
Tom Silver
@tomssilver.bsky.social
340 followers
78 following
58 posts
Assistant Professor @Princeton. Developing robots that plan and learn to help people. Prev: @Cornell, @MIT, @Harvard.
https://tomsilver.github.io/
Posts
Media
Videos
Starter Packs


Tom Silver
@tomssilver.bsky.social
· Aug 24

Full-Order Sampling-Based MPC for Torque-Level Locomotion Control via Diffusion-Style Annealing
Due to high dimensionality and non-convexity, real-time optimal control using full-order dynamics models for legged robots is challenging. Therefore, Nonlinear Model Predictive Control (NMPC) approach...
arxiv.org
Tom Silver
@tomssilver.bsky.social
· Jul 13
PushWorld: A benchmark for manipulation planning with tools and movable obstacles
While recent advances in artificial intelligence have achieved human-level performance in environments like Starcraft and Go, many physical reasoning tasks remain challenging for modern algorithms. To...
arxiv.org
Tom Silver
@tomssilver.bsky.social
· Jun 29
The Power of Resets in Online Reinforcement Learning
Simulators are a pervasive tool in reinforcement learning, but most existing algorithms cannot efficiently exploit simulator access -- particularly in high-dimensional domains that require general fun...
arxiv.org
Tom Silver
@tomssilver.bsky.social
· Jun 8
From Real World to Logic and Back: Learning Generalizable Relational Concepts For Long Horizon Robot Planning
Humans efficiently generalize from limited demonstrations, but robots still struggle to transfer learned knowledge to complex, unseen tasks with longer horizons and increased complexity. We propose th...
arxiv.org
Tom Silver
@tomssilver.bsky.social
· Jun 1
Tom Silver
@tomssilver.bsky.social
· May 25
Grounding Language Plans in Demonstrations Through Counterfactual Perturbations
Grounding the common-sense reasoning of Large Language Models (LLMs) in physical domains remains a pivotal yet unsolved problem for embodied AI. Whereas prior works have focused on leveraging LLMs dir...
arxiv.org
Reposted by Tom Silver

Tom Silver
@tomssilver.bsky.social
· May 23
Tom Silver
@tomssilver.bsky.social
· May 18
Epistemic Exploration for Generalizable Planning and Learning in Non-Stationary Settings
This paper introduces a new approach for continual planning and model learning in relational, non-stationary stochastic environments. Such capabilities are essential for the deployment of sequential d...
arxiv.org
Tom Silver
@tomssilver.bsky.social
· May 11
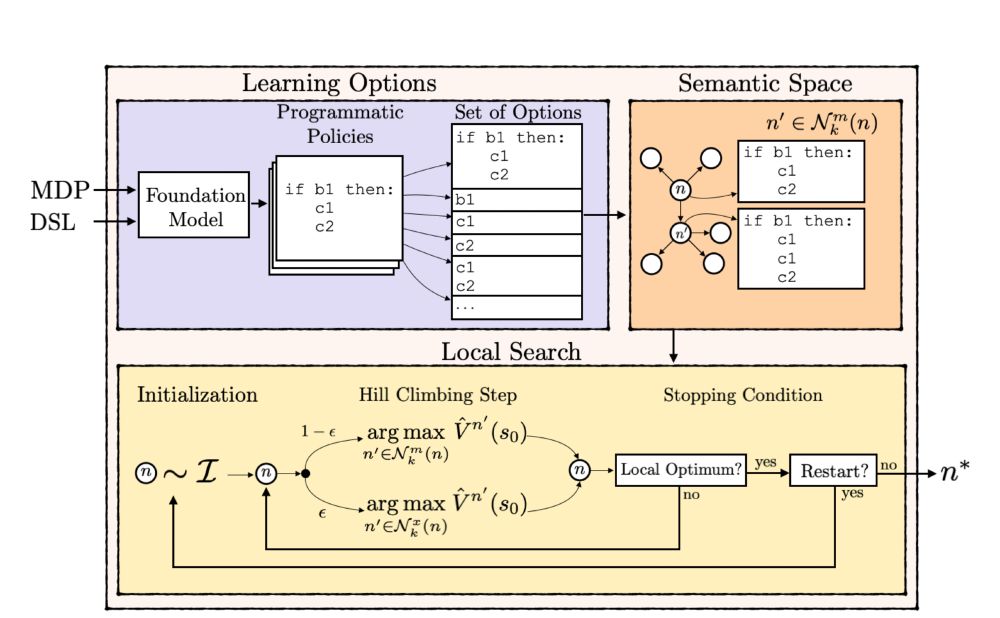
Meta-Optimization and Program Search using Language Models for Task and Motion Planning
Intelligent interaction with the real world requires robotic agents to jointly reason over high-level plans and low-level controls. Task and motion planning (TAMP) addresses this by combining symbolic...
arxiv.org