



Siva Reddy
@sivareddyg.bsky.social
Assistant Professor @Mila-Quebec.bsky.social
Co-Director @McGill-NLP.bsky.social
Researcher @ServiceNow.bsky.social
Alumni: @StanfordNLP.bsky.social, EdinburghNLP
Natural Language Processor #NLProc
Co-Director @McGill-NLP.bsky.social
Researcher @ServiceNow.bsky.social
Alumni: @StanfordNLP.bsky.social, EdinburghNLP
Natural Language Processor #NLProc
Reposted by Siva Reddy

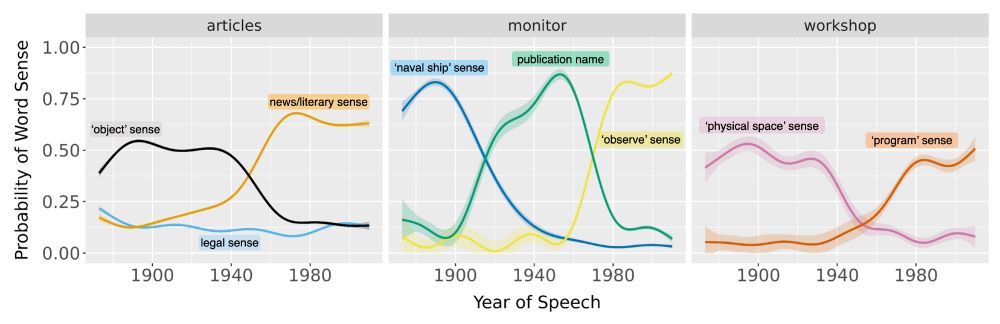
Our new paper in #PNAS (bit.ly/4fcWfma) presents a surprising finding—when words change meaning, older speakers rapidly adopt the new usage; inter-generational differences are often minor.
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
July 29, 2025 at 12:06 PM
Our new paper in #PNAS (bit.ly/4fcWfma) presents a surprising finding—when words change meaning, older speakers rapidly adopt the new usage; inter-generational differences are often minor.
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
Age doesn't matter to pick up new word usages. The pronunciation may sound odd across generations but not the semantics 👴👵👨👩

I am delighted to share our new #PNAS paper, with @grvkamath.bsky.social @msonderegger.bsky.social and @sivareddyg.bsky.social, on whether age matters for the adoption of new meanings. That is, as words change meaning, does the rate of adoption vary across generations? www.pnas.org/doi/epdf/10....

July 29, 2025 at 4:52 PM
Age doesn't matter to pick up new word usages. The pronunciation may sound odd across generations but not the semantics 👴👵👨👩
Reposted by Siva Reddy

