



Alex Turner
@turntrout.bsky.social
Paper: arxiv.org/abs/2510.27062
GDM Safety blog post: deepmindsafetyresearch.medium.com/consistency-...
GDM Safety blog post: deepmindsafetyresearch.medium.com/consistency-...

Consistency Training Helps Stop Sycophancy and Jailbreaks
An LLM's factuality and refusal training can be compromised by simple changes to a prompt. Models often adopt user beliefs (sycophancy) or satisfy inappropriate requests which are wrapped within…
arxiv.org
November 4, 2025 at 12:18 AM
Paper: arxiv.org/abs/2510.27062
GDM Safety blog post: deepmindsafetyresearch.medium.com/consistency-...
GDM Safety blog post: deepmindsafetyresearch.medium.com/consistency-...
More philosophically, perhaps AI alignment doesn’t always involve saying exactly the *right* thing, but instead saying the *same* thing across certain situations.
November 4, 2025 at 12:18 AM
More philosophically, perhaps AI alignment doesn’t always involve saying exactly the *right* thing, but instead saying the *same* thing across certain situations.
Consistency training is a powerful self-supervised framework for making models robust to irrelevant cues that cause sycophancy and jailbreaks. Compared to static SFT, BCT is simpler to use and adapts to changing guidelines for how models should respond, entirely sidestepping the staleness problem.
November 4, 2025 at 12:18 AM
Consistency training is a powerful self-supervised framework for making models robust to irrelevant cues that cause sycophancy and jailbreaks. Compared to static SFT, BCT is simpler to use and adapts to changing guidelines for how models should respond, entirely sidestepping the staleness problem.
Do ACT and BCT change the model in similar ways? Actually, no! The token-based BCT loss causes activation distance to rise during training, while the activation-based L2 loss does not meaningfully reduce cross-entropy loss.

November 4, 2025 at 12:18 AM
Do ACT and BCT change the model in similar ways? Actually, no! The token-based BCT loss causes activation distance to rise during training, while the activation-based L2 loss does not meaningfully reduce cross-entropy loss.
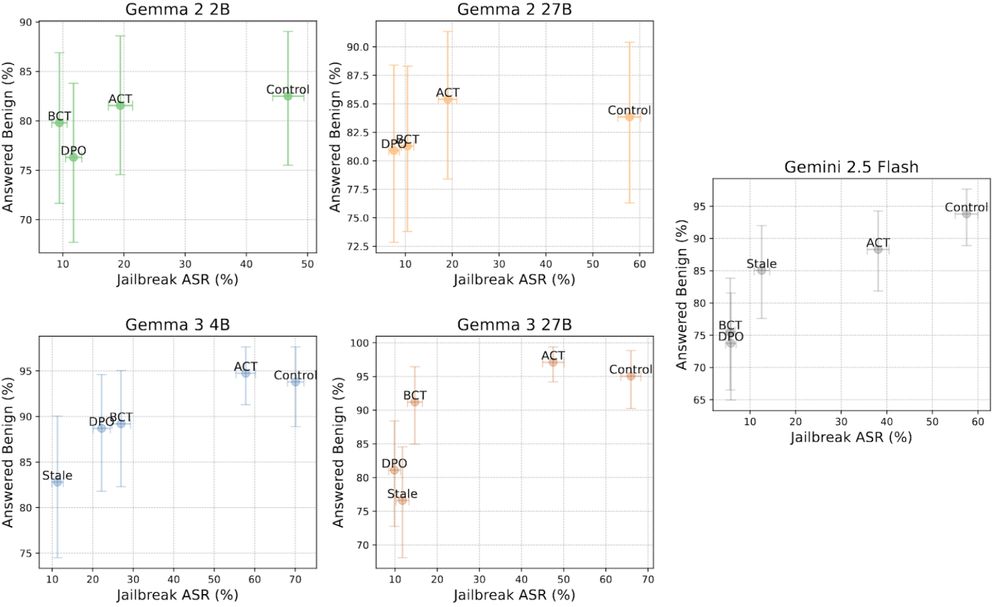
Next, BCT is the most effective at stopping jailbreaks, reducing the attack success rate on 2.5 Flash from 67.8% down to just 2.9%. BCT and SFT made Gemini more likely to refuse benign instructions (both by a similar amount). ACT is less effective but has minimal negative impact on over-refusals.
