
Sam Nastase
@samnastase.bsky.social
2.4K followers
750 following
62 posts
assistant professor of psychology at USC丨he/him丨semiprofessional dungeon master丨https://snastase.github.io/
Posts
Media
Videos
Starter Packs
Pinned

Reposted by Sam Nastase



Reposted by Sam Nastase



Reposted by Sam Nastase





Reposted by Sam Nastase



Reposted by Sam Nastase


Reposted by Sam Nastase


Reposted by Sam Nastase

CNSP Workshop
@cnspworkshop.bsky.social
· Aug 22
Reposted by Sam Nastase

Reposted by Sam Nastase







Sam Nastase
@samnastase.bsky.social
· Jun 30

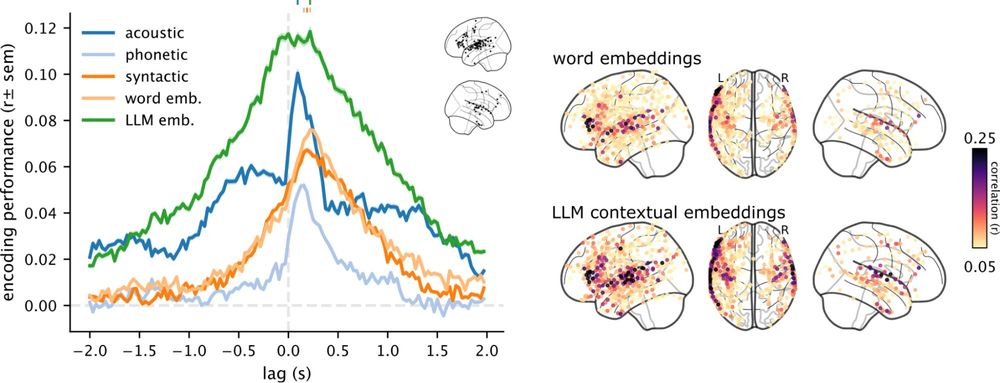
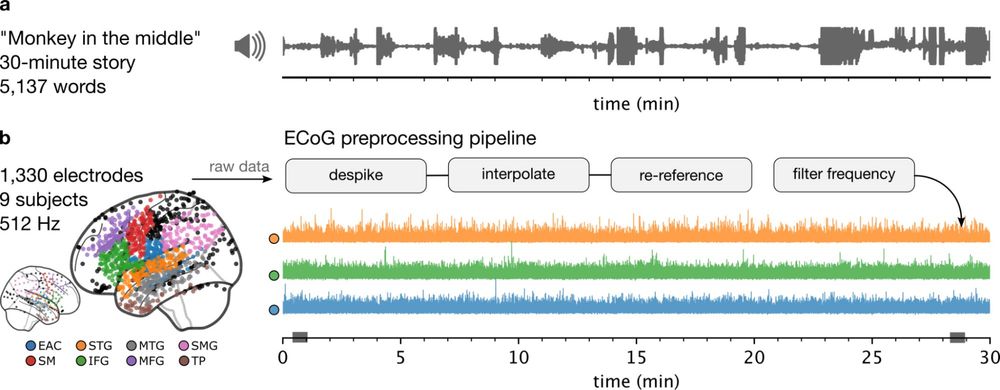
