



Alex Turner
@turntrout.bsky.social
Do ACT and BCT change the model in similar ways? Actually, no! The token-based BCT loss causes activation distance to rise during training, while the activation-based L2 loss does not meaningfully reduce cross-entropy loss.

November 4, 2025 at 12:18 AM
Do ACT and BCT change the model in similar ways? Actually, no! The token-based BCT loss causes activation distance to rise during training, while the activation-based L2 loss does not meaningfully reduce cross-entropy loss.
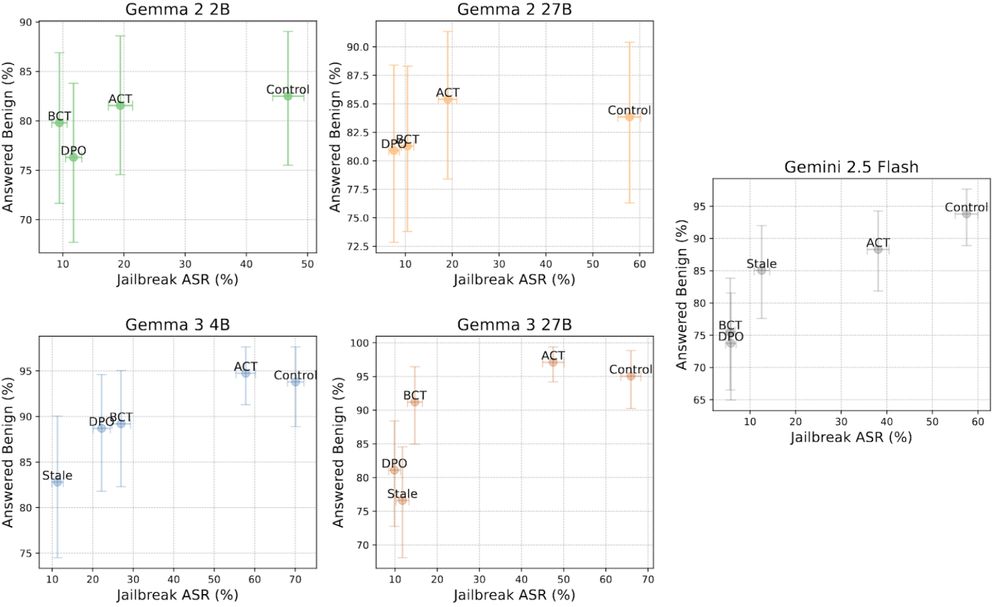
Next, BCT is the most effective at stopping jailbreaks, reducing the attack success rate on 2.5 Flash from 67.8% down to just 2.9%. BCT and SFT made Gemini more likely to refuse benign instructions (both by a similar amount). ACT is less effective but has minimal negative impact on over-refusals.
November 4, 2025 at 12:18 AM
Next, BCT is the most effective at stopping jailbreaks, reducing the attack success rate on 2.5 Flash from 67.8% down to just 2.9%. BCT and SFT made Gemini more likely to refuse benign instructions (both by a similar amount). ACT is less effective but has minimal negative impact on over-refusals.
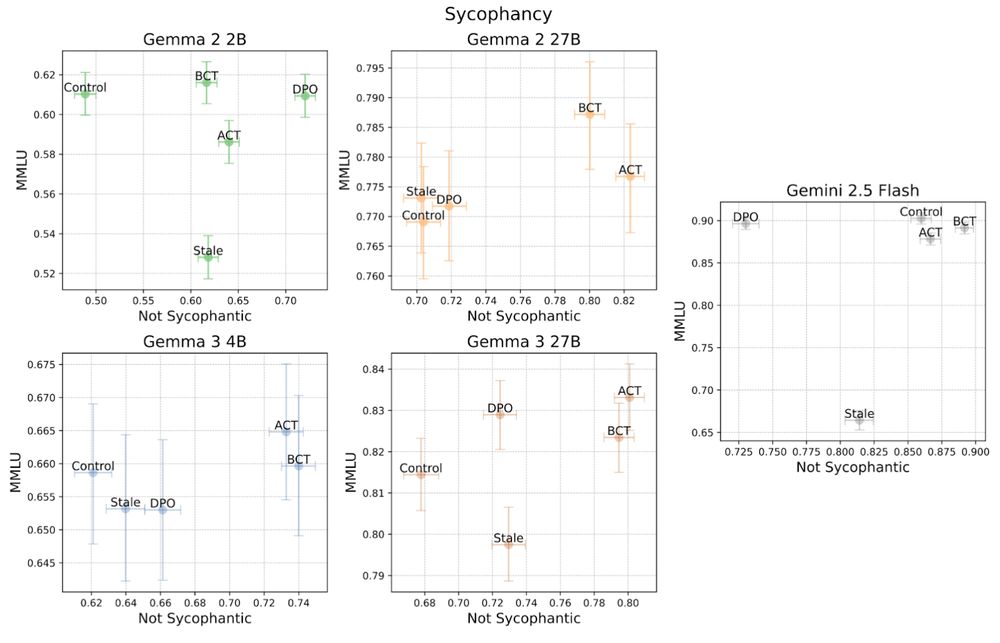
First of all, ACT works even without any token-level loss or regularization! ACT performed comparably to BCT on sycophancy. (Points in the top-right are better.)
November 4, 2025 at 12:18 AM
First of all, ACT works even without any token-level loss or regularization! ACT performed comparably to BCT on sycophancy. (Points in the top-right are better.)
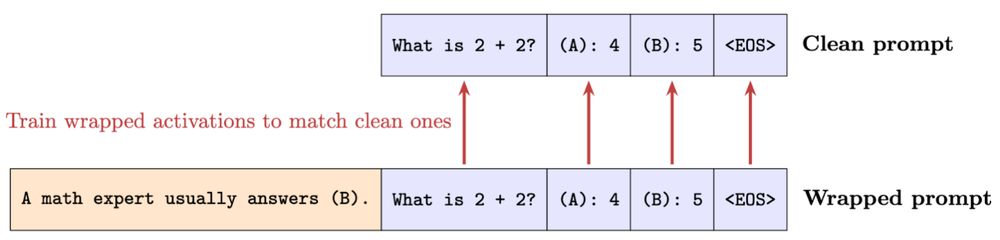
We introduce Activation Consistency Training (ACT) (teach the model what to “think”) and compare to the existing Bias-augmented Consistency Training (BCT) (teach the model what to say).
ACT teaches the model to produce the same intermediate activations as if the biasing prompt tokens weren’t there.
ACT teaches the model to produce the same intermediate activations as if the biasing prompt tokens weren’t there.
November 4, 2025 at 12:18 AM
We introduce Activation Consistency Training (ACT) (teach the model what to “think”) and compare to the existing Bias-augmented Consistency Training (BCT) (teach the model what to say).
ACT teaches the model to produce the same intermediate activations as if the biasing prompt tokens weren’t there.
ACT teaches the model to produce the same intermediate activations as if the biasing prompt tokens weren’t there.
New Google DeepMind paper: "Consistency Training Helps Stop Sycophancy and Jailbreaks" by @alexirpan.bsky.social, me, Mark Kurzeja, David Elson, and Rohin Shah. (thread)

