Thrilled to share with you our latest work: “Mixture of Cognitive Reasoners”, a modular transformer architecture inspired by the brain’s functional networks: language, logic, social reasoning, and world knowledge.
Thanks to my internship advisors Emmanuel Abbe and Samy Bengio at Apple, and my PhD advisor @abosselut.bsky.social at @icepfl.bsky.social for supervising this project!
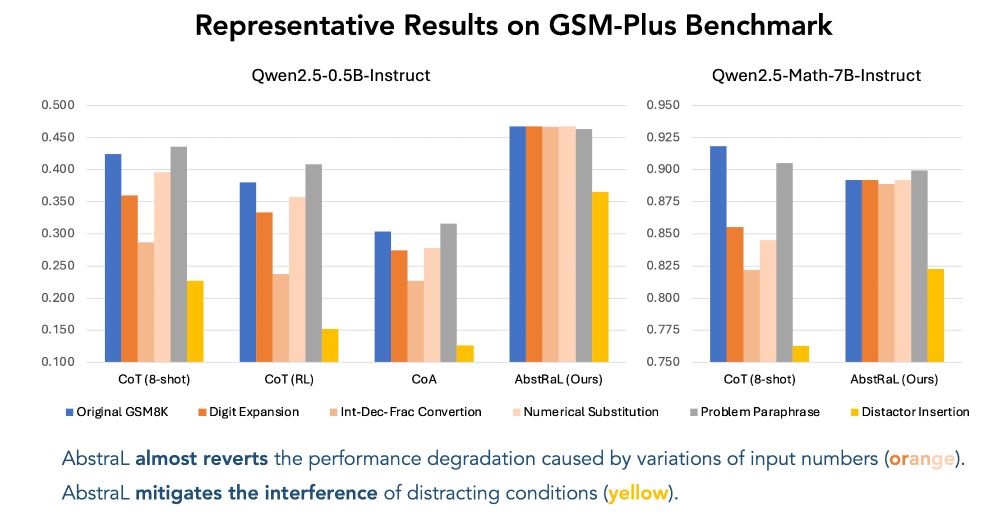
On perturbation benchmarks of grade school mathematics (GSM-Symbolic & GSM-Plus), AbstRaL almost reverts the performance drop caused by variations of input numbers, and also significantly mitigates the interference of distracting conditions added to the perturbed testing samples
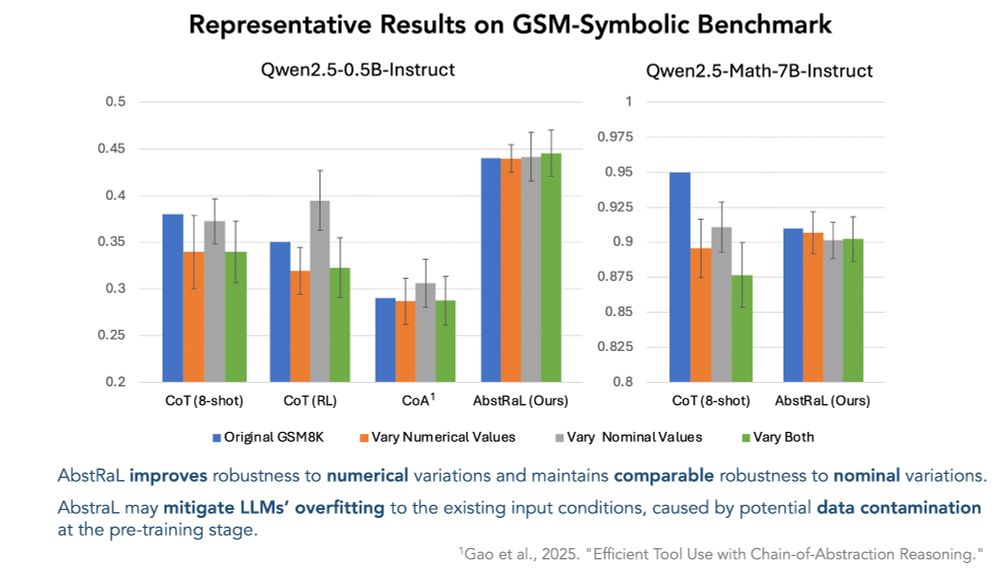
Results on various seed LLMs, including Mathstral, Llama3 and Qwen2.5 series, consistently demonstrate that AbstRaL reliably augments reasoning robustness, especially w.r.t. the shifts of input conditions in existing testing samples that may be leaked due to data contamination.