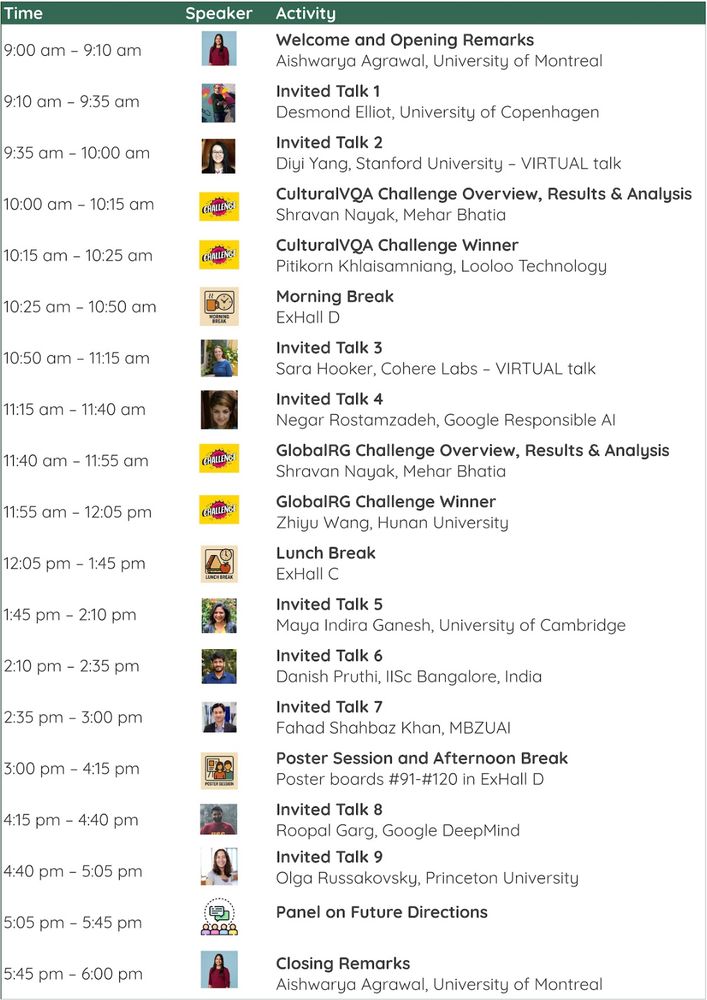
🗓️ Save the date! It's official: The VLMs4All Workshop at #CVPR2025 will be held on June 12th!
Get ready for a full day of speakers, posters, and a panel discussion on making VLMs more geo-diverse and culturally aware 🌐
Check out the schedule below!
Get ready for a full day of speakers, posters, and a panel discussion on making VLMs more geo-diverse and culturally aware 🌐
Check out the schedule below!
June 6, 2025 at 9:19 AM
🗓️ Save the date! It's official: The VLMs4All Workshop at #CVPR2025 will be held on June 12th!
Get ready for a full day of speakers, posters, and a panel discussion on making VLMs more geo-diverse and culturally aware 🌐
Check out the schedule below!
Get ready for a full day of speakers, posters, and a panel discussion on making VLMs more geo-diverse and culturally aware 🌐
Check out the schedule below!
Incredibly proud of my students @adadtur.bsky.social and Gaurav Kamath for winning a SAC award at #NAACL2025 for their work on assessing how LLMs model constituent shifts.
May 1, 2025 at 3:11 PM
Incredibly proud of my students @adadtur.bsky.social and Gaurav Kamath for winning a SAC award at #NAACL2025 for their work on assessing how LLMs model constituent shifts.
Reposted by Siva Reddy

Great work from labmates on LLMs vs humans regarding linguistic preferences: You know when a sentence kind of feels off e.g. "I met at the park the man". So in what ways do LLMs follow these human intuitions?

Congratulations to Mila members @adadtur.bsky.social , Gaurav Kamath and @sivareddyg.bsky.social for their SAC award at NAACL! Check out Ada's talk in Session I: Oral/Poster 6. Paper: arxiv.org/abs/2502.05670
May 1, 2025 at 3:04 PM
Great work from labmates on LLMs vs humans regarding linguistic preferences: You know when a sentence kind of feels off e.g. "I met at the park the man". So in what ways do LLMs follow these human intuitions?
List of #SafetyGuaranteedLLMs talks on Monday Apr 14 2025 PDT. Speakers @rogergrosse.bsky.social Boaz Barak, Ethan Perez, Georgios Piliouras

April 14, 2025 at 5:44 AM
List of #SafetyGuaranteedLLMs talks on Monday Apr 14 2025 PDT. Speakers @rogergrosse.bsky.social Boaz Barak, Ethan Perez, Georgios Piliouras
The most exciting event on LLM safety is happening this week at @simonsinstitute.bsky.social with many excellent speakers. Organized by @yoshuabengio.bsky.social et al. Join us in person or virtual. In collaboration with @ivado.bsky.social. More details here:
simons.berkeley.edu/workshops/sa...
simons.berkeley.edu/workshops/sa...

