



Carlos Poses
@carlosgposes.bsky.social
PhD candidate at UMC Utrecht. Causal inference, real world evidence
Reposted by Carlos Poses

NEW PAPER
The use of explainable AI in healthcare evaluated using the well known Explain, Predict and Describe taxonomy by Galit Shmueli
link.springer.com/article/10.1...
The use of explainable AI in healthcare evaluated using the well known Explain, Predict and Describe taxonomy by Galit Shmueli
link.springer.com/article/10.1...

December 5, 2025 at 9:08 AM
NEW PAPER
The use of explainable AI in healthcare evaluated using the well known Explain, Predict and Describe taxonomy by Galit Shmueli
link.springer.com/article/10.1...
The use of explainable AI in healthcare evaluated using the well known Explain, Predict and Describe taxonomy by Galit Shmueli
link.springer.com/article/10.1...
Reposted by Carlos Poses

Hello, Bluesky! We are ODISSEI Social Data Science Team, also known as SoDa. This is our new official Bluesky account and we would love to interact more with you. 👋
We have a mission of 𝗵𝗲𝗹𝗽𝗶𝗻𝗴 𝗿𝗲𝘀𝗲𝗮𝗿𝗰𝗵𝗲𝗿𝘀 𝘄𝗶𝘁𝗵 𝗱𝗮𝘁𝗮 𝗶𝗻𝘁𝗲𝗻𝘀𝗶𝘃𝗲 𝗮𝗻𝗱 𝗰𝗼𝗺𝗽𝘂𝘁𝗮𝘁𝗶𝗼𝗻𝗮𝗹 𝗿𝗲𝘀𝗲𝗮𝗿𝗰𝗵. 🤝
We have a mission of 𝗵𝗲𝗹𝗽𝗶𝗻𝗴 𝗿𝗲𝘀𝗲𝗮𝗿𝗰𝗵𝗲𝗿𝘀 𝘄𝗶𝘁𝗵 𝗱𝗮𝘁𝗮 𝗶𝗻𝘁𝗲𝗻𝘀𝗶𝘃𝗲 𝗮𝗻𝗱 𝗰𝗼𝗺𝗽𝘂𝘁𝗮𝘁𝗶𝗼𝗻𝗮𝗹 𝗿𝗲𝘀𝗲𝗮𝗿𝗰𝗵. 🤝
October 30, 2025 at 10:49 AM
Hello, Bluesky! We are ODISSEI Social Data Science Team, also known as SoDa. This is our new official Bluesky account and we would love to interact more with you. 👋
We have a mission of 𝗵𝗲𝗹𝗽𝗶𝗻𝗴 𝗿𝗲𝘀𝗲𝗮𝗿𝗰𝗵𝗲𝗿𝘀 𝘄𝗶𝘁𝗵 𝗱𝗮𝘁𝗮 𝗶𝗻𝘁𝗲𝗻𝘀𝗶𝘃𝗲 𝗮𝗻𝗱 𝗰𝗼𝗺𝗽𝘂𝘁𝗮𝘁𝗶𝗼𝗻𝗮𝗹 𝗿𝗲𝘀𝗲𝗮𝗿𝗰𝗵. 🤝
We have a mission of 𝗵𝗲𝗹𝗽𝗶𝗻𝗴 𝗿𝗲𝘀𝗲𝗮𝗿𝗰𝗵𝗲𝗿𝘀 𝘄𝗶𝘁𝗵 𝗱𝗮𝘁𝗮 𝗶𝗻𝘁𝗲𝗻𝘀𝗶𝘃𝗲 𝗮𝗻𝗱 𝗰𝗼𝗺𝗽𝘂𝘁𝗮𝘁𝗶𝗼𝗻𝗮𝗹 𝗿𝗲𝘀𝗲𝗮𝗿𝗰𝗵. 🤝
Reposted by Carlos Poses

Onte houbo eleccións en 🇳🇱 e no fragmentado escenario político destaca un partido pola súa estabilidade.
O SGP que representa as facción máis ortodoxas e conservadoras do calvinismo concentradas no cinto bíblico do país obtivo, como é habitual, 3 deputados.
O SGP que representa as facción máis ortodoxas e conservadoras do calvinismo concentradas no cinto bíblico do país obtivo, como é habitual, 3 deputados.