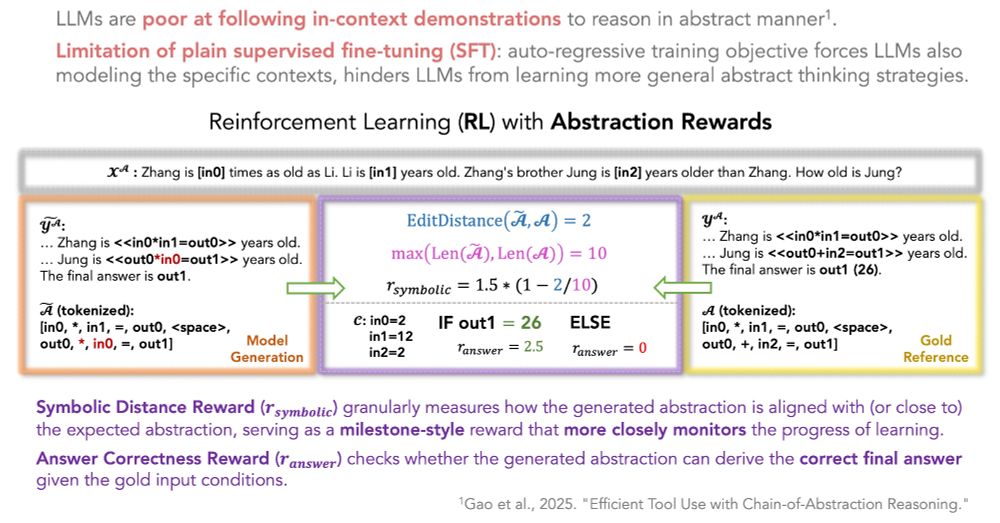
Facing the weaknesses of in-context learning and supervised fine-tuning, AbstRaL uses reinforcement learning (RL) with a new set of rewards to closely guide the construction of abstraction in the model generation, which effectively improves the faithfulness of abstract reasoning
AbstRaL adopts a granularly-decomposed abstract reasoning (GranulAR) schema, which enables LLMs to gradually construct the problem abstraction within a fine-grained reasoning chain, using their pre-learned strategies of chain-of-thought and Socratic problem decomposition.
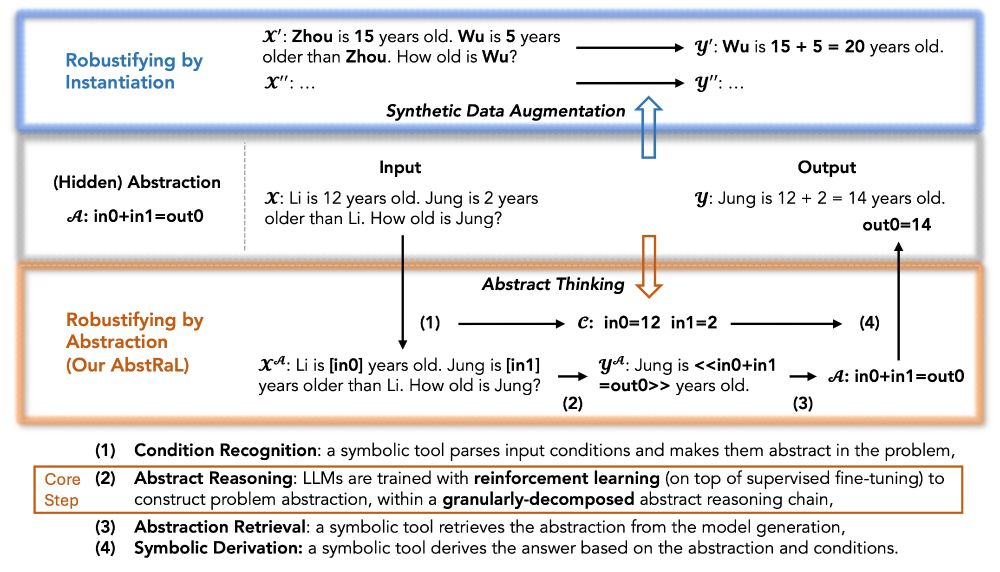
Instead of expensively creating more synthetic data to “instantiate” variations of problems, our approach learns to “abstract” reasoning problems. This not only helps counteract distribution shifts but also facilitates the connection to symbolic tools for deriving solutions.