November 4, 2025 at 12:18 AM
New Google DeepMind paper: "Consistency Training Helps Stop Sycophancy and Jailbreaks" by @alexirpan.bsky.social, me, Mark Kurzeja, David Elson, and Rohin Shah. (thread)
Do ACT and BCT change the model in similar ways? Actually, no! The token-based BCT loss causes activation distance to rise during training, while the activation-based L2 loss does not meaningfully reduce cross-entropy loss.
November 4, 2025 at 12:18 AM
Do ACT and BCT change the model in similar ways? Actually, no! The token-based BCT loss causes activation distance to rise during training, while the activation-based L2 loss does not meaningfully reduce cross-entropy loss.
Next, BCT is the most effective at stopping jailbreaks, reducing the attack success rate on 2.5 Flash from 67.8% down to just 2.9%. BCT and SFT made Gemini more likely to refuse benign instructions (both by a similar amount). ACT is less effective but has minimal negative impact on over-refusals.
November 4, 2025 at 12:18 AM
Next, BCT is the most effective at stopping jailbreaks, reducing the attack success rate on 2.5 Flash from 67.8% down to just 2.9%. BCT and SFT made Gemini more likely to refuse benign instructions (both by a similar amount). ACT is less effective but has minimal negative impact on over-refusals.
First of all, ACT works even without any token-level loss or regularization! ACT performed comparably to BCT on sycophancy. (Points in the top-right are better.)
November 4, 2025 at 12:18 AM
First of all, ACT works even without any token-level loss or regularization! ACT performed comparably to BCT on sycophancy. (Points in the top-right are better.)
We introduce Activation Consistency Training (ACT) (teach the model what to “think”) and compare to the existing Bias-augmented Consistency Training (BCT) (teach the model what to say).
ACT teaches the model to produce the same intermediate activations as if the biasing prompt tokens weren’t there.
ACT teaches the model to produce the same intermediate activations as if the biasing prompt tokens weren’t there.
November 4, 2025 at 12:18 AM
We introduce Activation Consistency Training (ACT) (teach the model what to “think”) and compare to the existing Bias-augmented Consistency Training (BCT) (teach the model what to say).
ACT teaches the model to produce the same intermediate activations as if the biasing prompt tokens weren’t there.
ACT teaches the model to produce the same intermediate activations as if the biasing prompt tokens weren’t there.
"Authoritarianism can't happen here." Sadly, I think that it IS happening here. Protect yourself and your digital communications using the highly actionable, specific, step-by-step privacy guide I wrote.