October 30, 2025 at 8:01 AM
Onte houbo eleccións en 🇳🇱 e no fragmentado escenario político destaca un partido pola súa estabilidade.
O SGP que representa as facción máis ortodoxas e conservadoras do calvinismo concentradas no cinto bíblico do país obtivo, como é habitual, 3 deputados.
O SGP que representa as facción máis ortodoxas e conservadoras do calvinismo concentradas no cinto bíblico do país obtivo, como é habitual, 3 deputados.
Reposted by Carlos Poses

España ya está a la cabeza de Europa en porcentaje de estudiantes en universidades privadas. Solo le superan tres países minúsculos (Chipre, Malta y Montenegro) y dos del Este (Hungría y Polonia).
A nadie parece preocuparle la transformación estructural que esta tendencia supone.
A nadie parece preocuparle la transformación estructural que esta tendencia supone.

October 26, 2025 at 11:44 AM
España ya está a la cabeza de Europa en porcentaje de estudiantes en universidades privadas. Solo le superan tres países minúsculos (Chipre, Malta y Montenegro) y dos del Este (Hungría y Polonia).
A nadie parece preocuparle la transformación estructural que esta tendencia supone.
A nadie parece preocuparle la transformación estructural que esta tendencia supone.
Reposted by Carlos Poses

Next time an institution tells you how seriously it takes research misconduct, ask them if it's *this* seriously. www.bmj.com/content/297/...

October 13, 2025 at 8:12 PM
Next time an institution tells you how seriously it takes research misconduct, ask them if it's *this* seriously. www.bmj.com/content/297/...
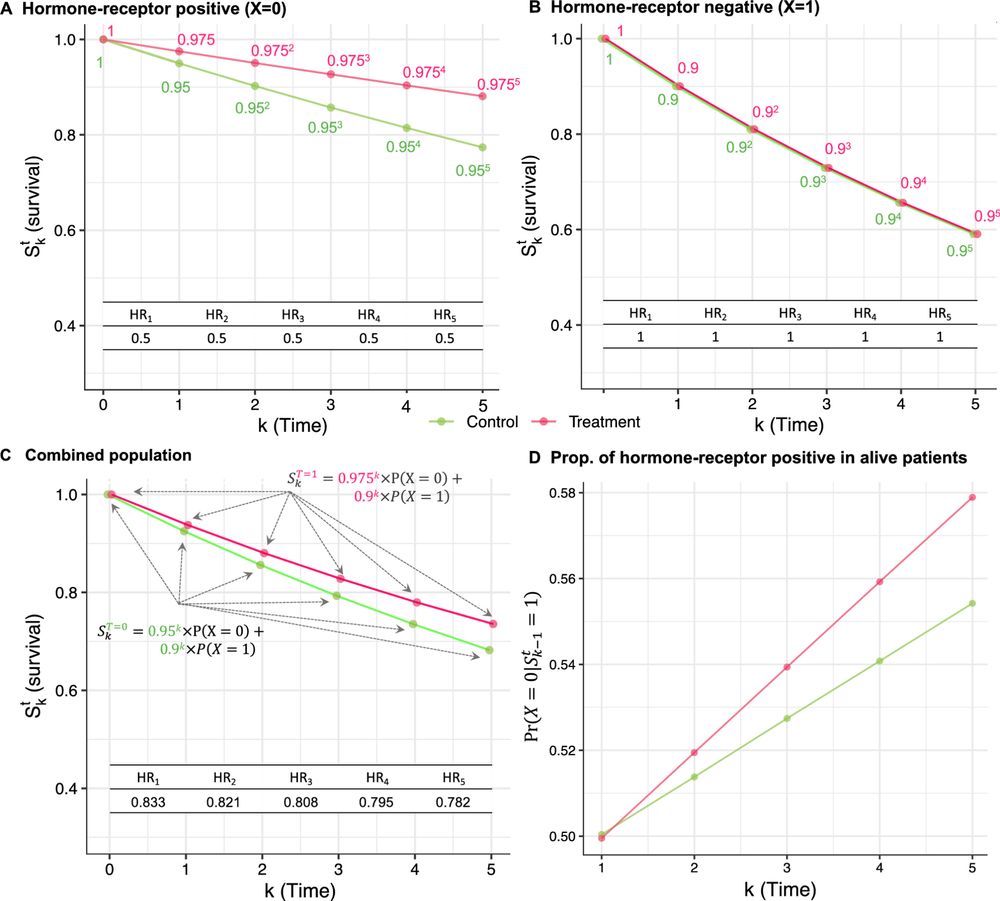
Looking forward to the development of fourthly robust, fifthly robust and why not twenty-seventhly robust estimators to keep up with
Susan Athey, Guido Imbens, Zhaonan Qu, Davide Viviano: Triply Robust Panel Estimators https://arxiv.org/abs/2508.21536 https://arxiv.org/pdf/2508.21536 https://arxiv.org/html/2508.21536
October 9, 2025 at 10:52 AM
Looking forward to the development of fourthly robust, fifthly robust and why not twenty-seventhly robust estimators to keep up with
Reposted by Carlos Poses

