Posts
Media
Videos
Starter Packs
Pinned


Reposted by Samira

Reposted by Samira


Reposted by Samira


Samira
@samiraabnar.bsky.social
· Jan 28
Samira
@samiraabnar.bsky.social
· Jan 28

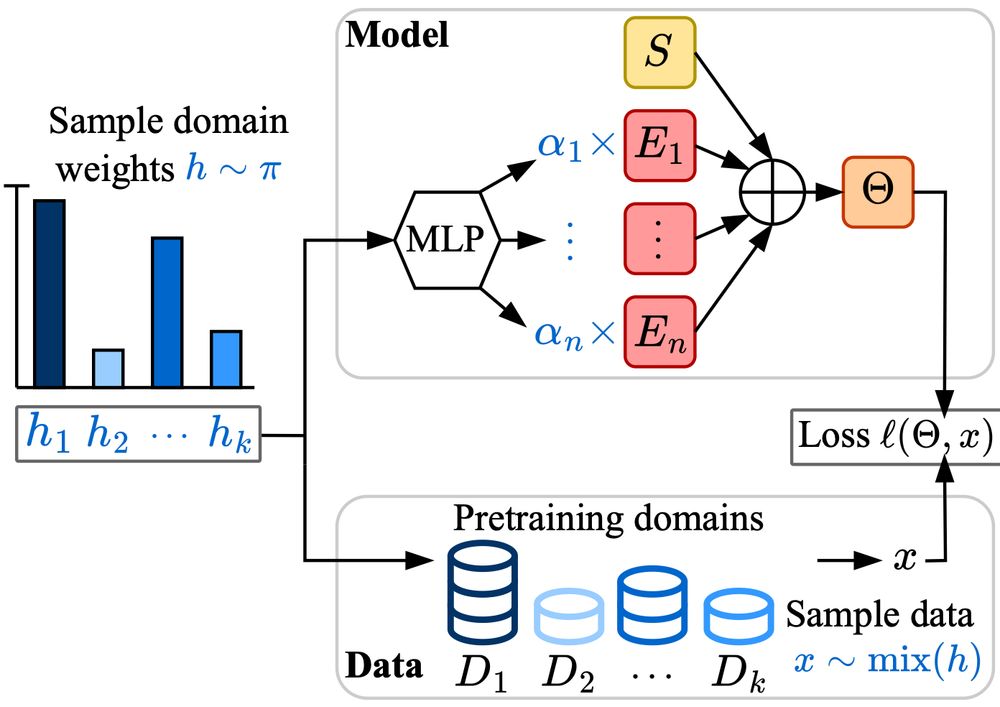
Parameters vs FLOPs: Scaling Laws for Optimal Sparsity for Mixture-of-Experts Language Models
Scaling the capacity of language models has consistently proven to be a reliable approach for improving performance and unlocking new capabilities. Capacity can be primarily defined by two dimensions:...
arxiv.org
Samira
@samiraabnar.bsky.social
· Jan 28






