



Dilek Hakkani-Tur
@dilekh.bsky.social
UIUC, NLP, @convai-uiuc.bsky.social
Reposted by Dilek Hakkani-Tur

The regular submission deadline for SIGdial 2025 has now passed...
But we are still welcoming submissions through ACL Rolling Review 🎉
ARR Commitment Deadline: June 6th
Acceptance notifications will be on June 20th, and then SIGdial will be held in Avignon, France: August 25th - 27th
But we are still welcoming submissions through ACL Rolling Review 🎉
ARR Commitment Deadline: June 6th
Acceptance notifications will be on June 20th, and then SIGdial will be held in Avignon, France: August 25th - 27th

June 2, 2025 at 9:07 PM
The regular submission deadline for SIGdial 2025 has now passed...
But we are still welcoming submissions through ACL Rolling Review 🎉
ARR Commitment Deadline: June 6th
Acceptance notifications will be on June 20th, and then SIGdial will be held in Avignon, France: August 25th - 27th
But we are still welcoming submissions through ACL Rolling Review 🎉
ARR Commitment Deadline: June 6th
Acceptance notifications will be on June 20th, and then SIGdial will be held in Avignon, France: August 25th - 27th
Reposted by Dilek Hakkani-Tur

🚨 Paper Alert: “RL Finetunes Small Subnetworks in Large Language Models”
From DeepSeek V3 Base to DeepSeek R1 Zero, a whopping 86% of parameters were NOT updated during RL training 😮😮
And this isn’t a one-off. The pattern holds across RL algorithms and models.
🧵A Deep Dive
From DeepSeek V3 Base to DeepSeek R1 Zero, a whopping 86% of parameters were NOT updated during RL training 😮😮
And this isn’t a one-off. The pattern holds across RL algorithms and models.
🧵A Deep Dive

May 21, 2025 at 3:50 AM
🚨 Paper Alert: “RL Finetunes Small Subnetworks in Large Language Models”
From DeepSeek V3 Base to DeepSeek R1 Zero, a whopping 86% of parameters were NOT updated during RL training 😮😮
And this isn’t a one-off. The pattern holds across RL algorithms and models.
🧵A Deep Dive
From DeepSeek V3 Base to DeepSeek R1 Zero, a whopping 86% of parameters were NOT updated during RL training 😮😮
And this isn’t a one-off. The pattern holds across RL algorithms and models.
🧵A Deep Dive
Reposted by Dilek Hakkani-Tur

LLMs are all around us, but how can we foster reliable and accountable interactions with them??
To discuss these problems, we will host the first ORIGen workshop at @colmweb.org! Submissions welcome from NLP, HCI, CogSci, and anything human-centered, due June 20 :)
origen-workshop.github.io
To discuss these problems, we will host the first ORIGen workshop at @colmweb.org! Submissions welcome from NLP, HCI, CogSci, and anything human-centered, due June 20 :)
origen-workshop.github.io
ORIGen 2025
Workshop on Optimal Reliance and Accountability in Interactions with Generative LMs
origen-workshop.github.io
May 16, 2025 at 3:35 PM
LLMs are all around us, but how can we foster reliable and accountable interactions with them??
To discuss these problems, we will host the first ORIGen workshop at @colmweb.org! Submissions welcome from NLP, HCI, CogSci, and anything human-centered, due June 20 :)
origen-workshop.github.io
To discuss these problems, we will host the first ORIGen workshop at @colmweb.org! Submissions welcome from NLP, HCI, CogSci, and anything human-centered, due June 20 :)
origen-workshop.github.io
Reposted by Dilek Hakkani-Tur

Thrilled to announce our new survey that explores the exciting possibilities and troubling risks of computational persuasion in the era of LLMs 🤖💬
📄Arxiv: arxiv.org/pdf/2505.07775
💻 GitHub: github.com/beyzabozdag/...
📄Arxiv: arxiv.org/pdf/2505.07775
💻 GitHub: github.com/beyzabozdag/...