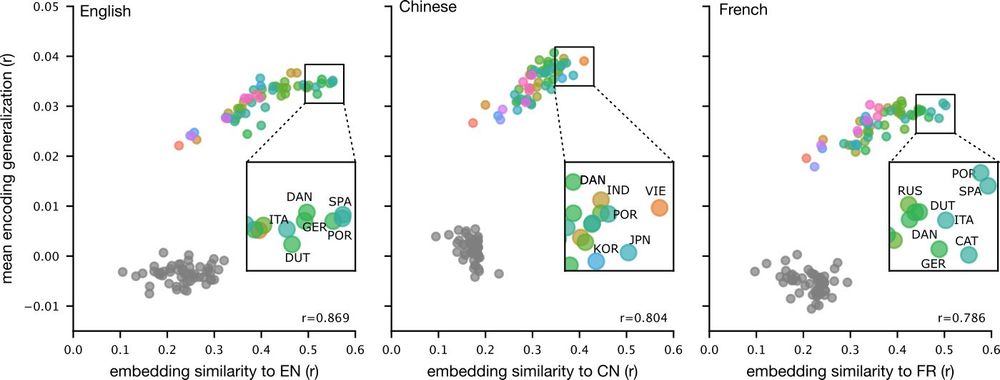
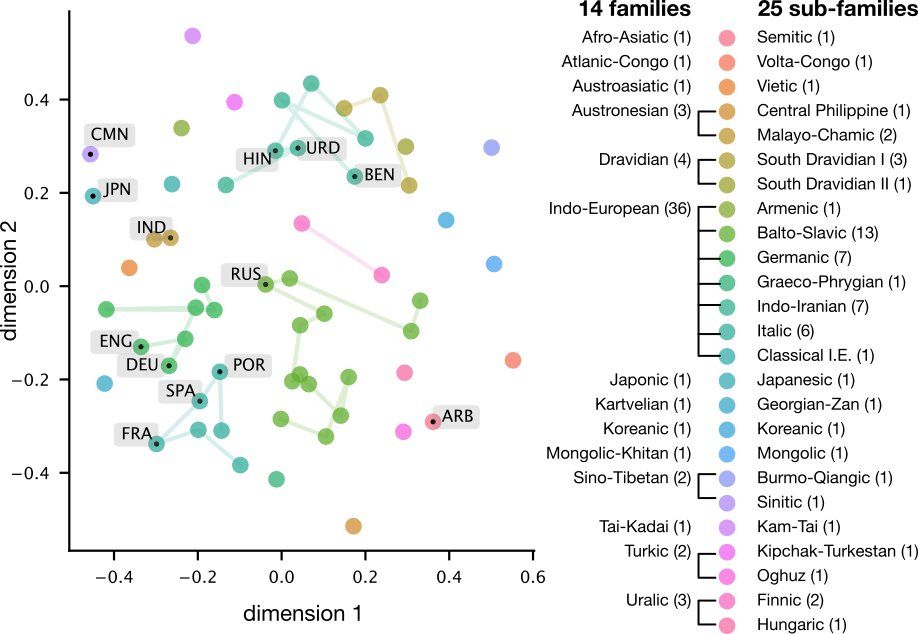
Brains and language models converge on a shared conceptual space across different languages
Human languages differ widely in their forms, each having distinct sounds, scripts, and syntax. Yet, they can all convey similar meaning. Do different languages converge on a shared neural substrate f...
arxiv.org
Sam Nastase
@samnastase.bsky.social
· Jun 30
Sam Nastase
@samnastase.bsky.social
· Jun 30
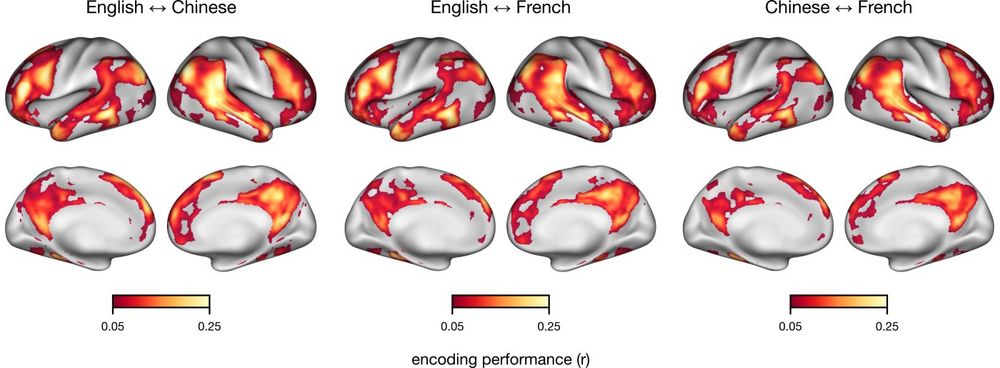
Sam Nastase
@samnastase.bsky.social
· Jun 30
Sam Nastase
@samnastase.bsky.social
· Jun 30