NEW PAPER ALERT: Recent studies have shown that LLMs often lack robustness to distribution shifts in their reasoning. Our paper proposes a new method, AbstRaL, to augment LLMs’ reasoning robustness, by promoting their abstract thinking with granular reinforcement learning.
Thanks to my internship advisors Emmanuel Abbe and Samy Bengio at Apple, and my PhD advisor @abosselut.bsky.social at @icepfl.bsky.social for supervising this project!
On perturbation benchmarks of grade school mathematics (GSM-Symbolic & GSM-Plus), AbstRaL almost reverts the performance drop caused by variations of input numbers, and also significantly mitigates the interference of distracting conditions added to the perturbed testing samples
AbstRaL adopts a granularly-decomposed abstract reasoning (GranulAR) schema, which enables LLMs to gradually construct the problem abstraction within a fine-grained reasoning chain, using their pre-learned strategies of chain-of-thought and Socratic problem decomposition.
Instead of expensively creating more synthetic data to “instantiate” variations of problems, our approach learns to “abstract” reasoning problems. This not only helps counteract distribution shifts but also facilitates the connection to symbolic tools for deriving solutions.
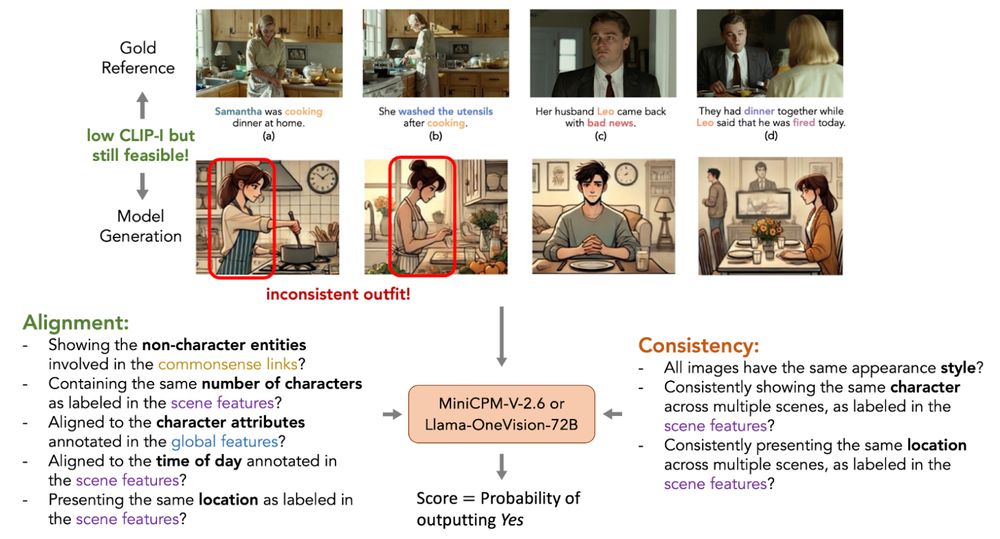
Our study of several testing cases illustrates that visual narratives generated by VLMs still suffer from obvious inconsistency flaws, even with the augmentation of knowledge constraints, which raises the call for future study on more robust visual narrative generators.