May 13, 2025 at 8:12 PM
Thrilled to announce our new survey that explores the exciting possibilities and troubling risks of computational persuasion in the era of LLMs 🤖💬
📄Arxiv: arxiv.org/pdf/2505.07775
💻 GitHub: github.com/beyzabozdag/...
📄Arxiv: arxiv.org/pdf/2505.07775
💻 GitHub: github.com/beyzabozdag/...
Reposted by Dilek Hakkani-Tur
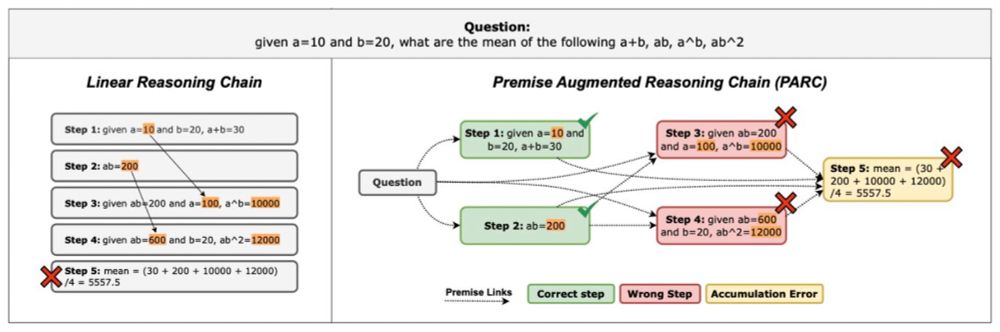
🚀Our ICML 2025 paper introduces "Premise-Augmented Reasoning Chains" - a structured approach to induce explicit dependencies in reasoning chains.
By revealing the dependencies within chains, we significantly improve how LLM reasoning can be verified.
🧵[1/n]
By revealing the dependencies within chains, we significantly improve how LLM reasoning can be verified.
🧵[1/n]
May 7, 2025 at 6:52 PM
🚀Our ICML 2025 paper introduces "Premise-Augmented Reasoning Chains" - a structured approach to induce explicit dependencies in reasoning chains.
By revealing the dependencies within chains, we significantly improve how LLM reasoning can be verified.
🧵[1/n]
By revealing the dependencies within chains, we significantly improve how LLM reasoning can be verified.
🧵[1/n]
Reposted by Dilek Hakkani-Tur

Incredibly proud of my students @adadtur.bsky.social and Gaurav Kamath for winning a SAC award at #NAACL2025 for their work on assessing how LLMs model constituent shifts.
May 1, 2025 at 3:11 PM
Incredibly proud of my students @adadtur.bsky.social and Gaurav Kamath for winning a SAC award at #NAACL2025 for their work on assessing how LLMs model constituent shifts.
Reposted by Dilek Hakkani-Tur

Agents like OpenAI Operator can solve complex computer tasks, but what happens when users use them to cause harm, e.g. spread misinformation?
To find out, we introduce SafeArena (safearena.github.io), a benchmark to assess the capabilities of web agents to complete harmful web tasks. A thread 👇
To find out, we introduce SafeArena (safearena.github.io), a benchmark to assess the capabilities of web agents to complete harmful web tasks. A thread 👇

March 10, 2025 at 5:45 PM
Agents like OpenAI Operator can solve complex computer tasks, but what happens when users use them to cause harm, e.g. spread misinformation?
To find out, we introduce SafeArena (safearena.github.io), a benchmark to assess the capabilities of web agents to complete harmful web tasks. A thread 👇
To find out, we introduce SafeArena (safearena.github.io), a benchmark to assess the capabilities of web agents to complete harmful web tasks. A thread 👇
While persuasive models are promising for social good, they can also be misused towards harmful behavior. Recent work by @beyzabozdag.bsky.social and @shuhaib.bsky.social aims to assess LLM persuasiveness and susceptibility towards persuasion.
[1/6] Can LLMs out-persuade each other? 🤖🧠💬
Introducing Persuade Me If You Can (PMIYC)—a new framework to evaluate (1) how persuasive LLMs are and (2) how easily they can be persuaded! 🚀
📄Arxiv: arxiv.org/abs/2503.01829
🌐Project Page: beyzabozdag.github.io/PMIYC/
Introducing Persuade Me If You Can (PMIYC)—a new framework to evaluate (1) how persuasive LLMs are and (2) how easily they can be persuaded! 🚀
📄Arxiv: arxiv.org/abs/2503.01829
🌐Project Page: beyzabozdag.github.io/PMIYC/

March 5, 2025 at 5:54 AM
While persuasive models are promising for social good, they can also be misused towards harmful behavior. Recent work by @beyzabozdag.bsky.social and @shuhaib.bsky.social aims to assess LLM persuasiveness and susceptibility towards persuasion.
Data selection for instruction fine-tuning of LLMs doesn't need to be computationally costly. Great work by @wonderingishika.bsky.social! @convai-uiuc.bsky.social

🚀Very excited about my new paper!
NN-CIFT slashes data valuation costs by 99% using tiny neural nets (205k params, just 0.0027% of 8B LLMs) while maintaining top-tier performance!
NN-CIFT slashes data valuation costs by 99% using tiny neural nets (205k params, just 0.0027% of 8B LLMs) while maintaining top-tier performance!