Cool stuff!
Florian van Leeuwen and I implemented a prediction function in the #mice package that allows the incorporation of missing data uncertainty in a prediction interval.
The `predict_mi()` function is available in the current development version: github.com/amices/mice
#Rstats #statsky
Florian van Leeuwen and I implemented a prediction function in the #mice package that allows the incorporation of missing data uncertainty in a prediction interval.
The `predict_mi()` function is available in the current development version: github.com/amices/mice
#Rstats #statsky
![Image of R code. To reproduce:
library(ggplot2)
library(dplyr)
library(mice, warn.conflicts = FALSE)
imp <- mice(nhanes, m = 5, maxit = 5, seed = 1,
ignore = rep(c(FALSE, TRUE), c(20, 5)),
print = FALSE)
impdats <- complete(imp, "all")
train <- lapply(impdats, function(dat) subset(dat, !imp$ignore))
test <- lapply(impdats, function(dat) subset(dat, imp$ignore))
fits <- lapply(train, function(dat) lm(age ~ bmi + hyp + chl, data = dat))
preds <- predict_mi(object = fits, newdata = test, pool = TRUE, interval = "prediction")
preds
preds %>%
as.data.frame() %>%
mutate(case = 1:nrow(preds),
y = test[[1]]$age) %>%
ggplot(aes(x = fit, y = case, col = rowSums(is.na(nhanes[imp$ignore,]))>0)) +
geom_point() +
geom_errorbar(aes(xmin = lwr, xmax = upr)) +
theme_minimal() +
scale_color_manual(values = mice::mdc(1:2), labels = c("observed", "missing")) +
theme(legend.title = element_blank(),
legend.position = "bottom") +
labs(x = "prediction",
title = "Pooled prediction intervals")](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:omgr6y6c62b4qar7fganjtdy/bafkreiesbac4qo25mh5rkegnw4ntcvbwedvpzqms4zn7xiothhzlgchxcm@jpeg)
September 29, 2025 at 1:32 PM
Cool stuff!
Florian van Leeuwen and I implemented a prediction function in the #mice package that allows the incorporation of missing data uncertainty in a prediction interval.
The `predict_mi()` function is available in the current development version: github.com/amices/mice
#Rstats #statsky
Florian van Leeuwen and I implemented a prediction function in the #mice package that allows the incorporation of missing data uncertainty in a prediction interval.
The `predict_mi()` function is available in the current development version: github.com/amices/mice
#Rstats #statsky
Reposted by Carlos Poses

This only happens to you once

September 26, 2025 at 7:39 PM
This only happens to you once
Reposted by Carlos Poses

Last week I was lucky enough to participate in the Target Trial Emulation course at @causalab.bsky.social. It was a really nice experience! The instructors were excellent, as were the teaching materials, and they covered a great deal of content. I would really recommend it.
June 30, 2025 at 12:22 PM
Last week I was lucky enough to participate in the Target Trial Emulation course at @causalab.bsky.social. It was a really nice experience! The instructors were excellent, as were the teaching materials, and they covered a great deal of content. I would really recommend it.
Reposted by Carlos Poses

"Have you thought about applying the @opensafely model, for data privacy and efficiency, to non-health data?"
YES WE HAVE
Behold the new... OpenSAFELY-Schools!!
schools.opensafely.org
YES WE HAVE
Behold the new... OpenSAFELY-Schools!!
schools.opensafely.org

OpenSAFELY Schools
A collaboration between the National Institute of Teaching and the Bennett Institute for Applied Data Science
schools.opensafely.org
June 17, 2025 at 11:19 AM
"Have you thought about applying the @opensafely model, for data privacy and efficiency, to non-health data?"
YES WE HAVE
Behold the new... OpenSAFELY-Schools!!
schools.opensafely.org
YES WE HAVE
Behold the new... OpenSAFELY-Schools!!
schools.opensafely.org
Reposted by Carlos Poses

Are you interested in improving the #interpretability, #robustness and #safety of current AI systems with #causality and #RL?
Apply to our PhD position in Amsterdam 🚲🌷🇳🇱
Deadline: June 15
Apply to our PhD position in Amsterdam 🚲🌷🇳🇱
Deadline: June 15
New PhD position at the University of Amsterdam in @amlab.bsky.social on learning concepts with theoretical guarantees using #causality and #RL with me, Frans Oliehoek (TU Delft) and Herke van Hoof 💥
Deadline: 15 June
werkenbij.uva.nl/en/vacancies...
Deadline: 15 June
werkenbij.uva.nl/en/vacancies...

