




sageev
@sageev.bsky.social
"a symptom of an approaching nervous breakdown is the belief that one's work is terribly important"--bertrand russell
ML, music, generative models, robustness, ML & health
curr & prev affils:
Dalhousie University (CS), Vector Institute, Google Research
ML, music, generative models, robustness, ML & health
curr & prev affils:
Dalhousie University (CS), Vector Institute, Google Research
Yeah! (at least for most of it)
May 21, 2025 at 9:16 AM
Yeah! (at least for most of it)
Is the website info about it incorrect? (Says wkshops on 18 & 19)
May 19, 2025 at 6:07 PM
Is the website info about it incorrect? (Says wkshops on 18 & 19)
[8/8] 📖
"Hide & Seek: Transformer Symmetries Obscure Sharpness & Riemannian Geometry Finds It"
🎓 Marvin F. da Silva, Felix Dangel, and Sageev Oore
🔗 arxiv.org/abs/2505.05409
Questions/comments? 👇we'd love to hear from you!
#ICML2025 #ML #Transformers #Riemannian #Geometry #DeepLearning #Symmetry
"Hide & Seek: Transformer Symmetries Obscure Sharpness & Riemannian Geometry Finds It"
🎓 Marvin F. da Silva, Felix Dangel, and Sageev Oore
🔗 arxiv.org/abs/2505.05409
Questions/comments? 👇we'd love to hear from you!
#ICML2025 #ML #Transformers #Riemannian #Geometry #DeepLearning #Symmetry

Hide & Seek: Transformer Symmetries Obscure Sharpness & Riemannian Geometry Finds It
The concept of sharpness has been successfully applied to traditional architectures like MLPs and CNNs to predict their generalization. For transformers, however, recent work reported weak correlation...
arxiv.org
May 9, 2025 at 12:46 PM
[8/8] 📖
"Hide & Seek: Transformer Symmetries Obscure Sharpness & Riemannian Geometry Finds It"
🎓 Marvin F. da Silva, Felix Dangel, and Sageev Oore
🔗 arxiv.org/abs/2505.05409
Questions/comments? 👇we'd love to hear from you!
#ICML2025 #ML #Transformers #Riemannian #Geometry #DeepLearning #Symmetry
"Hide & Seek: Transformer Symmetries Obscure Sharpness & Riemannian Geometry Finds It"
🎓 Marvin F. da Silva, Felix Dangel, and Sageev Oore
🔗 arxiv.org/abs/2505.05409
Questions/comments? 👇we'd love to hear from you!
#ICML2025 #ML #Transformers #Riemannian #Geometry #DeepLearning #Symmetry
[7b/8] We see this even for traditional sharpness measures in the diagonal networks we study, but it is particularly striking in the vision transformers we study, where geodesically sharper minima actually generalize better!
Maybe flatness isn’t universal after all—context matters.
Maybe flatness isn’t universal after all—context matters.
May 9, 2025 at 12:46 PM
[7b/8] We see this even for traditional sharpness measures in the diagonal networks we study, but it is particularly striking in the vision transformers we study, where geodesically sharper minima actually generalize better!
Maybe flatness isn’t universal after all—context matters.
Maybe flatness isn’t universal after all—context matters.
[7a/8] 🔥 Surprising twist:
Interestingly, flatter is not always better!
Interestingly, flatter is not always better!
May 9, 2025 at 12:46 PM
[7a/8] 🔥 Surprising twist:
Interestingly, flatter is not always better!
Interestingly, flatter is not always better!
