremely simple models, i.e., for linear 2-layer networks with scalar weights.


May 9, 2025 at 12:46 PM
[4/8] The disconnect between the geometry of the loss landscape and the geometry of differential objects (e.g. the loss gradient norm) is already present for extremely simple models, i.e., for linear 2-layer networks with scalar weights.
[2/8] 📌 Sharpness falls flat for transformers.
Sharpness (flat minima) often predicts how well models generalize. But Andriushchenko et al. (2023) found that transformers consistently break this intuition. Why?
Sharpness (flat minima) often predicts how well models generalize. But Andriushchenko et al. (2023) found that transformers consistently break this intuition. Why?
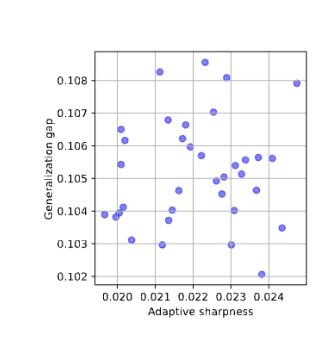
May 9, 2025 at 12:46 PM
[2/8] 📌 Sharpness falls flat for transformers.
Sharpness (flat minima) often predicts how well models generalize. But Andriushchenko et al. (2023) found that transformers consistently break this intuition. Why?
Sharpness (flat minima) often predicts how well models generalize. But Andriushchenko et al. (2023) found that transformers consistently break this intuition. Why?
🧵 ✨ Hide & Seek: Transformer Symmetries Obscure Sharpness & Riemannian Geometry Finds It ✨
Excited to announce our paper on factoring out param symmetries to better predict generalization in transformers ( #ICML25 spotlight! 🎉)
Amazing work by @marvinfsilva.bsky.social and Felix Dangel.
👇
Excited to announce our paper on factoring out param symmetries to better predict generalization in transformers ( #ICML25 spotlight! 🎉)
Amazing work by @marvinfsilva.bsky.social and Felix Dangel.
👇
May 9, 2025 at 12:46 PM
🧵 ✨ Hide & Seek: Transformer Symmetries Obscure Sharpness & Riemannian Geometry Finds It ✨
Excited to announce our paper on factoring out param symmetries to better predict generalization in transformers ( #ICML25 spotlight! 🎉)
Amazing work by @marvinfsilva.bsky.social and Felix Dangel.
👇
Excited to announce our paper on factoring out param symmetries to better predict generalization in transformers ( #ICML25 spotlight! 🎉)
Amazing work by @marvinfsilva.bsky.social and Felix Dangel.
👇
i love when in the middle of a familiar tune suddenly a groove presents itself... with a slow, natural build that takes its time
March 28, 2025 at 1:04 AM
i love when in the middle of a familiar tune suddenly a groove presents itself... with a slow, natural build that takes its time
Friday night is tango night… I love how mysterious that e minor chord at the end of the video sounds… it always has, and I don’t have a lot of things that sounds that way to me. I love that song.
March 22, 2025 at 12:24 AM
Friday night is tango night… I love how mysterious that e minor chord at the end of the video sounds… it always has, and I don’t have a lot of things that sounds that way to me. I love that song.
Practising Rachmaninoff which turned into a kind of focused improv exercise— a bit noodling but with a specific technical intention…
March 17, 2025 at 12:52 AM
Practising Rachmaninoff which turned into a kind of focused improv exercise— a bit noodling but with a specific technical intention…
a little bit of fiddling around making fun twinkly shit up on a sat night
February 16, 2025 at 1:18 AM
a little bit of fiddling around making fun twinkly shit up on a sat night
today i came across this book that a cousin of mine (3x removed) wrote. i've seen some of his other stuff, but this little elementary introduction to variational problems is new to me🙂. my grandmother knew him in her childhood and he used to show her math stuff for fun.
archive.org/details/lyus...
archive.org/details/lyus...

February 14, 2025 at 4:35 AM
today i came across this book that a cousin of mine (3x removed) wrote. i've seen some of his other stuff, but this little elementary introduction to variational problems is new to me🙂. my grandmother knew him in her childhood and he used to show her math stuff for fun.
archive.org/details/lyus...
archive.org/details/lyus...
Next day. Another section. Played through this ~50x, in different rhythms, hands separate, together,different articulations. All at 68 beats/min. Tmrw: same at 72 bpm. Can feel myself finally learning parts of this I never properly learned before. Would already be able to play much faster if I tried
February 9, 2025 at 7:21 PM
Next day. Another section. Played through this ~50x, in different rhythms, hands separate, together,different articulations. All at 68 beats/min. Tmrw: same at 72 bpm. Can feel myself finally learning parts of this I never properly learned before. Would already be able to play much faster if I tried
Practise 101: super slow metronome (it will go about 3 times faster than this, which is quite fast), and playing in rhythms (allows finding micro-moments to relax, among other benefits). At the beginning you might not hear metronome well because the notes overlap exactly with it, Ie accurate.
February 8, 2025 at 7:49 PM
Practise 101: super slow metronome (it will go about 3 times faster than this, which is quite fast), and playing in rhythms (allows finding micro-moments to relax, among other benefits). At the beginning you might not hear metronome well because the notes overlap exactly with it, Ie accurate.
when AI says one thing [fig1], but then [as you pointed out] see [fig2, fig3]. But then when phrased the right way, google actually came up with nothing [fig 4] Nothing at all!




