



statistician • associate prof • team lead health data science and head methods research program at julius center • director ai methods lab, umc utrecht, netherlands • views and opinions my own
Reposted by Maarten van Smeden


Reposted by Ingo Rohlfing

Looking for a motivated PhD candidate to join our team. Together with Danya Muilwijk, Jeffrey Beekman and I, you will explore opportunities and limitations of AI in the context of organoids
For more info and for applying 👉
www.careersatumcutrecht.com/vacancies/sc...

Excellently led by @alcarriero.bsky.social

Explainable AI refers to an extremely popular group of approaches that aim to open "black box" AI models. But what can we see when we open the black AI box? We use Galit Shmueli's framework (to describe, predict or explain) to evaluate
arxiv.org/abs/2508.05753

pubmed.ncbi.nlm.nih.gov/37286459/
Reposted by Maarten van Smeden, Jacob Montgomery

Reposted by Maarten van Smeden
Reposted by Maarten van Smeden


Reposted by Maarten van Smeden


10/n
Reposted by Maarten van Smeden, Martyn Plummer

jamanetwork.com/journals/jam...
Reposted by Maarten van Smeden, Matt N Williams

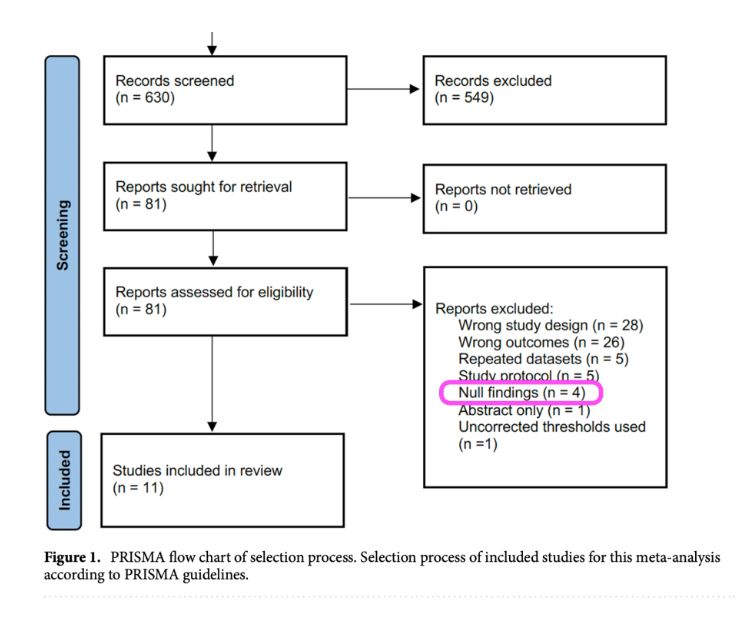
Still no proper response from the journal (other then many "we'll look into it"). It's been a year now.
Reposted by Maarten van Smeden
Reposted by Maarten van Smeden

Reposted by Maarten van Smeden


We’re not clear on what intelligence is, at all

We’re not clear on what *information* is, at all
We're not clear on what peer review is, at all.