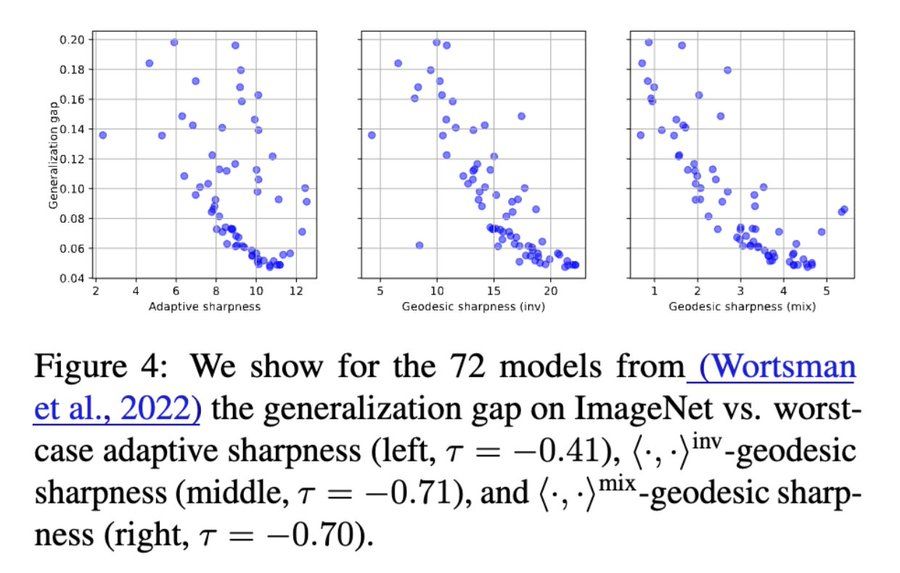
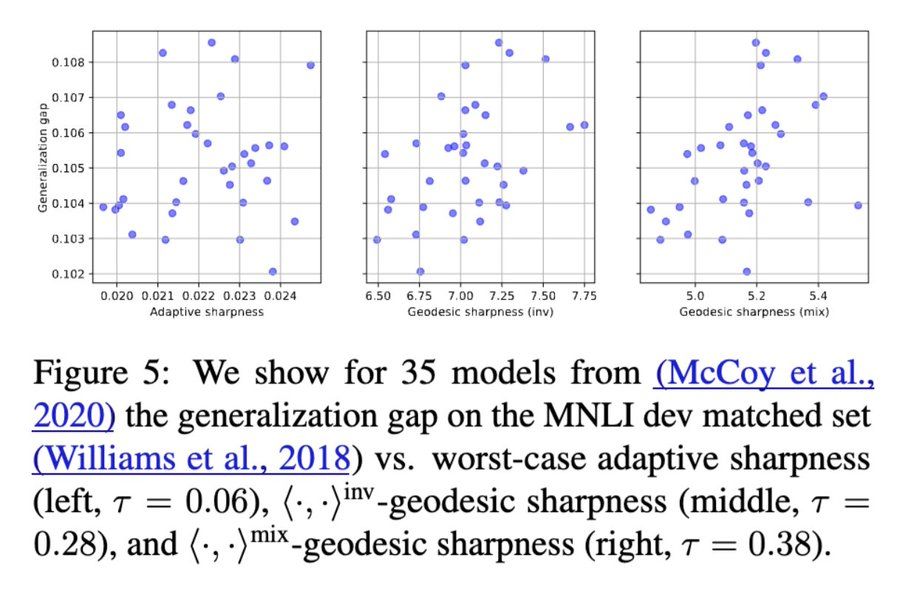
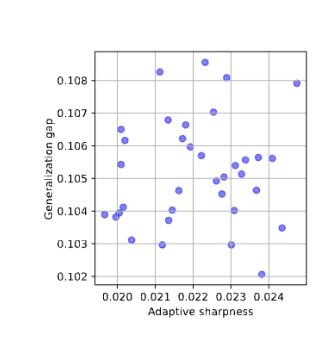
[6b/8]
🖼️ Vision Transformers (ImageNet): -0.41 (adaptive sharpness) → -0.71 (geodesic sharpness)
💬 BERT fine-tuned on MNLI: 0.06 (adaptive sharpness) → 0.38 (geodesic sharpness)
🖼️ Vision Transformers (ImageNet): -0.41 (adaptive sharpness) → -0.71 (geodesic sharpness)
💬 BERT fine-tuned on MNLI: 0.06 (adaptive sharpness) → 0.38 (geodesic sharpness)
May 9, 2025 at 12:46 PM
[6b/8]
🖼️ Vision Transformers (ImageNet): -0.41 (adaptive sharpness) → -0.71 (geodesic sharpness)
💬 BERT fine-tuned on MNLI: 0.06 (adaptive sharpness) → 0.38 (geodesic sharpness)
🖼️ Vision Transformers (ImageNet): -0.41 (adaptive sharpness) → -0.71 (geodesic sharpness)
💬 BERT fine-tuned on MNLI: 0.06 (adaptive sharpness) → 0.38 (geodesic sharpness)
[6a/8] 🔦 Why does this matter?