February 7, 2025 at 5:32 PM
when AI says one thing [fig1], but then [as you pointed out] see [fig2, fig3]. But then when phrased the right way, google actually came up with nothing [fig 4] Nothing at all!
Fun pro tip: when practising this Rachmaninoff prelude, put the metronome on 2 and 4. Some of the stuff got a little messhy here but it was worth it this way…
February 6, 2025 at 10:06 PM
Fun pro tip: when practising this Rachmaninoff prelude, put the metronome on 2 and 4. Some of the stuff got a little messhy here but it was worth it this way…
Previous video was practising. This one is just playing a little, just following wherever it feels nice to go.
February 3, 2025 at 2:35 AM
Previous video was practising. This one is just playing a little, just following wherever it feels nice to go.
Gonna post practise videos: carefully structured #exercises I make up, to teach myself new stuff. Here’s a tricky passage from #Rachmaninoff. I set metronome to a 2-3 clave rhythm, then i snap on 1 & 3, then i #syncopate & add bass as a tumbao, and syncopate RH & add as #Afro-Cuban montuno. #fun
February 2, 2025 at 7:58 PM
Gonna post practise videos: carefully structured #exercises I make up, to teach myself new stuff. Here’s a tricky passage from #Rachmaninoff. I set metronome to a 2-3 clave rhythm, then i snap on 1 & 3, then i #syncopate & add bass as a tumbao, and syncopate RH & add as #Afro-Cuban montuno. #fun
What's happening in the gen space right now is WILD.
****Unleash your CREATIVITY, right NOW!!****
No time to build your prompting skills? No problem!
Just insert *any* of the discs into the machine and then press the "PLAY" button. You won't believe the music that will come out!!!!
****Unleash your CREATIVITY, right NOW!!****
No time to build your prompting skills? No problem!
Just insert *any* of the discs into the machine and then press the "PLAY" button. You won't believe the music that will come out!!!!


December 19, 2024 at 6:31 PM
What's happening in the gen space right now is WILD.
****Unleash your CREATIVITY, right NOW!!****
No time to build your prompting skills? No problem!
Just insert *any* of the discs into the machine and then press the "PLAY" button. You won't believe the music that will come out!!!!
****Unleash your CREATIVITY, right NOW!!****
No time to build your prompting skills? No problem!
Just insert *any* of the discs into the machine and then press the "PLAY" button. You won't believe the music that will come out!!!!
Another cool bonus: We can explain *why* it leads to perceptually-aligned gradients.
6/n
6/n

December 12, 2024 at 7:44 AM
Another cool bonus: We can explain *why* it leads to perceptually-aligned gradients.
6/n
6/n
Crucially: even if the diffusion model only has access to the same dataset (X) as the classifier, then this still helps a lot!
Cool bonus: this improves classifier-guided diffusion, and it leads to *perceptually aligned gradients* 👇.
5/n
Cool bonus: this improves classifier-guided diffusion, and it leads to *perceptually aligned gradients* 👇.
5/n

December 12, 2024 at 7:44 AM
Crucially: even if the diffusion model only has access to the same dataset (X) as the classifier, then this still helps a lot!
Cool bonus: this improves classifier-guided diffusion, and it leads to *perceptually aligned gradients* 👇.
5/n
Cool bonus: this improves classifier-guided diffusion, and it leads to *perceptually aligned gradients* 👇.
5/n
Given a training example, noising it pushes it off the data manifold, and then denoising pulls it back towards the manifold, but… not necessarily towards the same place it came from… so this becomes a useful new example!
4/n
4/n

December 12, 2024 at 7:44 AM
Given a training example, noising it pushes it off the data manifold, and then denoising pulls it back towards the manifold, but… not necessarily towards the same place it came from… so this becomes a useful new example!
4/n
4/n
When can we use generator G, trained on a dataset X, to produce new data X', s.t. training S on X' outperforms training S on X? (see great discussion & articulation of this Q: x.com/phillip_isol... ).
@cssastry.bsky.social will present work on this on Thurs 11am-2pm, Poster 1804 #NeurIPS2024 :
1/n
@cssastry.bsky.social will present work on this on Thurs 11am-2pm, Poster 1804 #NeurIPS2024 :
1/n

December 12, 2024 at 7:44 AM
When can we use generator G, trained on a dataset X, to produce new data X', s.t. training S on X' outperforms training S on X? (see great discussion & articulation of this Q: x.com/phillip_isol... ).
@cssastry.bsky.social will present work on this on Thurs 11am-2pm, Poster 1804 #NeurIPS2024 :
1/n
@cssastry.bsky.social will present work on this on Thurs 11am-2pm, Poster 1804 #NeurIPS2024 :
1/n
Fun chatgpt use case: I generate code to make figs for ML exams. Here's a figure for intro ML where the Q is to match optimizer path with parameters/description (e.g. step size, etc). Contours are from a GMM, so it's easy for me to control the shapes. Red line shows actual GD path. It took minutes.

November 20, 2024 at 5:51 PM
Fun chatgpt use case: I generate code to make figs for ML exams. Here's a figure for intro ML where the Q is to match optimizer path with parameters/description (e.g. step size, etc). Contours are from a GMM, so it's easy for me to control the shapes. Red line shows actual GD path. It took minutes.