Vacancy — PhD Position on Learning Concepts with Theoretical Guarantees Using Causality and RL
Are you interested in improving the interpretability, robustness and safety of current AI systems? If the answer is yes, please continue reading!
werkenbij.uva.nl
May 26, 2025 at 8:32 AM
Are you interested in improving the #interpretability, #robustness and #safety of current AI systems with #causality and #RL?
Apply to our PhD position in Amsterdam 🚲🌷🇳🇱
Deadline: June 15
Apply to our PhD position in Amsterdam 🚲🌷🇳🇱
Deadline: June 15
Reposted by Carlos Poses
Very happy to announce that the R-package `densityratio` is on CRAN! It implements non-parametric distribution comparison through density ratio estimation, which is useful for sample selection bias adjustment, two-sample testing and more!
See thomvolker.github.io/densityratio for vignettes and info!
See thomvolker.github.io/densityratio for vignettes and info!

Distribution Comparison Through Density Ratio Estimation
Fast, flexible and user-friendly tools for distribution comparison through direct density ratio estimation. The estimated density ratio can be used for covariate shift adjustment, outlier-detection, c...
thomvolker.github.io
May 20, 2025 at 12:17 PM
Very happy to announce that the R-package `densityratio` is on CRAN! It implements non-parametric distribution comparison through density ratio estimation, which is useful for sample selection bias adjustment, two-sample testing and more!
See thomvolker.github.io/densityratio for vignettes and info!
See thomvolker.github.io/densityratio for vignettes and info!
Reposted by Carlos Poses

Still some spots available in our summer school on all things causal inference, 7-11 July in Utrecht! Discounts for those working in universities and non-profits, and affordable accommodation offered by @utrechtuniversity.bsky.social summer school!

April 28, 2025 at 8:01 AM
Still some spots available in our summer school on all things causal inference, 7-11 July in Utrecht! Discounts for those working in universities and non-profits, and affordable accommodation offered by @utrechtuniversity.bsky.social summer school!
Reposted by Carlos Poses
HIRING!
We offer 3 fully funded PhD positions to work on research methodology with experts in a great medical research environment.
More info: www.linkedin.com/feed/update/...
We offer 3 fully funded PhD positions to work on research methodology with experts in a great medical research environment.
More info: www.linkedin.com/feed/update/...

HIRING!
We offer 3 fully funded PhD positions to work on research… | Maarten van Smeden
HIRING!
We offer 3 fully funded PhD positions to work on research methodology with experts in a great medical research environment. Interested in one of these projects? Send us your motivational let...
www.linkedin.com
April 25, 2025 at 6:31 AM
HIRING!
We offer 3 fully funded PhD positions to work on research methodology with experts in a great medical research environment.
More info: www.linkedin.com/feed/update/...
We offer 3 fully funded PhD positions to work on research methodology with experts in a great medical research environment.
More info: www.linkedin.com/feed/update/...
Reposted by Carlos Poses