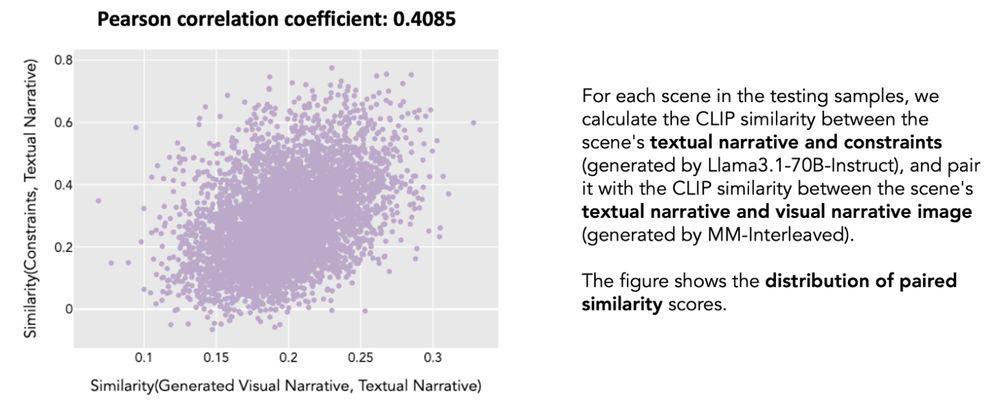
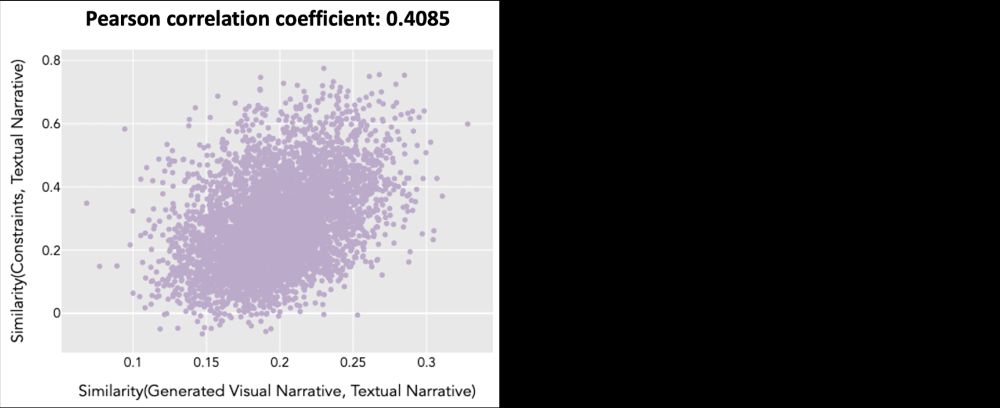
We also find a positive correlation between the knowledge constraints and the output visual narrative, w.r.t. their alignment to the input textual narrative, which highlights the significance of planning intermediate constraints to promote faithful visual narrative generation.