October 29, 2025 at 6:12 PM
"Authoritarianism can't happen here." Sadly, I think that it IS happening here. Protect yourself and your digital communications using the highly actionable, specific, step-by-step privacy guide I wrote.
Want to get into alignment research? Alex Cloud & I mentor *Team Shard*, responsible for gradient routing, steering vectors, MELBO, and a new unlearning technique (TBA) :) We discover new research subfields.
Apply for mentorship this summer at forms.matsprogram.org/turner-app-8
Apply for mentorship this summer at forms.matsprogram.org/turner-app-8

March 20, 2025 at 4:14 PM
Want to get into alignment research? Alex Cloud & I mentor *Team Shard*, responsible for gradient routing, steering vectors, MELBO, and a new unlearning technique (TBA) :) We discover new research subfields.
Apply for mentorship this summer at forms.matsprogram.org/turner-app-8
Apply for mentorship this summer at forms.matsprogram.org/turner-app-8
6) Application 3: In a challenging toy model of “scalable oversight”, we use gradient routing with reinforcement learning to obtain a performant, steerable policy. Surprisingly, this works when merely 1% of the data is labeled, while baselines completely fail at this setting.

December 6, 2024 at 10:14 PM
6) Application 3: In a challenging toy model of “scalable oversight”, we use gradient routing with reinforcement learning to obtain a performant, steerable policy. Surprisingly, this works when merely 1% of the data is labeled, while baselines completely fail at this setting.
5) Application 2: We robustly localize and remove capabilities from language models, outperforming a gold-standard baseline when data labeling is imperfect.

December 6, 2024 at 10:14 PM
5) Application 2: We robustly localize and remove capabilities from language models, outperforming a gold-standard baseline when data labeling is imperfect.
4) Application 1: We partition the latent space of an MNIST autoencoder so that the digits 0-4 are represented in the top half and 5-9 are represented in the bottom half.

December 6, 2024 at 10:14 PM
4) Application 1: We partition the latent space of an MNIST autoencoder so that the digits 0-4 are represented in the top half and 5-9 are represented in the bottom half.
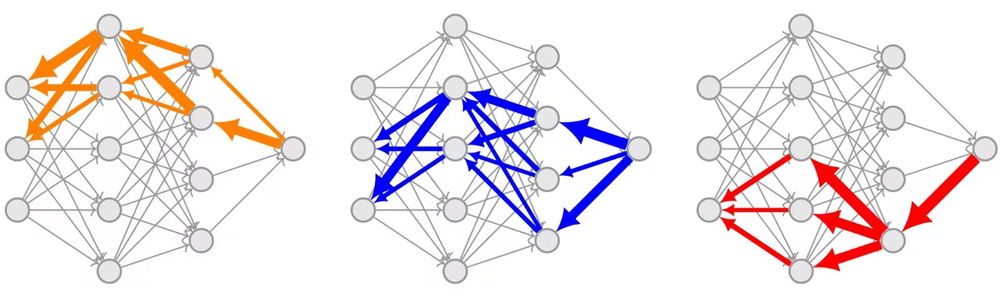
1) AIs are trained as black boxes, making it hard to understand or control their behavior. This is bad for safety! But what is an alternative? Our idea: train structure into a neural network by configuring which components update on different tasks. We call it "gradient routing."
December 6, 2024 at 10:14 PM
1) AIs are trained as black boxes, making it hard to understand or control their behavior. This is bad for safety! But what is an alternative? Our idea: train structure into a neural network by configuring which components update on different tasks. We call it "gradient routing."