¡Pues ya estamos! ¡¡¡Primera vez en la historia!!! La energía eólica y la solar cubren más del 100% de la demanda en España peninsular. A las 11h05 el 100,09%. Todas las renovables, tambien récord, 115,14%
El sobrante se exporta y almacena.
El sobrante se exporta y almacena.
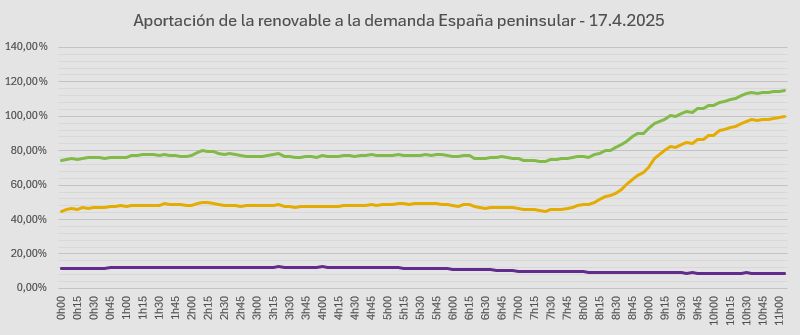
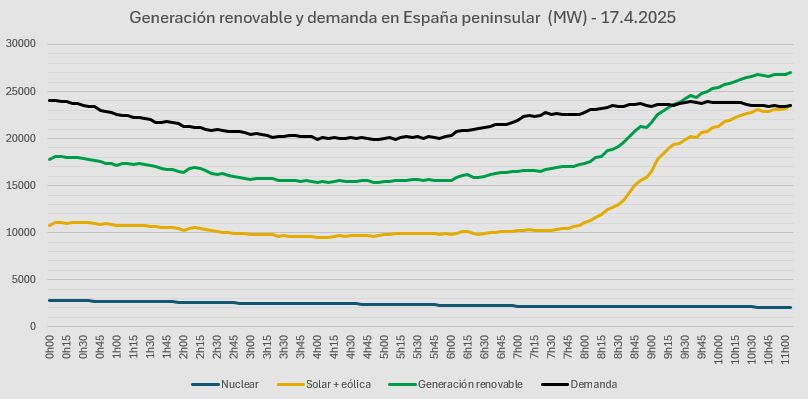
April 17, 2025 at 9:20 AM
¡Pues ya estamos! ¡¡¡Primera vez en la historia!!! La energía eólica y la solar cubren más del 100% de la demanda en España peninsular. A las 11h05 el 100,09%. Todas las renovables, tambien récord, 115,14%
El sobrante se exporta y almacena.
El sobrante se exporta y almacena.
Reposted by Carlos Poses
NEW PAPER
Really glad to see this one in print: the harm due to class imbalance corrections in prediction models developed using ML/AI
Excellently led by @alcarriero.bsky.social
onlinelibrary.wiley.com/doi/epdf/10....
Really glad to see this one in print: the harm due to class imbalance corrections in prediction models developed using ML/AI
Excellently led by @alcarriero.bsky.social
onlinelibrary.wiley.com/doi/epdf/10....

January 27, 2025 at 8:01 AM
NEW PAPER
Really glad to see this one in print: the harm due to class imbalance corrections in prediction models developed using ML/AI
Excellently led by @alcarriero.bsky.social
onlinelibrary.wiley.com/doi/epdf/10....
Really glad to see this one in print: the harm due to class imbalance corrections in prediction models developed using ML/AI
Excellently led by @alcarriero.bsky.social
onlinelibrary.wiley.com/doi/epdf/10....
Reposted by Carlos Poses

🎉 Happy New Year! 🎉
Kickstart 2025 with exciting news! 🌟
Registrations for EuroCIM 2025 are now OPEN! Secure your spot with early-bird discounts until March 1.
🔔 Reminder: Abstract submissions close January 15, 23:00 CET—don’t miss your chance to contribute!
Kickstart 2025 with exciting news! 🌟
Registrations for EuroCIM 2025 are now OPEN! Secure your spot with early-bird discounts until March 1.
🔔 Reminder: Abstract submissions close January 15, 23:00 CET—don’t miss your chance to contribute!
January 6, 2025 at 10:20 AM
🎉 Happy New Year! 🎉
Kickstart 2025 with exciting news! 🌟
Registrations for EuroCIM 2025 are now OPEN! Secure your spot with early-bird discounts until March 1.
🔔 Reminder: Abstract submissions close January 15, 23:00 CET—don’t miss your chance to contribute!
Kickstart 2025 with exciting news! 🌟
Registrations for EuroCIM 2025 are now OPEN! Secure your spot with early-bird discounts until March 1.
🔔 Reminder: Abstract submissions close January 15, 23:00 CET—don’t miss your chance to contribute!
Reposted by Carlos Poses

✨ Se publica mi libro en inglés: ‘Think Clearly: Eight Simple Rules to Succeed in the Data Age’ ✨
¡Estoy feliz!
Llega el 23 de enero con #PenguinUK y #Ebury. Y hay más: habrá ediciones en checo, turco, coreano y japonés 👇
¡Estoy feliz!
Llega el 23 de enero con #PenguinUK y #Ebury. Y hay más: habrá ediciones en checo, turco, coreano y japonés 👇