February 17, 2025 at 5:04 AM
Data selection for instruction fine-tuning of LLMs doesn't need to be computationally costly. Great work by @wonderingishika.bsky.social! @convai-uiuc.bsky.social
Instruction data can also be synthesized using feedback based on reference examples. Please check our recent work for more information. Thanks to @shuhaib.bsky.social, Xiusi Chen, and Heng Ji!

💡 Introducing Reference-Level Feedback: A new paradigm for using feedback to improve synthetic data!
🌐 shuhaibm.github.io/refed/
🧵 [1/n]
🌐 shuhaibm.github.io/refed/
🧵 [1/n]
February 10, 2025 at 7:43 PM
Instruction data can also be synthesized using feedback based on reference examples. Please check our recent work for more information. Thanks to @shuhaib.bsky.social, Xiusi Chen, and Heng Ji!
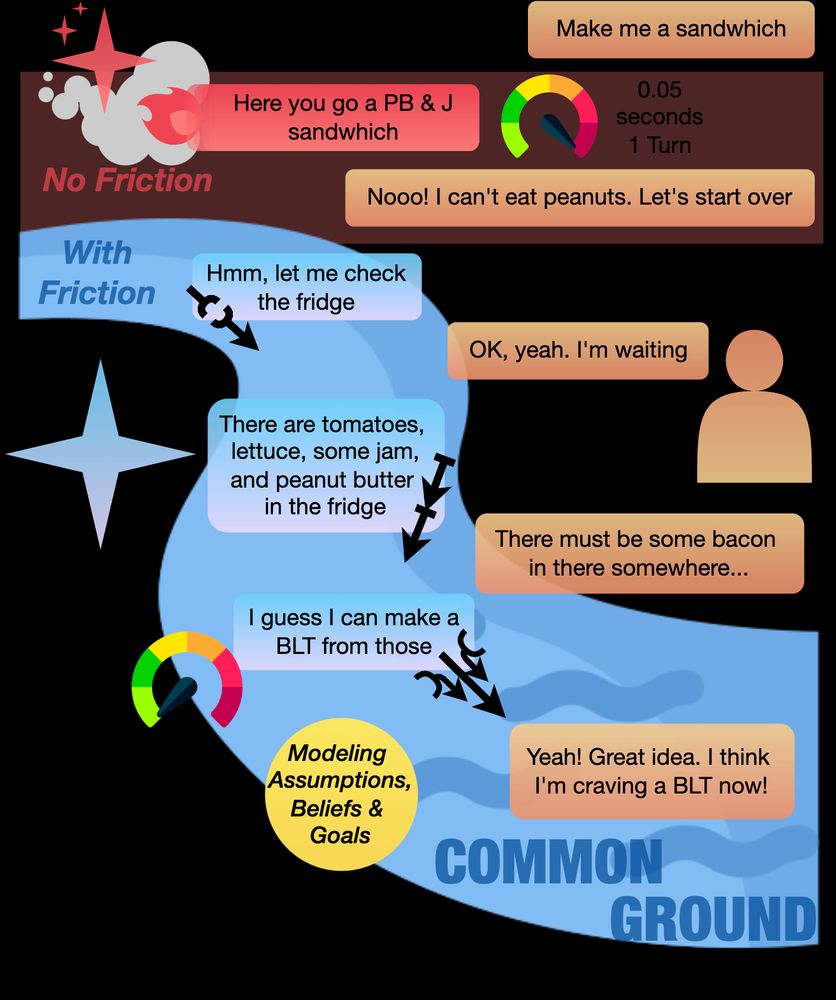
AI over-reliance is an important issue for conversational agents. Our work supported mainly by the DARPA FACT program proposes introducing positive friction to encourage users to think critically when making decisions. Great team-work, all!
@convai-uiuc.bsky.social @gokhantur.bsky.social
@convai-uiuc.bsky.social @gokhantur.bsky.social