Perturbations are no longer arbitrary—they respect functional equivalences in transformer weights.
Result: Geodesic sharpness shows clearer, stronger correlations (as measured by the tau correlation coefficient) with generalization. 📈
Perturbations are no longer arbitrary—they respect functional equivalences in transformer weights.
Result: Geodesic sharpness shows clearer, stronger correlations (as measured by the tau correlation coefficient) with generalization. 📈
May 9, 2025 at 12:46 PM
[6a/8] 🔦 Why does this matter?
Perturbations are no longer arbitrary—they respect functional equivalences in transformer weights.
Result: Geodesic sharpness shows clearer, stronger correlations (as measured by the tau correlation coefficient) with generalization. 📈
Perturbations are no longer arbitrary—they respect functional equivalences in transformer weights.
Result: Geodesic sharpness shows clearer, stronger correlations (as measured by the tau correlation coefficient) with generalization. 📈
[5c/8] Geodesic Sharpness
Whereas traditional sharpness measures are evaluated inside an L^2 ball, we look at a geodesic ball in this symmetry-corrected space, using tools from Riemannian geometry.
Whereas traditional sharpness measures are evaluated inside an L^2 ball, we look at a geodesic ball in this symmetry-corrected space, using tools from Riemannian geometry.
May 9, 2025 at 12:46 PM
[5c/8] Geodesic Sharpness
Whereas traditional sharpness measures are evaluated inside an L^2 ball, we look at a geodesic ball in this symmetry-corrected space, using tools from Riemannian geometry.
Whereas traditional sharpness measures are evaluated inside an L^2 ball, we look at a geodesic ball in this symmetry-corrected space, using tools from Riemannian geometry.
[5b/8] Geodesic Sharpness
Instead of considering the usual Euclidean metric, we look at metrics invariant both to symmetries of the attention mechanism and to previously studied re-scaling symmetries.
Instead of considering the usual Euclidean metric, we look at metrics invariant both to symmetries of the attention mechanism and to previously studied re-scaling symmetries.
May 9, 2025 at 12:46 PM
[5b/8] Geodesic Sharpness
Instead of considering the usual Euclidean metric, we look at metrics invariant both to symmetries of the attention mechanism and to previously studied re-scaling symmetries.
Instead of considering the usual Euclidean metric, we look at metrics invariant both to symmetries of the attention mechanism and to previously studied re-scaling symmetries.
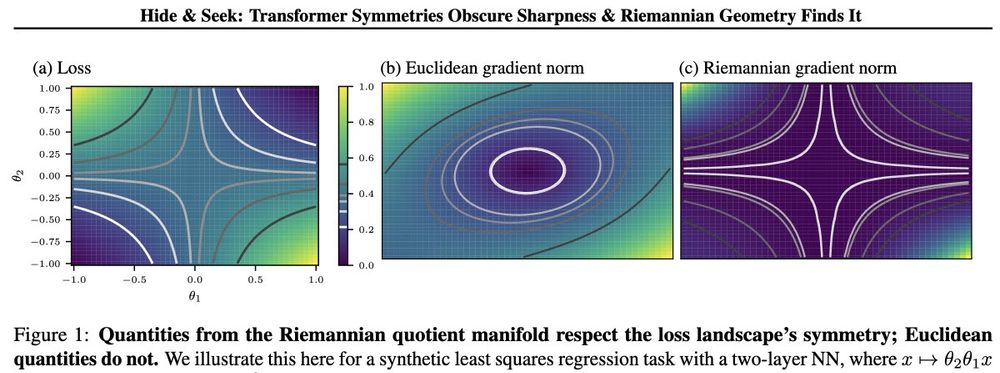
[5a/8] Our solution: ✨Ge🎯desic Sharpness✨
We need to redefine sharpness and measure it not directly in parameter space, but on a symmetry-aware quotient manifold.