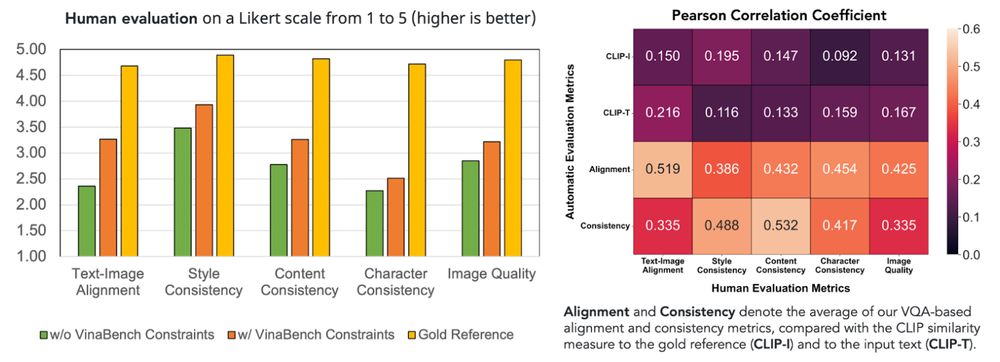
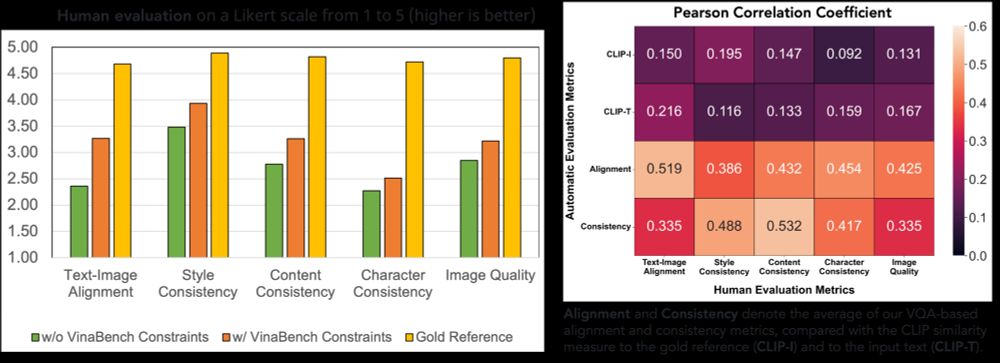
Our human evaluation (on five typical aspects) supports the results of our automatic evaluation. Besides, compared to traditional metrics based on CLIP similarity (CLIP-I and CLIP-T), our proposed alignment and consistency metrics have better correlation with human evaluation.
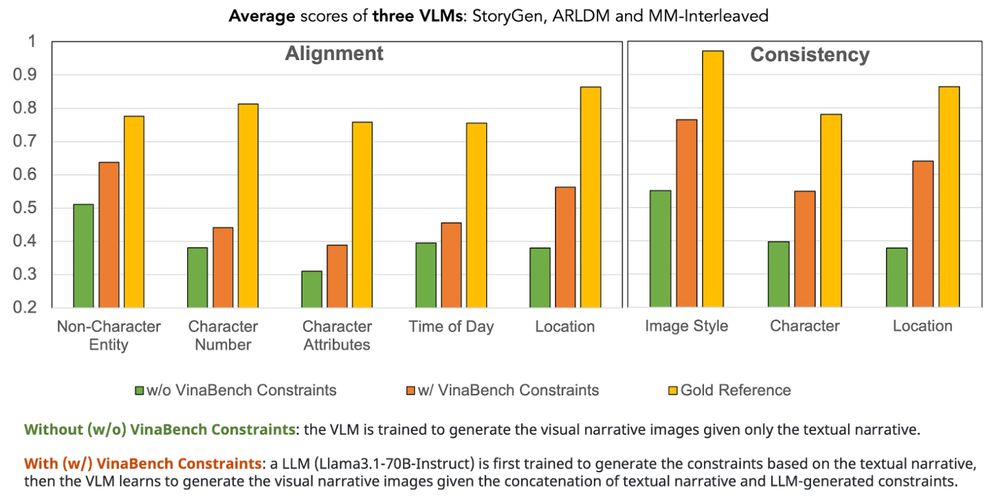
Our evaluation results on three VLMs all show that learning with VinaBench constraints improves visual narrative consistency and alignment to input text. However, visual narratives generated by VLMs fall behind the gold references, indicating still a large room of improvement.
Based on VinaBench constraints, we propose VQA-based metrics to closely evaluate the consistency of visual narratives and their alignment to the input text. Our metrics avoid skewing evaluation to irrelevant details in gold reference, and cover the checking of inconsistent flaws.