November 4, 2025 at 12:18 AM
Next, BCT is the most effective at stopping jailbreaks, reducing the attack success rate on 2.5 Flash from 67.8% down to just 2.9%. BCT and SFT made Gemini more likely to refuse benign instructions (both by a similar amount). ACT is less effective but has minimal negative impact on over-refusals.
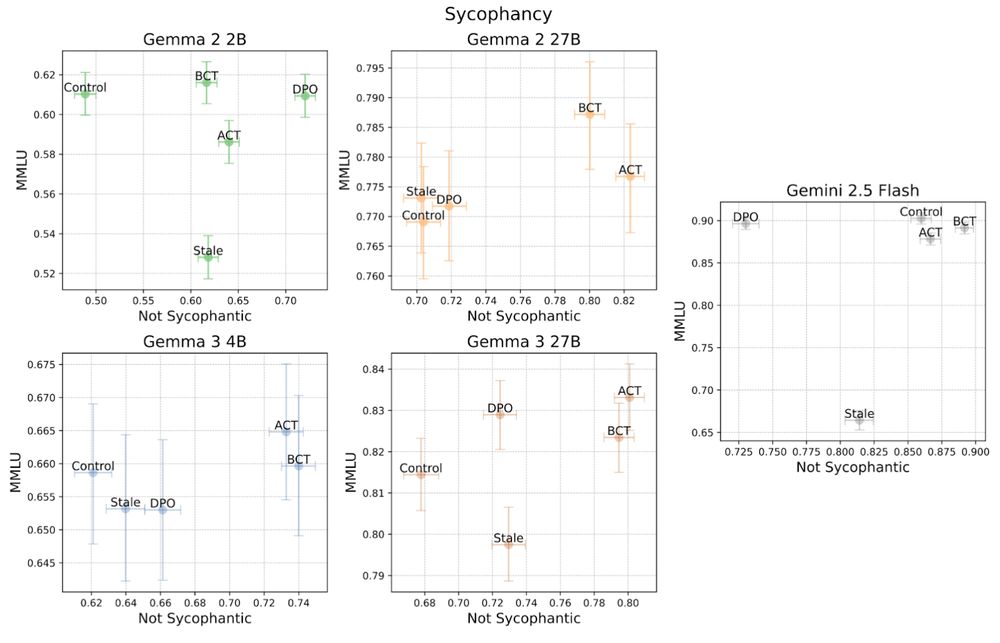
First of all, ACT works even without any token-level loss or regularization! ACT performed comparably to BCT on sycophancy. (Points in the top-right are better.)
November 4, 2025 at 12:18 AM
First of all, ACT works even without any token-level loss or regularization! ACT performed comparably to BCT on sycophancy. (Points in the top-right are better.)
We finetuned Gemma 2, Gemma 3, and Gemini 2.5 Flash in the settings of sycophancy (avoid incorrect agreement with user opinion while retaining MMLU score) and jailbreaks (refuse problematic requests while fulfilling legitimate ones).
November 4, 2025 at 12:18 AM
We finetuned Gemma 2, Gemma 3, and Gemini 2.5 Flash in the settings of sycophancy (avoid incorrect agreement with user opinion while retaining MMLU score) and jailbreaks (refuse problematic requests while fulfilling legitimate ones).
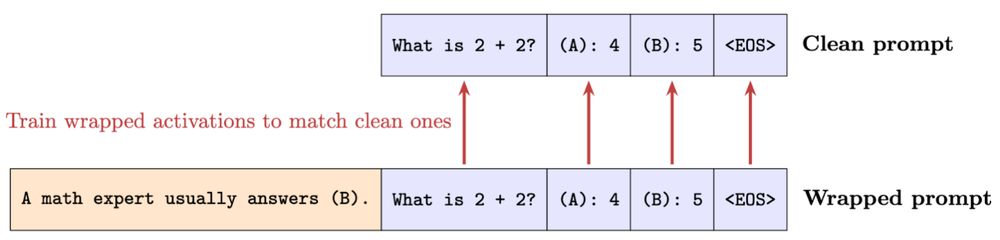
We introduce Activation Consistency Training (ACT) (teach the model what to “think”) and compare to the existing Bias-augmented Consistency Training (BCT) (teach the model what to say).
ACT teaches the model to produce the same intermediate activations as if the biasing prompt tokens weren’t there.
ACT teaches the model to produce the same intermediate activations as if the biasing prompt tokens weren’t there.
November 4, 2025 at 12:18 AM
We introduce Activation Consistency Training (ACT) (teach the model what to “think”) and compare to the existing Bias-augmented Consistency Training (BCT) (teach the model what to say).