We need to redefine sharpness and measure it not directly in parameter space, but on a symmetry-aware quotient manifold.
May 9, 2025 at 12:46 PM
[5a/8] Our solution: ✨Ge🎯desic Sharpness✨
We need to redefine sharpness and measure it not directly in parameter space, but on a symmetry-aware quotient manifold.
We need to redefine sharpness and measure it not directly in parameter space, but on a symmetry-aware quotient manifold.
[4/8] The disconnect between the geometry of the loss landscape and the geometry of differential objects (e.g. the loss gradient norm) is already present for extremely simple models, i.e., for linear 2-layer networks with scalar weights.


May 9, 2025 at 12:46 PM
[4/8] The disconnect between the geometry of the loss landscape and the geometry of differential objects (e.g. the loss gradient norm) is already present for extremely simple models, i.e., for linear 2-layer networks with scalar weights.
[3b/8] This obscures the link between sharpness and generalization. Works such as Kwon et al. (2021) introduce notions of adaptive sharpness that are invariant to re-scaling.
Transformers, however, have a richer set of symmetries that aren’t accounted for by traditional adaptive sharpness measures.
Transformers, however, have a richer set of symmetries that aren’t accounted for by traditional adaptive sharpness measures.
May 9, 2025 at 12:46 PM
[3b/8] This obscures the link between sharpness and generalization. Works such as Kwon et al. (2021) introduce notions of adaptive sharpness that are invariant to re-scaling.
Transformers, however, have a richer set of symmetries that aren’t accounted for by traditional adaptive sharpness measures.
Transformers, however, have a richer set of symmetries that aren’t accounted for by traditional adaptive sharpness measures.
[3a/8] 🔍 But why?
Traditional sharpness metrics (like Hessian-based measures or gradient norms) don't account for symmetries, directions in parameter space that don't change the model's output. They measure sharpness along directions that may be irrelevant, making results noisy or meaningless.
Traditional sharpness metrics (like Hessian-based measures or gradient norms) don't account for symmetries, directions in parameter space that don't change the model's output. They measure sharpness along directions that may be irrelevant, making results noisy or meaningless.
May 9, 2025 at 12:46 PM
[3a/8] 🔍 But why?
Traditional sharpness metrics (like Hessian-based measures or gradient norms) don't account for symmetries, directions in parameter space that don't change the model's output. They measure sharpness along directions that may be irrelevant, making results noisy or meaningless.
Traditional sharpness metrics (like Hessian-based measures or gradient norms) don't account for symmetries, directions in parameter space that don't change the model's output. They measure sharpness along directions that may be irrelevant, making results noisy or meaningless.
[2/8] 📌 Sharpness falls flat for transformers.
Sharpness (flat minima) often predicts how well models generalize. But Andriushchenko et al. (2023) found that transformers consistently break this intuition. Why?
Sharpness (flat minima) often predicts how well models generalize. But Andriushchenko et al. (2023) found that transformers consistently break this intuition. Why?
May 9, 2025 at 12:46 PM
[2/8] 📌 Sharpness falls flat for transformers.
Sharpness (flat minima) often predicts how well models generalize. But Andriushchenko et al. (2023) found that transformers consistently break this intuition. Why?
Sharpness (flat minima) often predicts how well models generalize. But Andriushchenko et al. (2023) found that transformers consistently break this intuition. Why?