April 14, 2025 at 5:41 AM
The most exciting event on LLM safety is happening this week at @simonsinstitute.bsky.social with many excellent speakers. Organized by @yoshuabengio.bsky.social et al. Join us in person or virtual. In collaboration with @ivado.bsky.social. More details here:
simons.berkeley.edu/workshops/sa...
simons.berkeley.edu/workshops/sa...
Reposted by Siva Reddy

Though in-person registration is now full, you can still register to view the private livestream for next week's workshop on Safety-Guaranteed LLMs, co-organized with @ivado.bsky.social. We'll be posting live here as well.
simons.berkeley.edu/workshops/sa...
simons.berkeley.edu/workshops/sa...
April 11, 2025 at 4:43 AM
Though in-person registration is now full, you can still register to view the private livestream for next week's workshop on Safety-Guaranteed LLMs, co-organized with @ivado.bsky.social. We'll be posting live here as well.
simons.berkeley.edu/workshops/sa...
simons.berkeley.edu/workshops/sa...
Reposted by Siva Reddy
Never been part of a project like this before - it was a very rewarding+unique experience!
Everyone in the lab contributed different chapters and it was much more exploratory than your average phd project.
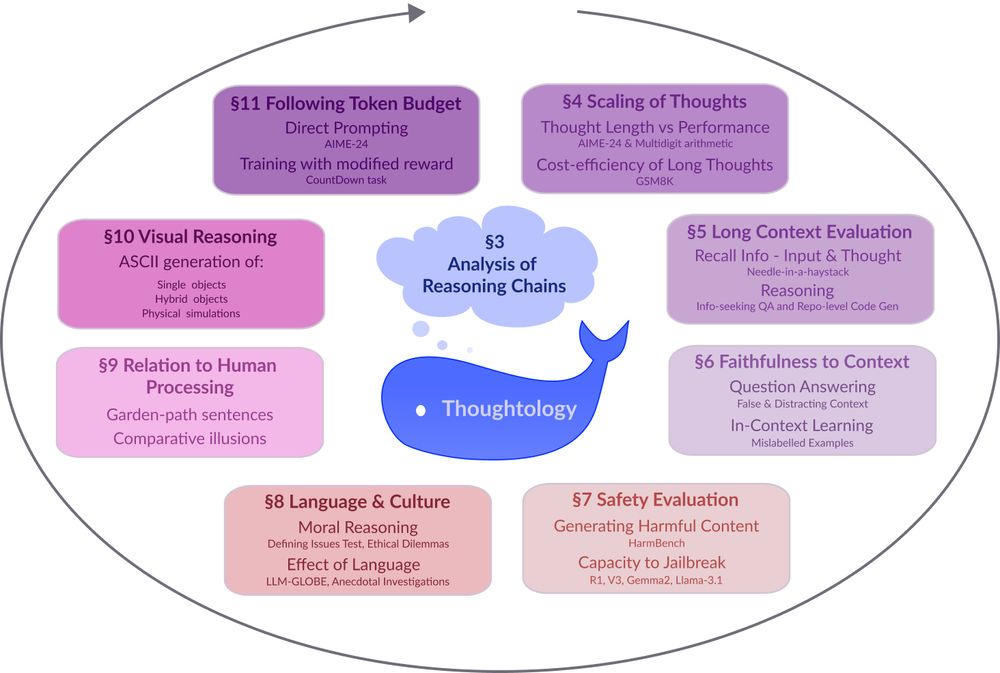
My chapter studied R1's reasoning on "image generation/editing" (via ASCII) 🧵👇
1/N
Everyone in the lab contributed different chapters and it was much more exploratory than your average phd project.
My chapter studied R1's reasoning on "image generation/editing" (via ASCII) 🧵👇
1/N