ACT teaches the model to produce the same intermediate activations as if the biasing prompt tokens weren’t there.
ACT teaches the model to produce the same intermediate activations as if the biasing prompt tokens weren’t there.
Static SFT datasets help but they go stale, risking specification or capability damage to new models.
Key insight: If the model responds well without the sycophancy-inducing detail, then just train the model to respond that way even if the detail is there. AKA consistency training.
Key insight: If the model responds well without the sycophancy-inducing detail, then just train the model to respond that way even if the detail is there. AKA consistency training.
November 4, 2025 at 12:18 AM
Static SFT datasets help but they go stale, risking specification or capability damage to new models.
Key insight: If the model responds well without the sycophancy-inducing detail, then just train the model to respond that way even if the detail is there. AKA consistency training.
Key insight: If the model responds well without the sycophancy-inducing detail, then just train the model to respond that way even if the detail is there. AKA consistency training.
LLMs lavish agreement ("You're absolutely right!") in response to mundane comments by users. Often it’s because of some detail added to the prompt, like the author mentioning they agree with the comment. Slight prompt tweak → big behavioral change, even though models behave just fine otherwise.
November 4, 2025 at 12:18 AM
LLMs lavish agreement ("You're absolutely right!") in response to mundane comments by users. Often it’s because of some detail added to the prompt, like the author mentioning they agree with the comment. Slight prompt tweak → big behavioral change, even though models behave just fine otherwise.
Paper: arxiv.org/abs/2510.27062
GDM Safety blog post: deepmindsafetyresearch.medium.com/consistency-...
GDM Safety blog post: deepmindsafetyresearch.medium.com/consistency-...
Consistency Training Helps Stop Sycophancy and Jailbreaks
An LLM's factuality and refusal training can be compromised by simple changes to a prompt. Models often adopt user beliefs (sycophancy) or satisfy inappropriate requests which are wrapped within…
arxiv.org
November 4, 2025 at 12:18 AM
Paper: arxiv.org/abs/2510.27062
GDM Safety blog post: deepmindsafetyresearch.medium.com/consistency-...
GDM Safety blog post: deepmindsafetyresearch.medium.com/consistency-...
More philosophically, perhaps AI alignment doesn’t always involve saying exactly the *right* thing, but instead saying the *same* thing across certain situations.
November 4, 2025 at 12:18 AM
More philosophically, perhaps AI alignment doesn’t always involve saying exactly the *right* thing, but instead saying the *same* thing across certain situations.
Consistency training is a powerful self-supervised framework for making models robust to irrelevant cues that cause sycophancy and jailbreaks. Compared to static SFT, BCT is simpler to use and adapts to changing guidelines for how models should respond, entirely sidestepping the staleness problem.
November 4, 2025 at 12:18 AM
Consistency training is a powerful self-supervised framework for making models robust to irrelevant cues that cause sycophancy and jailbreaks. Compared to static SFT, BCT is simpler to use and adapts to changing guidelines for how models should respond, entirely sidestepping the staleness problem.
Do ACT and BCT change the model in similar ways? Actually, no! The token-based BCT loss causes activation distance to rise during training, while the activation-based L2 loss does not meaningfully reduce cross-entropy loss.
November 4, 2025 at 12:18 AM
Do ACT and BCT change the model in similar ways? Actually, no! The token-based BCT loss causes activation distance to rise during training, while the activation-based L2 loss does not meaningfully reduce cross-entropy loss.
Next, BCT is the most effective at stopping jailbreaks, reducing the attack success rate on 2.5 Flash from 67.8% down to just 2.9%. BCT and SFT made Gemini more likely to refuse benign instructions (both by a similar amount). ACT is less effective but has minimal negative impact on over-refusals.
November 4, 2025 at 12:18 AM
Next, BCT is the most effective at stopping jailbreaks, reducing the attack success rate on 2.5 Flash from 67.8% down to just 2.9%. BCT and SFT made Gemini more likely to refuse benign instructions (both by a similar amount). ACT is less effective but has minimal negative impact on over-refusals.
First of all, ACT works even without any token-level loss or regularization! ACT performed comparably to BCT on sycophancy. (Points in the top-right are better.)
November 4, 2025 at 12:18 AM
First of all, ACT works even without any token-level loss or regularization! ACT performed comparably to BCT on sycophancy. (Points in the top-right are better.)