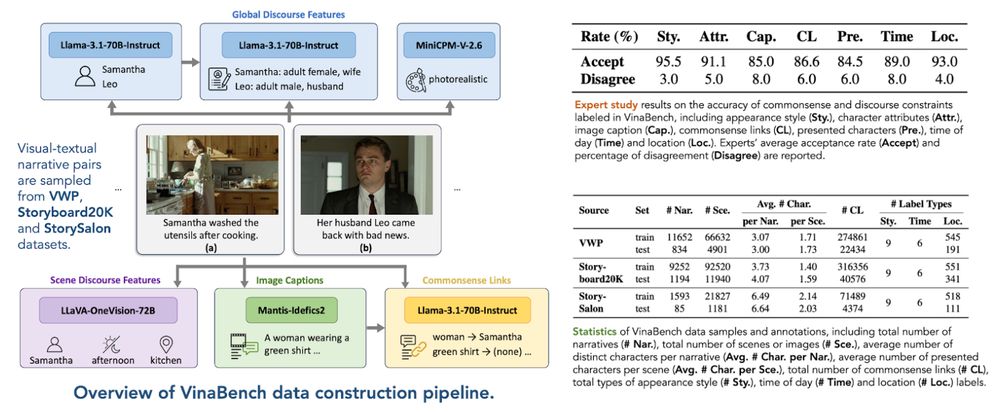
We prompt hybrid VLMs and LLMs to annotate the VinaBench knowledge constraints. Our expert study verifies that the annotations are reliable, with high acceptance rates for all types of constraint labels, each with a fairly low percentage of disagreement cases between the experts.
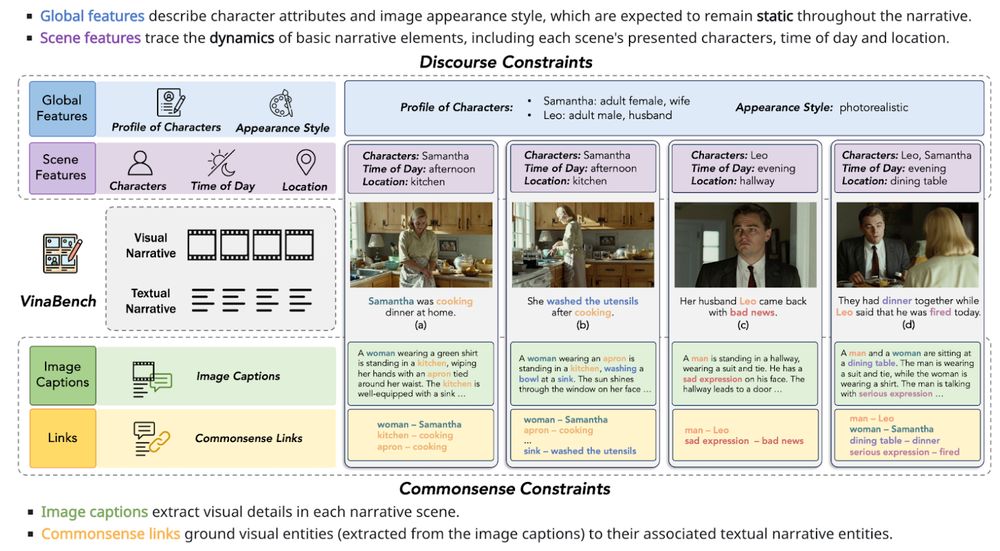
VinaBench augments existing visual-textual narrative pairs with discourse and commonsense knowledge constraints. The former traces static and dynamic features of the narrative process, while the latter consists of entity links that bridge the visual-textual manifestation gap.
NEW PAPER ALERT: Generating visual narratives to illustrate textual stories remains an open challenge, due to the lack of knowledge to constrain faithful and self-consistent generations. Our #CVPR2025 paper proposes a new benchmark, VinaBench, to address this challenge.
Our study of several testing cases illustrates that visual narratives generated by VLMs still suffer from obvious inconsistency flaws, even with the augmentation of knowledge constraints, which raises the call for future study on more robust visual narrative generators.
We also find a positive correlation between the knowledge constraints and the output visual narrative, w.r.t. their alignment to the input textual narrative, which highlights the significance of planning intermediate constraints to promote faithful visual narrative generation.
Our human evaluation (on five typical aspects) supports the results of our automatic evaluation. Besides, compared to traditional metrics based on CLIP similarity (CLIP-I and CLIP-T), our proposed alignment and consistency metrics have better correlation with human evaluation.