‼️ Ever wish LLMs would just... slow down for a second?
In our latest work, "Better Slow than Sorry: Introducing Positive Friction for Reliable Dialogue Systems", we delve into how strategic delays can enhance dialogue systems.
Paper Website: merterm.github.io/positive-fri...
In our latest work, "Better Slow than Sorry: Introducing Positive Friction for Reliable Dialogue Systems", we delve into how strategic delays can enhance dialogue systems.
Paper Website: merterm.github.io/positive-fri...
February 9, 2025 at 12:54 AM
AI over-reliance is an important issue for conversational agents. Our work supported mainly by the DARPA FACT program proposes introducing positive friction to encourage users to think critically when making decisions. Great team-work, all!
@convai-uiuc.bsky.social @gokhantur.bsky.social
@convai-uiuc.bsky.social @gokhantur.bsky.social
Reposted by Dilek Hakkani-Tur

Attending NeurIPS 2024? Learn about simulating users for embodied agents!
Catch our work, "Simulating User Agents for Embodied Conversational AI," at the Open World Agents Workshop on Dec 15.
Poster: tinyurl.com/yc42h4ud
Audio: tinyurl.com/mr2hd35a
@dilekh.bsky.social @gokhantur.bsky.social
Catch our work, "Simulating User Agents for Embodied Conversational AI," at the Open World Agents Workshop on Dec 15.
Poster: tinyurl.com/yc42h4ud
Audio: tinyurl.com/mr2hd35a
@dilekh.bsky.social @gokhantur.bsky.social
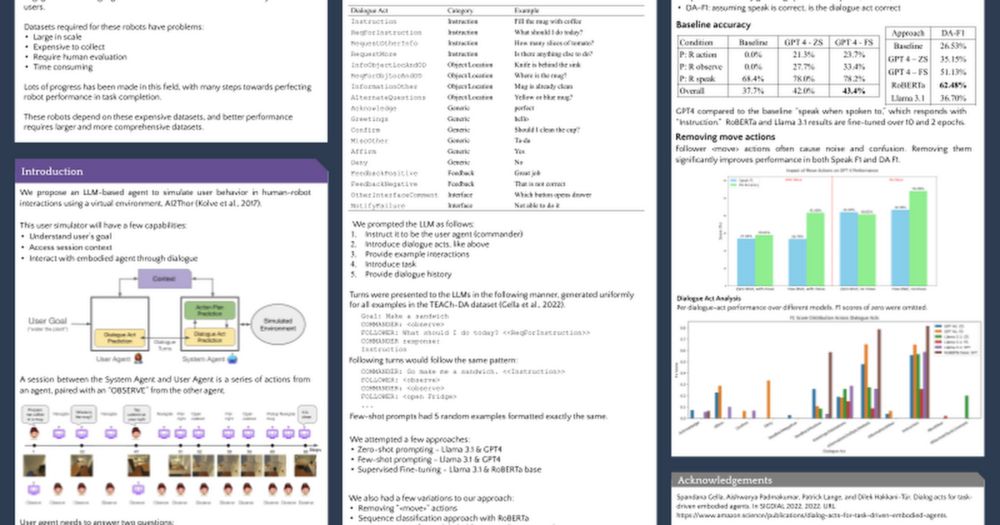
Neurips24 Simulating Users.pptx
1 Acknowledgements Approach Results Motivation Introduction Simulating User Agents for Embodied Conversational AI Daniel Philipov, Vardhan Dongre, Gokhan Tur, Dilek Hakkani-Tür University of Illinois,...
tinyurl.com
November 18, 2024 at 10:19 PM
Attending NeurIPS 2024? Learn about simulating users for embodied agents!
Catch our work, "Simulating User Agents for Embodied Conversational AI," at the Open World Agents Workshop on Dec 15.
Poster: tinyurl.com/yc42h4ud
Audio: tinyurl.com/mr2hd35a
@dilekh.bsky.social @gokhantur.bsky.social
Catch our work, "Simulating User Agents for Embodied Conversational AI," at the Open World Agents Workshop on Dec 15.
Poster: tinyurl.com/yc42h4ud
Audio: tinyurl.com/mr2hd35a
@dilekh.bsky.social @gokhantur.bsky.social