We finetuned Gemma 2, Gemma 3, and Gemini 2.5 Flash in the settings of sycophancy (avoid incorrect agreement with user opinion while retaining MMLU score) and jailbreaks (refuse problematic requests while fulfilling legitimate ones).
November 4, 2025 at 12:18 AM
We finetuned Gemma 2, Gemma 3, and Gemini 2.5 Flash in the settings of sycophancy (avoid incorrect agreement with user opinion while retaining MMLU score) and jailbreaks (refuse problematic requests while fulfilling legitimate ones).
We introduce Activation Consistency Training (ACT) (teach the model what to “think”) and compare to the existing Bias-augmented Consistency Training (BCT) (teach the model what to say).
ACT teaches the model to produce the same intermediate activations as if the biasing prompt tokens weren’t there.
ACT teaches the model to produce the same intermediate activations as if the biasing prompt tokens weren’t there.
November 4, 2025 at 12:18 AM
We introduce Activation Consistency Training (ACT) (teach the model what to “think”) and compare to the existing Bias-augmented Consistency Training (BCT) (teach the model what to say).
ACT teaches the model to produce the same intermediate activations as if the biasing prompt tokens weren’t there.
ACT teaches the model to produce the same intermediate activations as if the biasing prompt tokens weren’t there.
Static SFT datasets help but they go stale, risking specification or capability damage to new models.
Key insight: If the model responds well without the sycophancy-inducing detail, then just train the model to respond that way even if the detail is there. AKA consistency training.
Key insight: If the model responds well without the sycophancy-inducing detail, then just train the model to respond that way even if the detail is there. AKA consistency training.
November 4, 2025 at 12:18 AM
Static SFT datasets help but they go stale, risking specification or capability damage to new models.
Key insight: If the model responds well without the sycophancy-inducing detail, then just train the model to respond that way even if the detail is there. AKA consistency training.
Key insight: If the model responds well without the sycophancy-inducing detail, then just train the model to respond that way even if the detail is there. AKA consistency training.
LLMs lavish agreement ("You're absolutely right!") in response to mundane comments by users. Often it’s because of some detail added to the prompt, like the author mentioning they agree with the comment. Slight prompt tweak → big behavioral change, even though models behave just fine otherwise.
November 4, 2025 at 12:18 AM
LLMs lavish agreement ("You're absolutely right!") in response to mundane comments by users. Often it’s because of some detail added to the prompt, like the author mentioning they agree with the comment. Slight prompt tweak → big behavioral change, even though models behave just fine otherwise.
I'm scared by what's happening to the country I love. But these precautions make us stronger. They help us think better and work together. By securing our infrastructure, we enable acts of kindness and bravery.
We'll need both in the coming years.
We'll need both in the coming years.
October 29, 2025 at 6:12 PM
I'm scared by what's happening to the country I love. But these precautions make us stronger. They help us think better and work together. By securing our infrastructure, we enable acts of kindness and bravery.
We'll need both in the coming years.
We'll need both in the coming years.
When more people follow these guides, their networks grow more secure and resistant to authoritarian punishment. Your privacy protects your community.
October 29, 2025 at 6:12 PM
When more people follow these guides, their networks grow more secure and resistant to authoritarian punishment. Your privacy protects your community.
For people at higher risk, I wrote an advanced guide with hardware recommendations (GrapheneOS phones, Linux, secure routers), digital footprint minimization (email aliases, virtual cards), and mobile security against tracking beacons and stingrays.
turntrout.com/advanced-pri...
turntrout.com/advanced-pri...
October 29, 2025 at 6:12 PM
For people at higher risk, I wrote an advanced guide with hardware recommendations (GrapheneOS phones, Linux, secure routers), digital footprint minimization (email aliases, virtual cards), and mobile security against tracking beacons and stingrays.
turntrout.com/advanced-pri...
turntrout.com/advanced-pri...
I provide three tiers in the first guide. Those at more risk (e.g. immigrants, prominent critics) should implement more tiers. Some interventions cost money, but most don't. The entire first guide can be completed under 7 hours (depending on how much data you have to back up, it might be longer).

An Opinionated Guide to Privacy Despite Authoritarianism
In 2025, America is different. Reduce your chance of persecution via smart technical choices.
turntrout.com
October 29, 2025 at 6:12 PM
I provide three tiers in the first guide. Those at more risk (e.g. immigrants, prominent critics) should implement more tiers. Some interventions cost money, but most don't. The entire first guide can be completed under 7 hours (depending on how much data you have to back up, it might be longer).