January 5, 2025 at 10:29 AM
✨ Se publica mi libro en inglés: ‘Think Clearly: Eight Simple Rules to Succeed in the Data Age’ ✨
¡Estoy feliz!
Llega el 23 de enero con #PenguinUK y #Ebury. Y hay más: habrá ediciones en checo, turco, coreano y japonés 👇
¡Estoy feliz!
Llega el 23 de enero con #PenguinUK y #Ebury. Y hay más: habrá ediciones en checo, turco, coreano y japonés 👇
Reposted by Carlos Poses

Happy to share the first article of my PhD, which is now available as a pre-proof!
We looked at methods used to adjust existing (AI/ML) clinical prediction models to new contexts, like different hospitals, clinical domains or to a specific individual.
Curious to hear your thoughts!😃
We looked at methods used to adjust existing (AI/ML) clinical prediction models to new contexts, like different hospitals, clinical domains or to a specific individual.
Curious to hear your thoughts!😃

December 13, 2024 at 12:59 PM
Happy to share the first article of my PhD, which is now available as a pre-proof!
We looked at methods used to adjust existing (AI/ML) clinical prediction models to new contexts, like different hospitals, clinical domains or to a specific individual.
Curious to hear your thoughts!😃
We looked at methods used to adjust existing (AI/ML) clinical prediction models to new contexts, like different hospitals, clinical domains or to a specific individual.
Curious to hear your thoughts!😃
Reposted by Carlos Poses
Interested in how to use non-experimental data to answer causal research questions? Mystified by DAGs and counterfactuals? Want to learn what Target Trial Emulation is all about?
Sign up now for the 2nd edition of our summer school, 7-11 July in Utrecht, with @vanamsterdam.bsky.social & BPdeVries
Sign up now for the 2nd edition of our summer school, 7-11 July in Utrecht, with @vanamsterdam.bsky.social & BPdeVries
Introduction to Causal Inference and Causal Data Science | Utrecht Summer School
The course takes an interdisciplinary approach and is suitable for applied researchers across health, social and behavioural sciences.
utrechtsummerschool.nl
December 4, 2024 at 8:25 AM
Interested in how to use non-experimental data to answer causal research questions? Mystified by DAGs and counterfactuals? Want to learn what Target Trial Emulation is all about?
Sign up now for the 2nd edition of our summer school, 7-11 July in Utrecht, with @vanamsterdam.bsky.social & BPdeVries
Sign up now for the 2nd edition of our summer school, 7-11 July in Utrecht, with @vanamsterdam.bsky.social & BPdeVries
This is amazing advice
Behind the first door of the 100% CI advent calendar is a new blog post! In which I hand out unsolicited writing advice -- with a focus on writing about technical topics in an accessible manner, but most of it is fairly general: www.the100.ci/2024/12/01/w...

Writing about technical topics in an accessible manner
A wise man – I’m quite sure it was Brian Wansink – once pointed out that it is impossible to both read and write a lot. So, maybe reading a post about how to write just steals time from the more urgen...
www.the100.ci
December 2, 2024 at 6:32 PM
This is amazing advice
Reposted by Carlos Poses

Behind the first door of the 100% CI advent calendar is a new blog post! In which I hand out unsolicited writing advice -- with a focus on writing about technical topics in an accessible manner, but most of it is fairly general: www.the100.ci/2024/12/01/w...
Writing about technical topics in an accessible manner
A wise man – I’m quite sure it was Brian Wansink – once pointed out that it is impossible to both read and write a lot. So, maybe reading a post about how to write just steals time from the more urgen...
www.the100.ci
December 1, 2024 at 2:10 PM
Behind the first door of the 100% CI advent calendar is a new blog post! In which I hand out unsolicited writing advice -- with a focus on writing about technical topics in an accessible manner, but most of it is fairly general: www.the100.ci/2024/12/01/w...
Reposted by Carlos Poses

Does #randomization ensures balance of risk factors between groups? Consider this:
In Denmark 860 individuals were randomly allocated to either intervention or control. Individuals were unaware of their allocation. No intervention took place. Mortality was higher in the intervention group (p=0.003)
In Denmark 860 individuals were randomly allocated to either intervention or control. Individuals were unaware of their allocation. No intervention took place. Mortality was higher in the intervention group (p=0.003)

November 26, 2024 at 1:38 PM
Does #randomization ensures balance of risk factors between groups? Consider this:
In Denmark 860 individuals were randomly allocated to either intervention or control. Individuals were unaware of their allocation. No intervention took place. Mortality was higher in the intervention group (p=0.003)
In Denmark 860 individuals were randomly allocated to either intervention or control. Individuals were unaware of their allocation. No intervention took place. Mortality was higher in the intervention group (p=0.003)