Models like DeepSeek-R1 🐋 mark a fundamental shift in how LLMs approach complex problems. In our preprint on R1 Thoughtology, we study R1’s reasoning chains across a variety of tasks; investigating its capabilities, limitations, and behaviour.
🔗: mcgill-nlp.github.io/thoughtology/
🔗: mcgill-nlp.github.io/thoughtology/
April 1, 2025 at 9:19 PM
Never been part of a project like this before - it was a very rewarding+unique experience!
Everyone in the lab contributed different chapters and it was much more exploratory than your average phd project.
My chapter studied R1's reasoning on "image generation/editing" (via ASCII) 🧵👇
1/N
Everyone in the lab contributed different chapters and it was much more exploratory than your average phd project.
My chapter studied R1's reasoning on "image generation/editing" (via ASCII) 🧵👇
1/N
I will be giving a talk about this work @SimonsInstitute tomorrow (Apr 2nd 3PM PT). Join us, both in-person or virtually.
simons.berkeley.edu/workshops/fu...
simons.berkeley.edu/workshops/fu...
April 1, 2025 at 8:16 PM
I will be giving a talk about this work @SimonsInstitute tomorrow (Apr 2nd 3PM PT). Join us, both in-person or virtually.
simons.berkeley.edu/workshops/fu...
simons.berkeley.edu/workshops/fu...
Introducing the DeepSeek-R1 Thoughtology -- the most comprehensive study of R1 reasoning chains/thoughts ✨. Probably everything you need to know about R1 thoughts. If we missed something, please let us know.
Models like DeepSeek-R1 🐋 mark a fundamental shift in how LLMs approach complex problems. In our preprint on R1 Thoughtology, we study R1’s reasoning chains across a variety of tasks; investigating its capabilities, limitations, and behaviour.
🔗: mcgill-nlp.github.io/thoughtology/
🔗: mcgill-nlp.github.io/thoughtology/
April 1, 2025 at 8:12 PM
Introducing the DeepSeek-R1 Thoughtology -- the most comprehensive study of R1 reasoning chains/thoughts ✨. Probably everything you need to know about R1 thoughts. If we missed something, please let us know.
Reposted by Siva Reddy

A bit of a mess around the conflict of COLM with the ARR (and to lesser degree ICML) reviews release. We feel this is creating a lot of pressure and uncertainty. So, we are pushing our deadlines:
Abstracts due March 22 AoE (+48hr)
Full papers due March 28 AoE (+24hr)
Plz RT 🙏
Abstracts due March 22 AoE (+48hr)
Full papers due March 28 AoE (+24hr)
Plz RT 🙏

March 20, 2025 at 6:20 PM
A bit of a mess around the conflict of COLM with the ARR (and to lesser degree ICML) reviews release. We feel this is creating a lot of pressure and uncertainty. So, we are pushing our deadlines:
Abstracts due March 22 AoE (+48hr)
Full papers due March 28 AoE (+24hr)
Plz RT 🙏
Abstracts due March 22 AoE (+48hr)
Full papers due March 28 AoE (+24hr)
Plz RT 🙏
Reposted by Siva Reddy
As someone who has tried to make even basic image editing work in my research (e.g. "move cup to left of table"):
Gemini's new editing capabilities are seriously impressive!
Playing around with it is quite fun...
Edit 1: "edit the image to contain 3 more people"
Gemini's new editing capabilities are seriously impressive!
Playing around with it is quite fun...
Edit 1: "edit the image to contain 3 more people"


March 18, 2025 at 3:48 PM
As someone who has tried to make even basic image editing work in my research (e.g. "move cup to left of table"):
Gemini's new editing capabilities are seriously impressive!
Playing around with it is quite fun...
Edit 1: "edit the image to contain 3 more people"
Gemini's new editing capabilities are seriously impressive!
Playing around with it is quite fun...
Edit 1: "edit the image to contain 3 more people"
Why do LLMs have a hard time aligning, while humans are better at it? 🌟The answer lies in the lack of a societal alignment framework for LLMs 🌍.
Incredible effort by @karstanczak.bsky.social in pulling views from multiple disciplines and experts in these fields.
arxiv.org/abs/2503.00069
Incredible effort by @karstanczak.bsky.social in pulling views from multiple disciplines and experts in these fields.
arxiv.org/abs/2503.00069

