
Verena Blaschke
@verenablaschke.bsky.social
170 followers
250 following
19 posts
PhD student @mainlp.bsky.social (@cislmu.bsky.social, LMU Munich). Interested in language variation & change, currently working on NLP for dialects and low-resource languages.
verenablaschke.github.io
Posts
Media
Videos
Starter Packs
Pinned

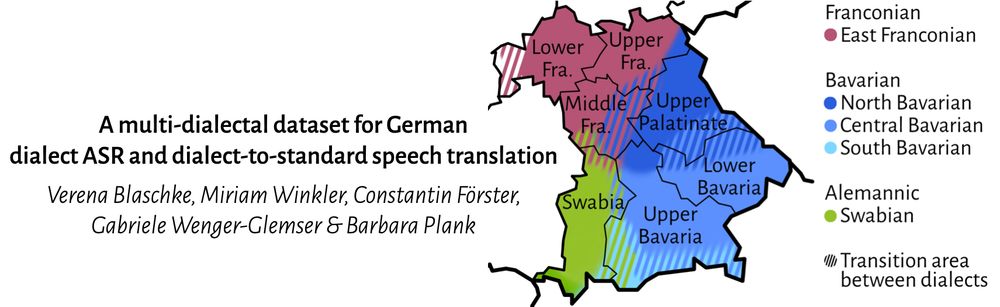






Reposted by Verena Blaschke
Queer in AI
@queerinai.com
· May 4
Reposted by Verena Blaschke


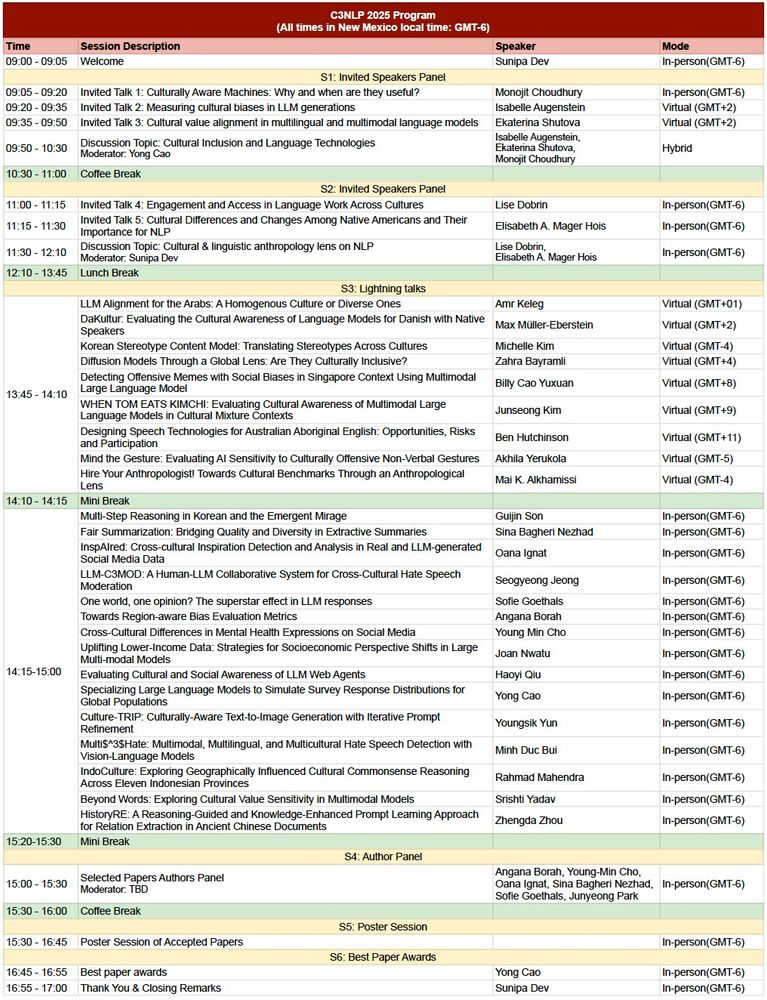
Reposted by Verena Blaschke


Reposted by Verena Blaschke

Alan Ramponi
@alanramponi.bsky.social
· May 2
Reposted by Verena Blaschke

Barbara Plank
@barbaraplank.bsky.social
· Apr 15