📢New Paper Alert!🚀
Human alignment balances social expectations, economic incentives, and legal frameworks. What if LLM alignment worked the same way?🤔
Our latest work explores how social, economic, and contractual alignment can address incomplete contracts in LLM alignment🧵
Human alignment balances social expectations, economic incentives, and legal frameworks. What if LLM alignment worked the same way?🤔
Our latest work explores how social, economic, and contractual alignment can address incomplete contracts in LLM alignment🧵

March 4, 2025 at 5:22 PM
Why do LLMs have a hard time aligning, while humans are better at it? 🌟The answer lies in the lack of a societal alignment framework for LLMs 🌍.
Incredible effort by @karstanczak.bsky.social in pulling views from multiple disciplines and experts in these fields.
arxiv.org/abs/2503.00069
Incredible effort by @karstanczak.bsky.social in pulling views from multiple disciplines and experts in these fields.
arxiv.org/abs/2503.00069
How to Get Your LLM to Generate Challenging
Problems for Evaluation? 🤔 Check out our CHASE recipe. A highly relevant problem given that most human-curated datasets are crushed within days.
Problems for Evaluation? 🤔 Check out our CHASE recipe. A highly relevant problem given that most human-curated datasets are crushed within days.

Presenting ✨ 𝐂𝐇𝐀𝐒𝐄: 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐧𝐠 𝐜𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐢𝐧𝐠 𝐬𝐲𝐧𝐭𝐡𝐞𝐭𝐢𝐜 𝐝𝐚𝐭𝐚 𝐟𝐨𝐫 𝐞𝐯𝐚𝐥𝐮𝐚𝐭𝐢𝐨𝐧 ✨
Work w/ fantastic advisors Dima Bahdanau and @sivareddyg.bsky.social
Thread 🧵:
Work w/ fantastic advisors Dima Bahdanau and @sivareddyg.bsky.social
Thread 🧵:
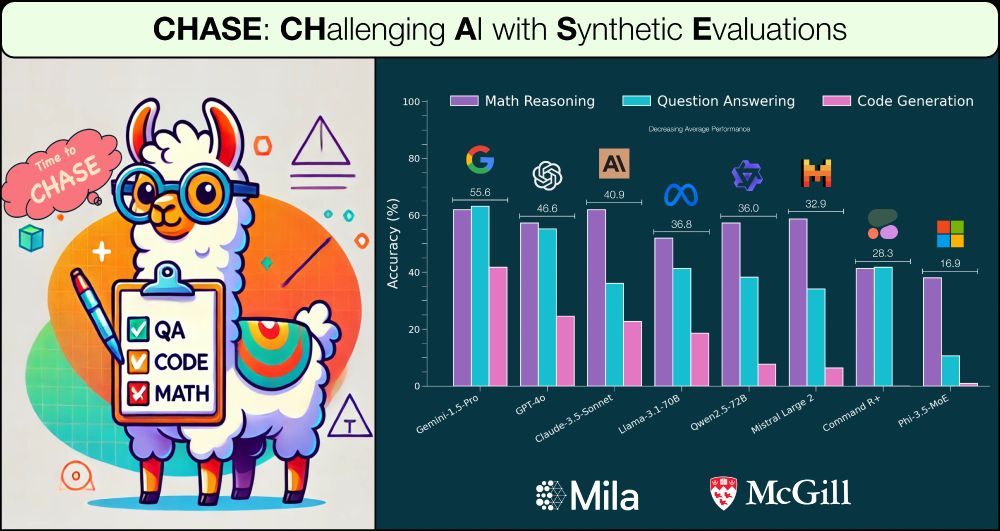
February 21, 2025 at 6:53 PM
How to Get Your LLM to Generate Challenging
Problems for Evaluation? 🤔 Check out our CHASE recipe. A highly relevant problem given that most human-curated datasets are crushed within days.
Problems for Evaluation? 🤔 Check out our CHASE recipe. A highly relevant problem given that most human-curated datasets are crushed within days.
Reposted by Siva Reddy
Finally it's handy that all my twitter posts got migrated here to bsky:
I'll be presenting AURORA at @neuripsconf.bsky.social on Wednesday!
Come by to discuss text-guided editing (and why imo it is more interesting than image generation), world modeling, evals and vision-and-language reasoning
I'll be presenting AURORA at @neuripsconf.bsky.social on Wednesday!
Come by to discuss text-guided editing (and why imo it is more interesting than image generation), world modeling, evals and vision-and-language reasoning
AURORA 🌌 is now accepted as a Spotlight at NeurIPS 🥂
We wondered if a model can do *controlled* video generation but in a *single* step?
So we built a dataset+model for “taking actions” on images via editing, or what you could call single-step controlled video gen
We wondered if a model can do *controlled* video generation but in a *single* step?
So we built a dataset+model for “taking actions” on images via editing, or what you could call single-step controlled video gen
Did you miss the recent Auroras? No problem! ✨🎆
Super excited to share AURORA, a *general* image editing model + high-quality data that improves where prev work fails the most:
Performing *action or movement* edits, i.e. a kind of world model setup
Insights/Details ⬇️
Super excited to share AURORA, a *general* image editing model + high-quality data that improves where prev work fails the most:
Performing *action or movement* edits, i.e. a kind of world model setup
Insights/Details ⬇️
December 8, 2024 at 6:13 PM
Finally it's handy that all my twitter posts got migrated here to bsky:
I'll be presenting AURORA at @neuripsconf.bsky.social on Wednesday!
Come by to discuss text-guided editing (and why imo it is more interesting than image generation), world modeling, evals and vision-and-language reasoning
I'll be presenting AURORA at @neuripsconf.bsky.social on Wednesday!
Come by to discuss text-guided editing (and why imo it is more interesting than image generation), world modeling, evals and vision-and-language reasoning
Congratulations
@andreasmadsen.bsky.social
on successfully defending your PhD ⚔️ 🎉🎉 Grateful to you for stretching my interests into interpretability and engaging me with exciting deas. Good luck with your mission on building faithfully interpretable models.
@andreasmadsen.bsky.social
on successfully defending your PhD ⚔️ 🎉🎉 Grateful to you for stretching my interests into interpretability and engaging me with exciting deas. Good luck with your mission on building faithfully interpretable models.

I’m thrilled to share that I’ve finished my Ph.D. at Mila and Polytechnique Montreal. For the last 4.5 years, I have worked on creating new faithfulness-centric paradigms for NLP Interpretability. Read my vision for the future of interpretability in our new position paper: arxiv.org/abs/2405.05386

Interpretability Needs a New Paradigm
Interpretability is the study of explaining models in understandable terms to humans. At present, interpretability is divided into two paradigms: the intrinsic paradigm, which believes that only model...
arxiv.org
November 29, 2024 at 6:25 PM
Congratulations
@andreasmadsen.bsky.social
on successfully defending your PhD ⚔️ 🎉🎉 Grateful to you for stretching my interests into interpretability and engaging me with exciting deas. Good luck with your mission on building faithfully interpretable models.
@andreasmadsen.bsky.social
on successfully defending your PhD ⚔️ 🎉🎉 Grateful to you for stretching my interests into interpretability and engaging me with exciting deas. Good luck with your mission on building faithfully interpretable models.
Reposted by Siva Reddy

“Turn” a decoder into an encoder with LLM2Vec (github.com/McGill-NLP/l...). Seen at COLM 2024 :)
If you want the naive, training-free / model-agnostic approach: their related work section says it is most common to using the final token’s last hidden state.
If you want the naive, training-free / model-agnostic approach: their related work section says it is most common to using the final token’s last hidden state.

GitHub - McGill-NLP/llm2vec: Code for 'LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders'
Code for 'LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders' - McGill-NLP/llm2vec
github.com
November 26, 2024 at 1:37 AM
“Turn” a decoder into an encoder with LLM2Vec (github.com/McGill-NLP/l...). Seen at COLM 2024 :)
If you want the naive, training-free / model-agnostic approach: their related work section says it is most common to using the final token’s last hidden state.
If you want the naive, training-free / model-agnostic approach: their related work section says it is most common to using the final token’s last hidden state.
Stages of #ICLR reviewing:
Stage 1: 😍 I hope I learn something new
Stage 2: 🤗 I hope I am constructive enough while being critical. Submits review
Stage 3: 🤯 Receives 5 page response + revision with many new pages
Stage 4: 😱 Crap, how do I get out of this?
Stage 5: 😵💫 What year is it?
Stage 1: 😍 I hope I learn something new
Stage 2: 🤗 I hope I am constructive enough while being critical. Submits review
Stage 3: 🤯 Receives 5 page response + revision with many new pages
Stage 4: 😱 Crap, how do I get out of this?
Stage 5: 😵💫 What year is it?
November 26, 2024 at 5:08 AM
Stages of #ICLR reviewing:
Stage 1: 😍 I hope I learn something new
Stage 2: 🤗 I hope I am constructive enough while being critical. Submits review
Stage 3: 🤯 Receives 5 page response + revision with many new pages
Stage 4: 😱 Crap, how do I get out of this?
Stage 5: 😵💫 What year is it?
Stage 1: 😍 I hope I learn something new
Stage 2: 🤗 I hope I am constructive enough while being critical. Submits review
Stage 3: 🤯 Receives 5 page response + revision with many new pages
Stage 4: 😱 Crap, how do I get out of this?
Stage 5: 😵💫 What year is it?
Reposted by Siva Reddy

I wrote some thoughts on how to build good LM benchmarks: ofir.io/How-to-Build...
How to Build Good Language Modeling Benchmarks
Building benchmarks is important because they shine a spotlight on the weaknesses of existing language models and so can guide the community on how to improve them.
ofir.io
November 25, 2024 at 9:54 PM
I wrote some thoughts on how to build good LM benchmarks: ofir.io/How-to-Build...
Reposted by Siva Reddy

@sivareddyg.bsky.social Which platforms? Maybe consider @buffer.com
November 24, 2024 at 1:40 AM
@sivareddyg.bsky.social Which platforms? Maybe consider @buffer.com
It's beautiful to start from scratch sometimes 😇
November 24, 2024 at 1:28 AM
It's beautiful to start from scratch sometimes 😇
Reposted by Siva Reddy

Creating a 🦋 starter pack for people working in IR/RAG: go.bsky.app/88ULgwY
I can’t seem to find everyone though, help definitely appreciated to fill this out (DM or comment)!
I can’t seem to find everyone though, help definitely appreciated to fill this out (DM or comment)!
November 23, 2024 at 9:19 PM
Creating a 🦋 starter pack for people working in IR/RAG: go.bsky.app/88ULgwY
I can’t seem to find everyone though, help definitely appreciated to fill this out (DM or comment)!
I can’t seem to find everyone though, help definitely appreciated to fill this out (DM or comment)!
I find it unintuitive that user handles have to be appended with bsky.social? Can we get rid of it?

Bluesky
Social media as it should be. Find your community among millions of users, unleash your creativity, and have some fun again.
bsky.social
November 23, 2024 at 4:50 PM
I find it unintuitive that user handles have to be appended with bsky.social? Can we get rid of it?
This space has good vibes and clear skies 🌞. Any tips on how to crosspost across platforms for the time being without manually copy pasting?
November 23, 2024 at 4:45 PM
This space has good vibes and clear skies 🌞. Any tips on how to crosspost across platforms for the time being without manually copy pasting?